🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
研究類型和社會統計的關係
行為科學和社會科學家為了發現真實,會運用各種不同的研究設計來回答他們擬定的研究問題。雖然科學研究有多種不同的設計,但最主要可區分為觀察研究(observational research)和真實驗研究(true experimental research)兩大類型,而不論哪一種研究類型,皆與社會統計有緊密的關係。
基本上,研究的流程為研究問題的提出、研究的設計、統計分析方法的選擇,然後研究的實地執行、研究資料的分析,最後為研究結果的討論。從這流程可以看出,研究人員須先決定研究類型後,才能選擇統計分析的方法。
由於研究類型和社會統計的關係很密切,所以在統計分析方法的學習前,須先認識研究的類型。下面內容將以觀察研究和真實驗研究兩大研究類型為方向,簡單地說明兩種研究類型的差異、各自包含的研究設計和相關的統計分析方法。
觀察研究
觀察研究是指研究人員沒有操控任何的變項,而是藉由自然發生現象的觀察來檢驗研究假設。由此可見,觀察研究是無法做出因果關係結論的研究。觀察研究包含描述性研究、相關研究和原樣團體(群組)比較等不同的研究設計,下面逐一來探討。
描述性研究
描述性研究(descriptive research)是針對特定的研究問題,單純地進行資訊的蒐集,好讓研究人員能夠對研究問題做出正確的描述。例如:一位高中老師想瞭解某一次數學期末考80分以上的高三生人數,一位立委參選人想知道自己在某個選區的民眾支持度,一位社會工作者想瞭解某一年臺灣各縣市親密伴侶暴力占所有家庭暴力案件的比率。
描述性研究通常會從母群體中抽取出樣本,再透過問卷、電話、訪談等方法,進行資料的蒐集。資料蒐集完成後,再利用樣本所獲得的資訊去推估母群體的特性(這過程稱為參數估計),常見的問卷訪談、民意調查或市場調查都屬於這類型的研究。
在描述性研究裡,通常會利用次數分配、分組分數次數分配、集中趨勢測量以及變異性測量等描述統計分析方法來瞭解樣本的特性。不過,單一的統計量本身並沒有太大的意義,而是須透過統計量在不同時間點或不同群組之間的比較,才能賦予它更多的意義。
舉例來說,一位社會工作者利用衛生福利部統計處的資料發現2022年親密伴侶暴力占所有家庭暴力案件的47.8%,但單從這百分比很難判斷親密伴侶暴力到底是多還是少。如果這位社會工作者進一步計算其他家庭暴力類型所占的比率,發現兒童虐待占16.1%、尊親屬虐待占14%、其他家庭成員間虐待占22.1%,則透過不同虐待類型占所有家庭暴力案件百分比的比較,就可得到2022年家庭暴力案件裡親密伴侶暴力的比率最高的結論。
因為描述性研究是單純地藉由資料的蒐集,嘗試對研究問題或現象做出正確、完整的描述,研究過程中並沒有涉及任何變項的操控,所以不會也不可能有因果關係的結論。描述性研究通常為個別變項的描述,例如成績的分散程度、平均年齡、各種職業的比率,若想探討兩個或兩個以上變項間的關係,則須採用相關研究。
相關研究
相關研究(correlational research)是用來瞭解兩個或兩個以上變項間關聯性的一種研究,由於這種研究也是針對自然發生的現象或已存在的事實進行資料的蒐集,並沒有涉及任何變項的操控,所以屬於觀察研究的一種。例如:一位大學老師想瞭解學生每週的社會統計讀書時間和期末考成績之間的關聯,一位營養師想探討每日糖分的攝取量和肥胖之間的關聯。
在相關研究裡,研究人員從母群體中抽取樣本,藉由問卷、訪談或觀察等方式,取得每一研究參與者、事物或事件與研究問題相關的兩個或兩個以上的變項測量。這些研究資料可在同一個時間點全部取得(例如透過一份問卷的填寫獲得所有的資訊)或在不同的時間點進行測量(例如每週記錄河川的汙染指數和生存的魚種類數目),資料蒐集完成後再分析變項的數值或測量之間是否呈現系統性的變化。
由於相關研究不會牽涉到任何變項測量的操控,所以研究人員能夠獲得研究問題相關的真實存在情況。一般來說,這種類的研究會運用相關分析的統計分析方法來探討變項之間的關聯強度和方向,例如皮爾森積差相關係數、斯皮爾曼等級相關係數。除了相關分析之外,若想進一步利用一個變項的數值來預測另一個變項的數值,則可藉由最小平方迴歸線的建構來達成。
相關研究能夠探討兩個或兩個以上變項間是否存在系統性的變化,也就是當一個變項的數值增加或減少的時候,另一個變項的數值是否也隨著增加或減少。即便變項之間存在很強的關聯性,因為相關研究的過程沒有涉及任何變項的操控,所以也無法做出因果關係的結論。
原樣團體或群組比較研究
原樣團體或群組(intact groups)的比較是依據研究開始前即已存在的個人特質,也就是受試者變項,來進行群組間比較的一種研究。例如:一位國中老師想探討女學生和男學生在國文成績上的差異,一位精神科醫生想瞭解有睡眠障礙的個案和沒有睡眠障礙的個案在憂鬱症狀上的差異,一位醫生想瞭解懷孕期間抽菸女性和沒有抽菸女性所生嬰兒的體重差異。
原樣團體或群組比較可用來探討一個群組變項和其他變項之間的關係,而這個群組變項是在研究開始前就已經存在的個人特質或事實,例如上面提到的學生生理性別、個案睡眠障礙的有無、女性懷孕期間的抽菸與否,使得研究參與者可依照這個特質或事實被分類。當研究參與者被劃分為不同的群組或團體後,即可透過統計分析來調查群組間是否存在差異。
多種不同的統計分析方法可運用在這類型的研究上,舉例來說,若只想瞭解兩個群組或團體和另一個變項之間的關聯性,可以使用點二系列相關係數、phi係數等相關分析。如果想檢驗兩個群組的平均數是否有差異,可以使用平均數比較方法的獨立樣本t檢定;若想檢驗3個或3個以上群組的平均數差異,則可以使用單因子變異數分析。
雖然原樣團體或群組比較的研究能夠探討兩個或兩個以上群組的不同,但和描述性研究、相關研究一樣,無法做出因果關係的結論。原樣團體或群組的存在是因為研究參與者本身已存在的特質或事實,而不是透過研究人員的隨機分配。因此,研究結果充其量僅能顯示團體或群組間在依變項上是否存在差異,而無法指出群組本身導致了依變項的不同,因為依變項的不同可能是群組本身或其他因素所造成。
原樣團體或群組比較研究的群組來源和下面要說明的真實驗研究的群組來源有明顯的不同,而這一點也是造成原樣團體或群組比較研究無法做出因果關係結論但真實驗研究卻可以的主要原因,下面就來看看真實驗研究的研究設計。
真實驗研究
真實驗研究是一種能夠做出因果關係結論的研究設計,也就是可用來評估一個變項數值的改變是否「導致」另一個變項數值的改變。在上面提到的原樣團體或群組比較的研究裡,群組的類別是由原本即已存在的個人特質或事實而來;但在真實驗研究裡,群組的類別則是透過研究人員的操控而來。
基本上,真實驗研究會具備3個要素,分別為自變項、依變項和多餘變項(nuisance variable),這3個變項的意義分別如下:
- 自變項:研究人員可以操控的變項,例如課程的種類、藥劑的劑量、治療的方法。研究過程中很常聽到實驗組和控制組這兩個名稱,即是研究人員操控的兩種不同的實驗情境,也就是自變項。
- 依變項:在自變項的操作下,研究人員從研究參與者身上得到的測量數值,例如測驗的成績、病痛的程度、憂鬱症量表的分數。
- 多餘變項:會影響自變項效果評估的外擾變項(extraneous variable),在研究執行的過程中,研究人員會儘量控制這種變項的產生,嘗試將其影響程度降到最低。
真實驗研究的研究問題通常為「自變項會對依變項產生什麼樣的效果?」。在研究執行時,會先從母群體中隨機抽取出一組樣本,然後將樣本裡的研究參與者隨機分配至不同的實驗情境,並開始各種實驗情境的實行。實驗情境結束後,研究人員利用測量工具蒐集資料,最後再進行資料整理與分析。
舉例來說,有位研究人員想探討宣導短片的呈現形式對小學三年級學生身體虐待認識的效果,她從一所小學裡隨機抽取出30位三年級的學生,然後將10位學生分配到真人版宣導短片組、10位學生到動畫版宣導短片組、10位學生到沒有任何宣導短片的控制組。宣導結束後,她請每位小學生填寫一份身體虐待相關的問卷,並記錄每一位學生的成績。
在上面的例子裡,自變項為宣導短片的呈現形式,依變項為學生的問卷成績。若和沒有宣導短片的控制組相比較,真人版宣導短片組和動畫版宣導短片組的學生問卷成績有所不同的話,研究人員即可指出宣導短片的呈現形式「導致」了成績的不同,也就是宣導短片帶有讓小學三年級生認識身體虐待的效果。
真實驗研究的資料通常可利用群組差異比較的統計檢定方法來進行分析,若比較的群組為兩組,可以使用獨立樣本t檢定、曼-惠特尼U檢定等兩組獨立樣本比較的統計分析;若比較的群組為3組或3組以上,可以使用單因子變異數分析、Kruskal-Wallis檢定等3組或3組以上獨立樣本比較的統計分析。
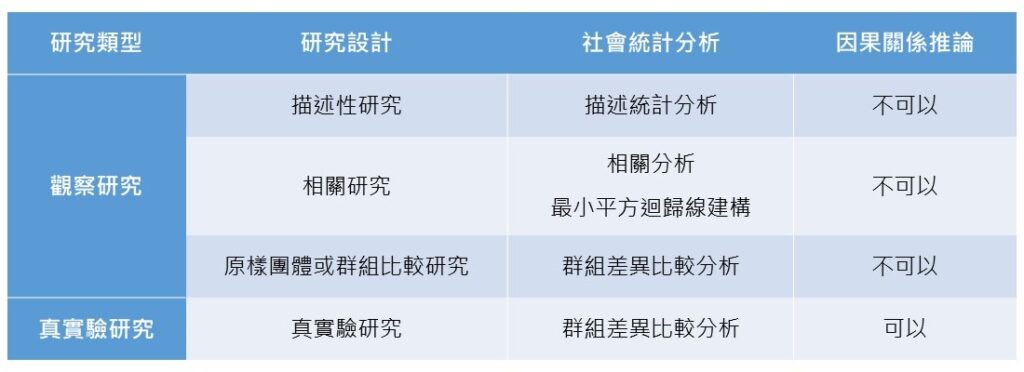
總結來說,若從研究結果是否能做出因果關係推論的角度來看,研究類型可區分為觀察研究和真實驗研究。觀察研究又可再依據研究目的和研究問題而有不同的研究設計,每一種研究設計的主要社會統計分析方法也有不同。真實驗研究則因為嚴謹的研究設計,使得這種研究能做出因果關係的結論。各種不同的研究設計、社會統計分析方法和因果關係推論之可能性可用下表來呈現:
統計分析的方法有很多種,而且持續發展中。不過統計分析的運用之前,須有研究的設計,而研究設計的好壞攸關著整個研究結果的可信度。即使有再厲害的統計分析技巧,也無法挽救設計不佳的研究。因此,社會統計分析技巧的學習固然重要,但研究設計的認識和熟習更是社會統計學習的一個必要基礎喔!
以上為本篇文章對研究類型和社會統計關係的介紹,希望透過本篇文章,您瞭解了研究的兩大類型,以及各個類型涵蓋的研究設計和相對應的社會統計分析方法。
若您喜歡本篇文章,請將本網站加入書籤,作為您的學習資源,並持續回訪本網站喔!另外,您也可以在Facebook和Twitter上找到我們喲!