🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
最小平方迴歸線的預測區間計算
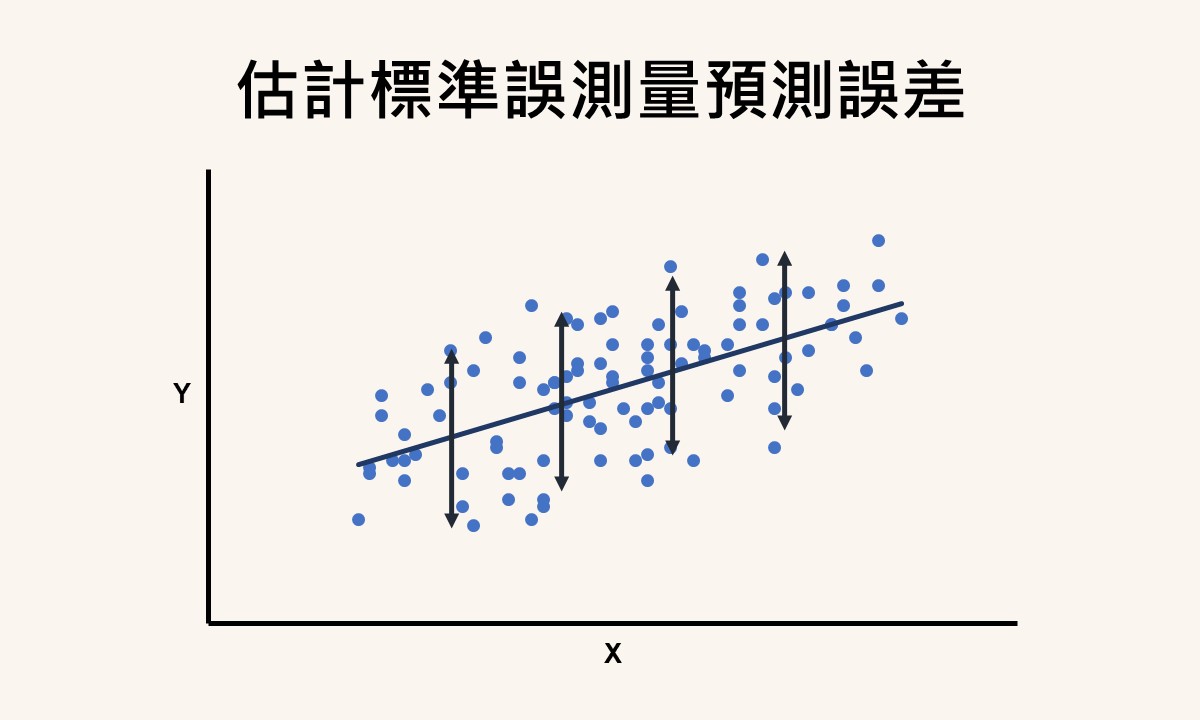
當兩個變項間存在不完全的線性關係,且想利用其中一個變項來預測另一個變項的數值時,可以建構一條最小平方迴歸線(least-squares regression line)。為了瞭解這條迴歸線的預測程度,可以再透過估計標準誤(standard error of estimate)來測量預測誤差,當估計標準誤的數值愈小時,代表預測的準確度愈好。
雖然估計標準誤可以作為整體預測誤差的測量,卻不適合作為個別預測的誤差測量值。若想利用最小平方迴歸線來預測某一個自變項數值的依變項結果,會因為這個自變項數值與自變項平均數間的距離而有不同的誤差估計值,當數值愈靠近平均數時,誤差估計值會愈小。因此,計算個別自變項數值的預測區間時,須考量該值與自變項平均數的距離來計算個別預測的標準誤。
下面將先回顧估計標準誤的意義,再探討個別預測的標準誤以及預測區間的計算方法,然後舉一例子說明預測區間的計算過程,最後示範如何利用SPSS取得預測區間。由於本篇文章內容為最小平方迴歸線和估計標準誤的延伸,建議您先閱讀最小平方迴歸線的建構和計算、估計標準誤測量預測誤差,將有助於下面內容的理解。
估計標準誤的簡單回顧
當兩變項間為不完全的線性關係時,若想藉由其中的一個變項(自變項)來估計另一個變項(依變項)的數值,可在兩者之間建構出一條最小平方迴歸線。不過兩變項間畢竟不是完全關係,無法做完美的預測,所以會產生預測誤差,此時可透過估計標準誤來瞭解預測誤差的大小。若想瞭解更多變項間關係的型態,請參考變項之間關係的基本特色。
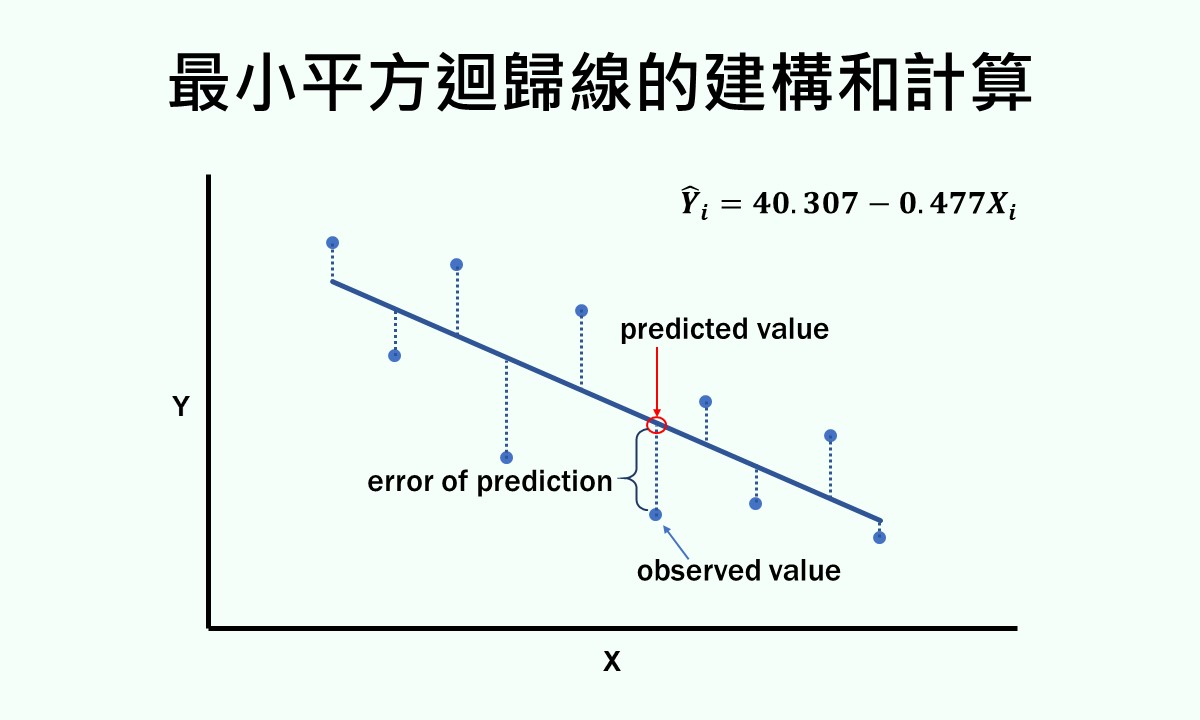
如果觀察值(也就是原始資料)為 ,利用最小平方迴歸線來進行估計而得到的預測值為
,利用最小平方迴歸線來進行估計而得到的預測值為 ,觀察值和預測值之間的距離(
,觀察值和預測值之間的距離( )即為預測誤差。每一個觀察值都可透過最小平方迴歸線來計算出落在線上的預測值,下圖中的藍色虛線就是每一個觀察值的預測誤差。
)即為預測誤差。每一個觀察值都可透過最小平方迴歸線來計算出落在線上的預測值,下圖中的藍色虛線就是每一個觀察值的預測誤差。
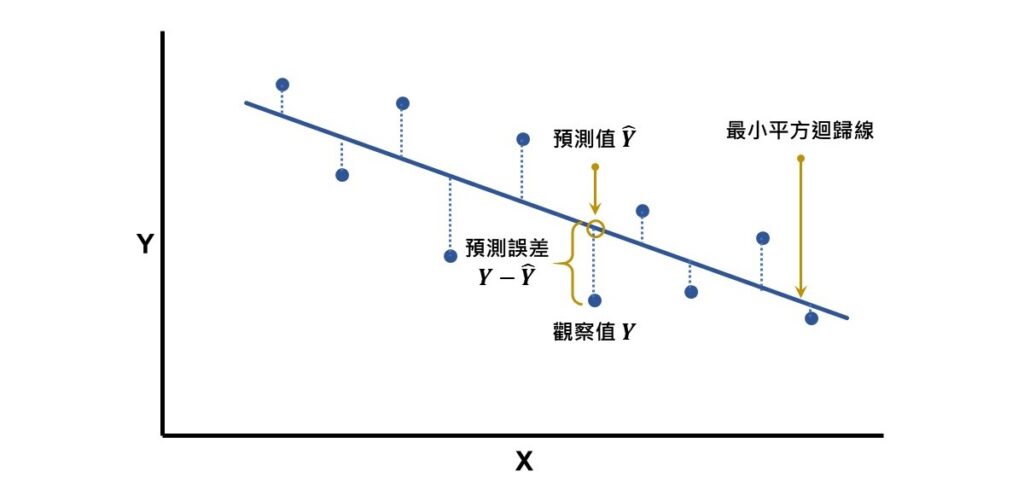
因為每一個觀察值都存在預測誤差,所以估計標準誤就是平均的預測誤差。但是預測誤差可能為正數也可能為負數,因此所有的預測誤差相加後會等於0。為了避免正負相抵的情況,會先把每一個預測誤差平方後再相加,然後除以 後再開根號。運用這概念,估計標準誤的公式如下:
後再開根號。運用這概念,估計標準誤的公式如下:
(1) 

因為最小平方迴歸線建構時,截距和斜率的計算分別失去1個自由度(degrees of freedom,簡寫為df),共失去2個自由度,所以估計標準誤公式的分母為而不是 。此外,預測誤差平方和
。此外,預測誤差平方和 代表不可被解釋的變異(unexplained variation),也就是利用自變項來預測依變項後依舊無法被解釋的變異,通常用
代表不可被解釋的變異(unexplained variation),也就是利用自變項來預測依變項後依舊無法被解釋的變異,通常用 來表示。因此,估計標準誤還可以用下列公式來表示:
來表示。因此,估計標準誤還可以用下列公式來表示:

當估計標準誤的數值愈大,代表最小平方迴歸線的預測誤差愈大,預測愈沒有信心;反之,當數值愈小,代表預測誤差愈小,預測的準確度就愈高。
最小平方迴歸線的預測區間計算
最小平方迴歸線的一個最主要用途就是「預測」,通常用來預測某個不在樣本裡的自變項數值的依變項結果。雖然利用迴歸線可以得到單一的依變項預測值,但這預測值實際上是平均的預測結果。既然是平均的預測結果,就會存在變異,因此可以像信賴區間那樣計算出預測區間。兩者的差別在於信賴區間是估計母群體平均數的上、下界限,而預測區間是預測個別數值的依變項結果的上、下界限。
預算區間的計算須考量到變異,估計標準誤雖然是整體預測誤差的一個合適估計值,卻不適合作為個別預測的誤差估計值。假設自變項為X、依變項為Y,當利用最小平方迴歸線預測某一個不在樣本裡的X值的Y值結果時,預測誤差會隨著X值和X平均數間的距離而有不同的變化。若X值愈靠近X平均數,預測誤差會愈小;若X值愈遠離X平均數,預測誤差會愈大。
由於個別預測值會隨著其與平均數之間的距離而有不同的誤差估計值,所以若想利用最小平方迴歸線來估計不在樣本裡的單一自變項數值的預測區間(prediction intervals)時,須使用下面的標準誤公式:
(2) 

然後再利用公式(2)的標準誤來求得X變項數值的預測區間,計算方式類似於小樣本或σ未知的信賴區間之計算,須使用到t分配和t值,計算公式如下:
(3) 

透過上述的過程,可以計算出某一個自變項數值的依變項預測區間,也就是可能包含依變項結果的數值範圍。若有數個自變項數值的依變項預測區間資料,可以繪出如下圖的預測區間上限和下限2條線,分別落在最小平方迴歸線的上面和下面。當想探討的自變項數值離自變項平均數較近的時候,依變項的預測區間會比較窄,但當想探討的自變項數值離平均數較遠的時候,預測區間則變得比較寬。
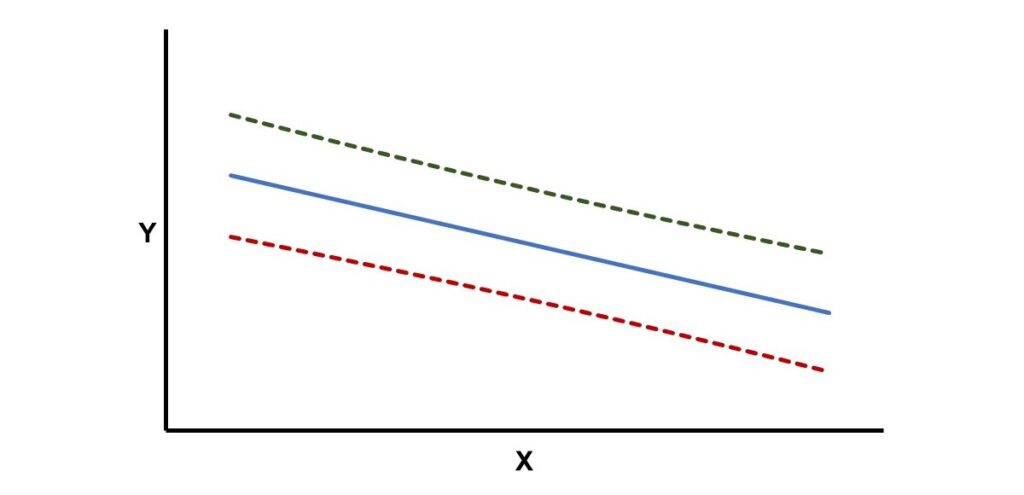
這裡所討論的預測區間和最小平方迴歸線本身的信賴區間(confidence intervals)並不一樣,預測區間是用來預測不在樣本裡的自變項數值的可能依變項範圍,而最小平方迴歸線的信賴區間則是母群體裡真實的最小平方迴歸線的可能存在範圍。因為預測不在樣本裡的自變項數值時,不但要考量最小平方迴歸線本身的變異,也要考量預測時會產生的不確定性,所以預測區間的範圍會大於信賴區間的範圍。
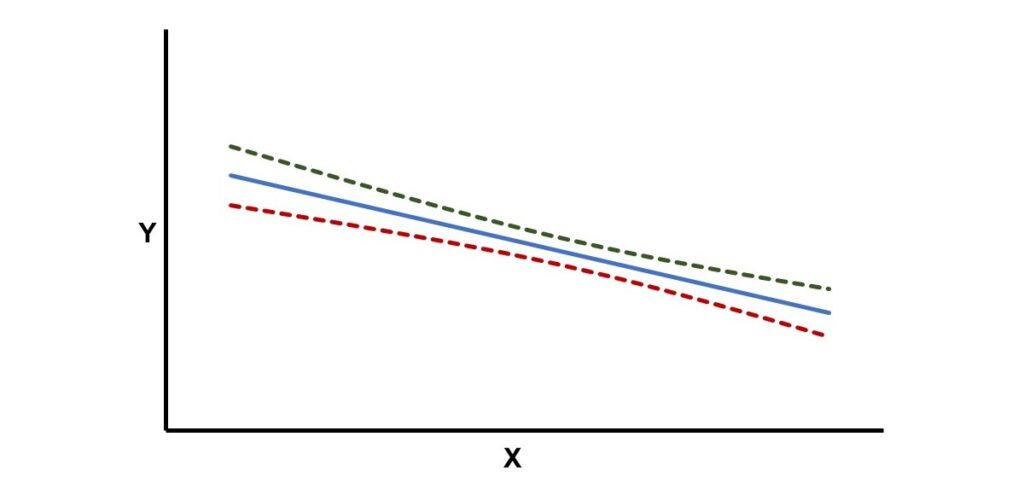
上圖為圍繞著最小平方迴歸線的信賴區間,代表母群體裡真實的最小平方迴歸線可能落在這區間裡。若和上面的預測區間圖相比較,可以看出信賴區間的範圍明顯地小於預測區間。下面舉個例子來說明最小平方迴歸線的預測區間的計算過程。
最小平方迴歸線的預測區間例子
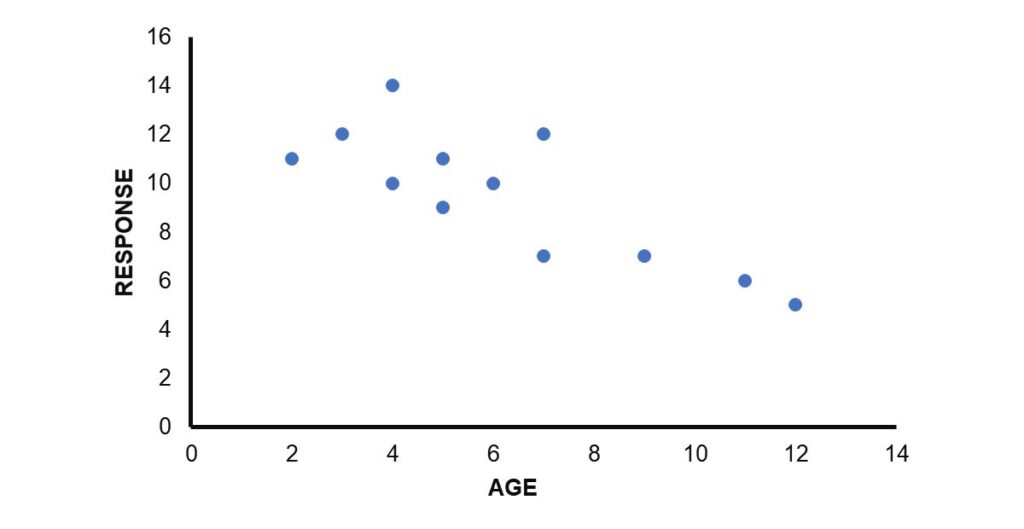
假設有一位研究人員想探討孩童在問題解決的回應上,是否會隨著年齡的增長而減少與問題解決不相關的回應。她蒐集了12位孩童的資料,分別記錄了他們的年齡和不相關的回應次數,如下表所示。若年齡為自變項,變項名稱為AGE,回應次數為依變項,變項名稱為RESPONSE,試問一位10歲孩童在問題解決時不相關回應的95%預測區間為何?

為了瞭解孩童年齡和問題解決時不相關回應次數之間的關係,可以把年齡置於橫座標軸,回應次數置於縱座標軸,先繪製一個如下的散布圖。從下圖可以看出,當孩童年齡增加的時候,不相關的回應次數有減少的趨勢,兩者之間呈現一個負向的、不完全的線性關係。關於散布圖的繪製方法,請參考如何繪製散布圖。
由於孩童年齡和問題解決時不相關的回應次數間為不完全的線性關係,為了用年齡來預測不相關的回應次數,可以建構一條最小平方迴歸線,這條迴歸線的方程式和估計標準誤分別為:

斜率-0.72代表當孩童年齡增加1歲的時候,不相關的回應次數會減少0.72次,可以看出兩變項之間為負向的關係,如同上面散布圖呈現出來的趨勢。關於最小平方迴歸線方程式的計算,請參考最小平方迴歸線的建構和計算;估計標準誤的計算,請參考估計標準誤測量預測誤差。
因為想求得10歲孩童的不相關回應次數的預測區間,所以要使用上面的公式(2)來計算個別預測所需的標準誤,把套用公式(2)時需要的數值在如下的表格裡先計算出來:
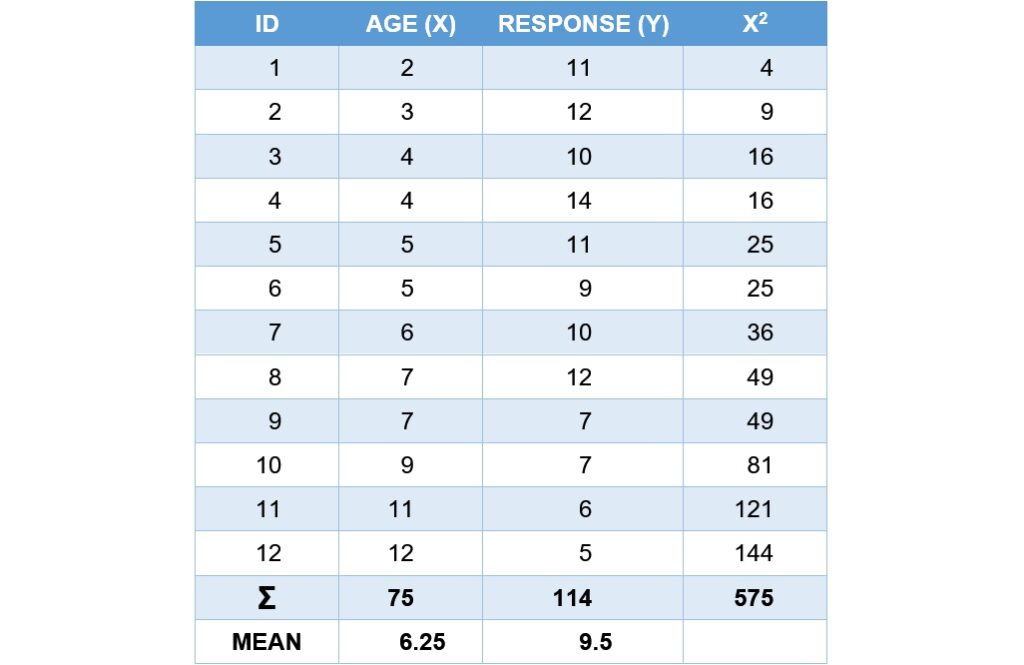
公式(2)裡的 指X變項(AGE)的離差平方和,讓
指X變項(AGE)的離差平方和,讓 簡化為
簡化為 ,的計算方法如下。如果不熟悉數學的基本符合和運算,請參考社會統計常用的基本數學符號和運算。
,的計算方法如下。如果不熟悉數學的基本符合和運算,請參考社會統計常用的基本數學符號和運算。

把 、
、 、
、 、和
、和 的數值帶入公式(2)裡,求得個別預測的標準誤
的數值帶入公式(2)裡,求得個別預測的標準誤 ,計算過程如下:
,計算過程如下:

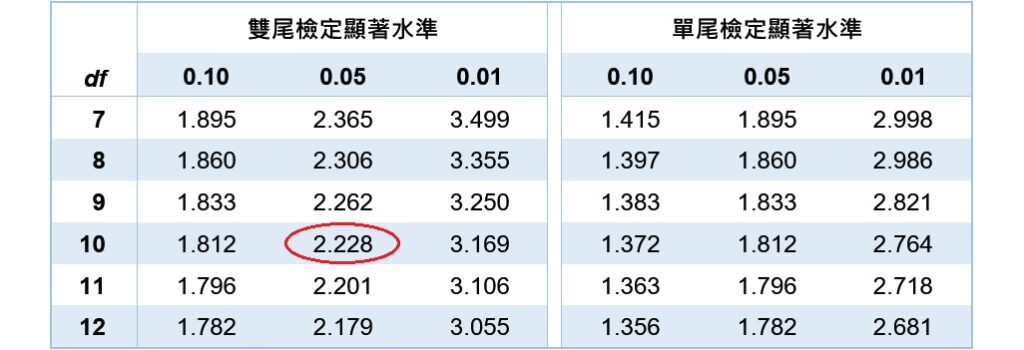
然後利用上面的公式(3)來計算10歲孩童的不相關回應的預測區間,因為公式(3)須使用到t的臨界值,所以查詢t分配表。當雙尾檢定、自由度為10()、顯著水準為0.05( 預測區間)時,t臨界值為2.228。
預測區間)時,t臨界值為2.228。
再利用孩童年齡和不相關的回應次數所建構出來的最小平方迴歸線來計算10歲孩童()的不相關回應次數的預測值,計算過程為:

最後把、t臨界值和個別預測的標準誤帶入公式(3),計算10歲孩童的不相關回應的預測區間,過程如下:

計算結果顯示有0.95的機率,一位10歲孩童在問題解決時會出現2.696次到10.904次的不相關回應,預測區間可說是相當地大。不過這一連串的計算過程非常地麻煩,這裡為了說明方便所以使用紙筆計算,但通常會使用統計分析軟體來取得分析結果,下面示範運用SPSS求得預測區間的操作方法。
運用SPSS取得最小平方迴歸線的預測區間
將上面例子裡12位孩童的資料輸入至SPSS的資料編輯器裡,同時多增加一筆資料,讓年齡的數值為10,不相關的回應次數則空白(遺漏值)。因為有遺漏值的存在,所以SPSS不會把這筆新增的資料作為最小平方迴歸線建構的資料,不過在要求軟體輸出預測區間時,則會運用已建構出的迴歸線來進行運算。關於SPSS的資料輸入方法,請參考SPSS操作環境和資料輸入。
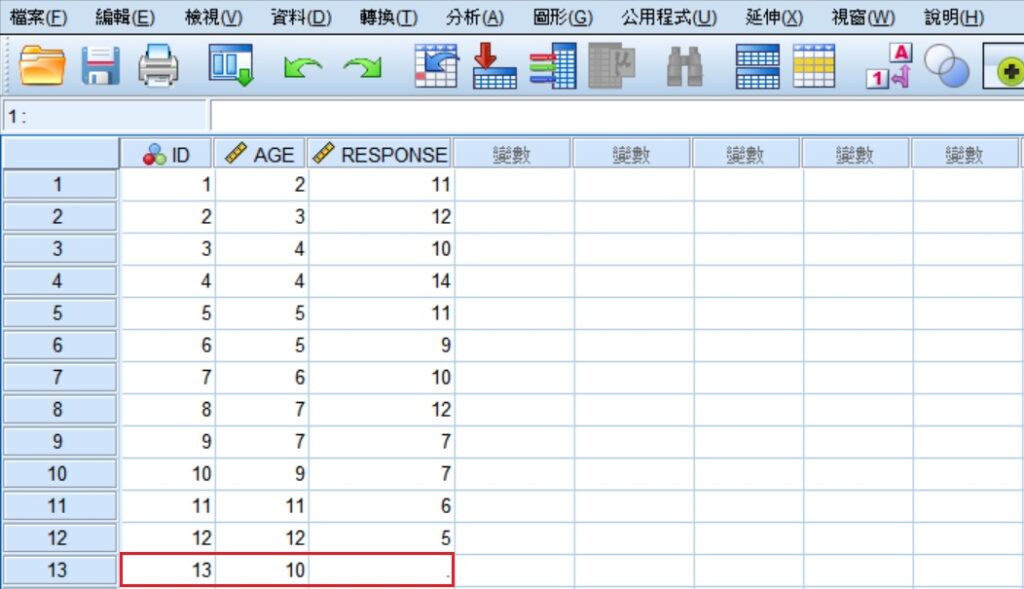
所有的資料輸入完成後,點選功能表的分析 » 迴歸 » 線性,帶出「線性迴歸」視窗。
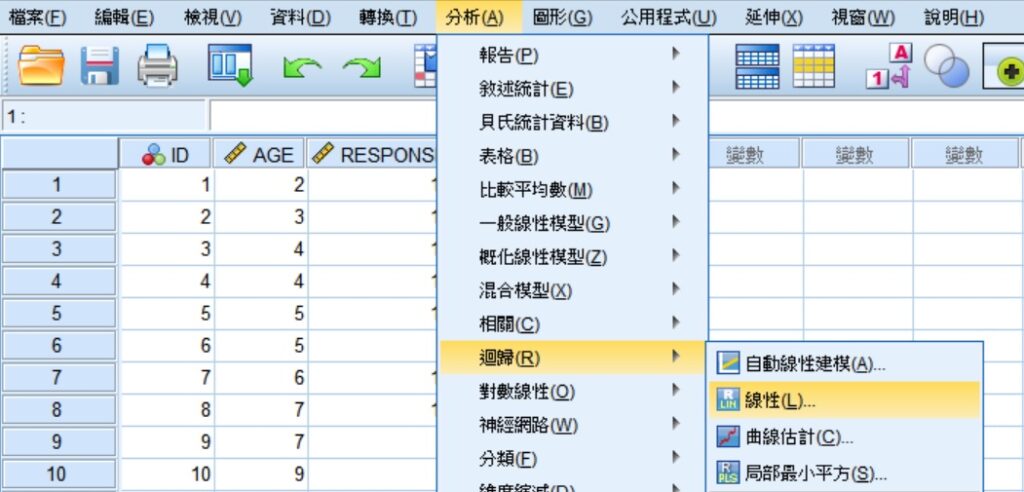
在「線性迴歸」視窗裡,將自變項AGE移至自變數(I),依變項RESPONSE移至應變數(D),然後點選視窗右側的儲存(S)。在「線性迴歸:儲存」視窗裡,勾選預測值裡的未標準化(U)和預測區間裡的個別(I),信賴區間(C)的預設值為95%,若是其他的數值可在這裡進行修改。完成後,按下這視窗最下方的繼續(C),回到上一個視窗後再按下確定。
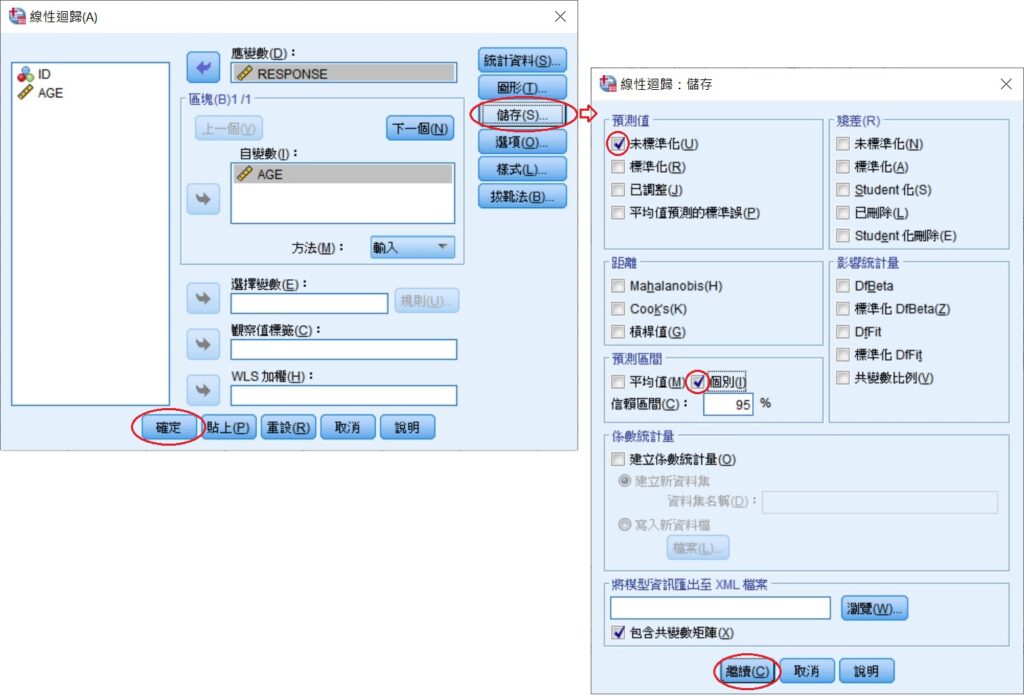
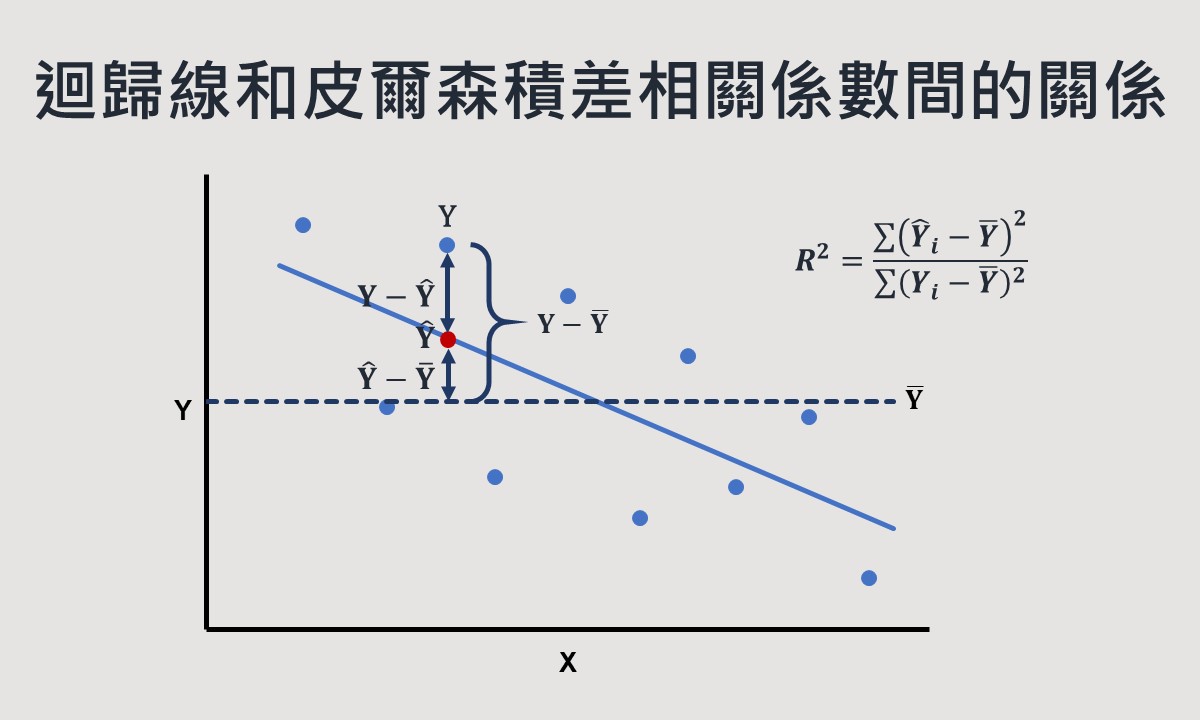
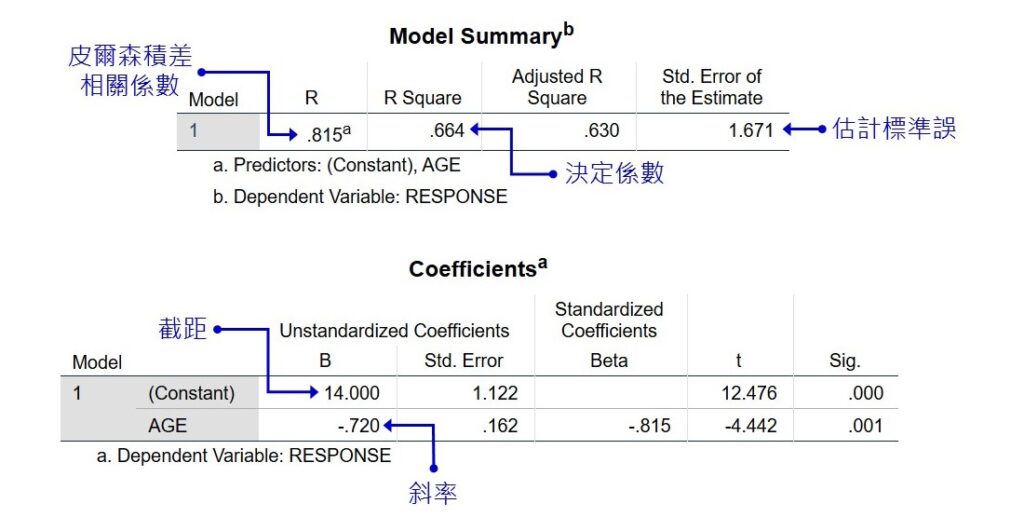
經過上述的步驟後,SPSS輸出的分析結果會有如下的「模型摘要」和「係數」表格。從「模型摘要」表裡,可以看到皮爾森積差相關係數(這個相關係數是從R平方開根號而來,因此永遠是正數,無法顯示兩變項關聯的方向性)和估計標準誤等資訊,「係數」表格則可看到最小平方迴歸線的截距和斜率等數值。
預測區間的結果會出現在資料編輯器裡,除了原本的變項資料之外,還多了3個變項,分別為利用最小平方迴歸線計算出來的各個觀察值的預測值(PRE_1)、預測區間的下限(LICI_1)和預測區間的上限(UICI_1),而最後一筆資料即為10歲孩童的預測區間結果。
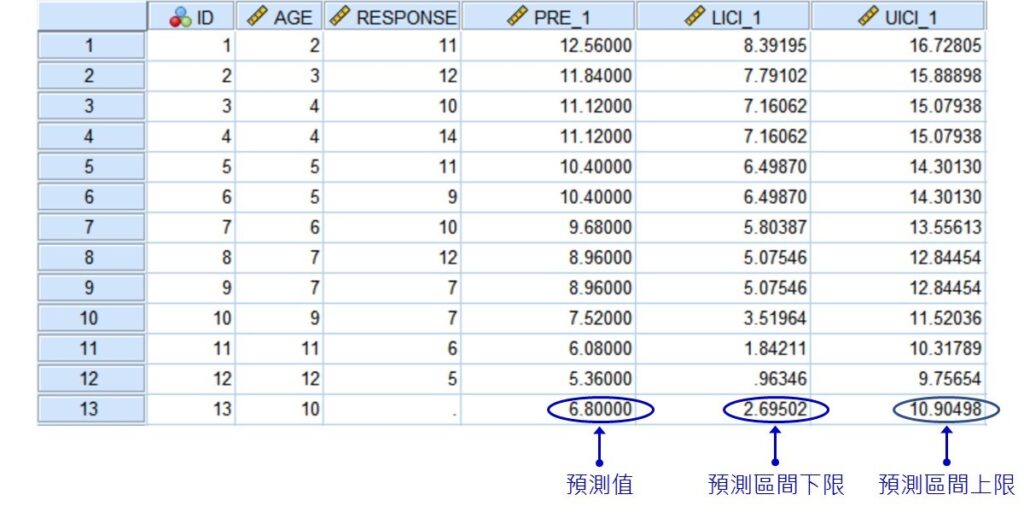
從上圖的資料可以看到,透過最小平方迴歸線的預測,10歲孩童在問題解決時會有6.8次的不相關回應,而有0.95的機率不相關回應會介於2.695次和10.905次之間。預測區間的結果和上面紙筆計算的結果有0.001的差距,但這是進位誤差所導致,並非紙筆計算的結果有誤喔!
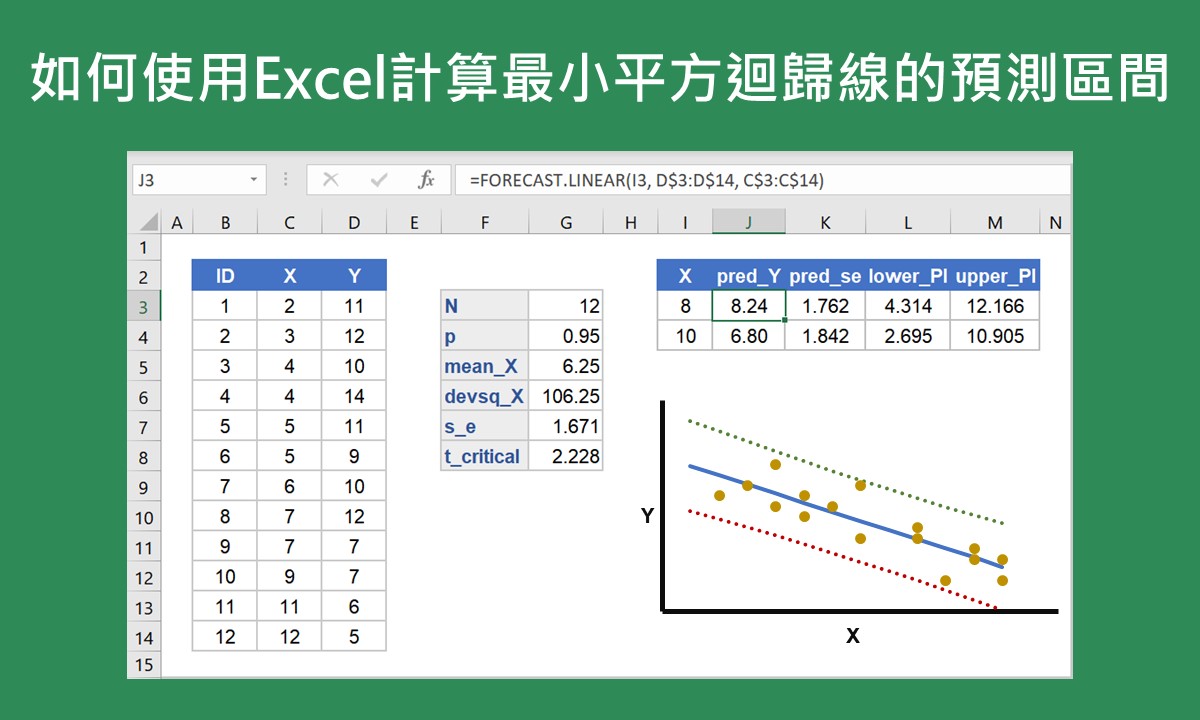
如果沒有統計分析軟體如SPSS,也可以使用微軟的Excel來計算最小平方迴歸線的預測區間,雖然計算過程中牽涉到許多函數的運用,但在沒有統計分析軟體的情況下,不失為一個好的方法,詳細的操作方法請參考如何使用Excel計算最小平方迴歸線的預測區間。
以上為本篇文章對最小平方迴歸線的預測區間之介紹,希望透過本篇文章,您瞭解了預測區間的用途和計算,也學會了利用SPSS取得預測區間的操作方法。若您喜歡本篇文章,請將本網站加入書籤,並持續回訪本網站喔!另外,也歡迎您追蹤本網站的Facebook和/或Twitter專頁喲!
如果您覺得本篇文章對您有幫助,歡迎買杯珍奶給 Dr. Fish!小小珍奶,大大鼓勵,您的支持將給Dr. Fish更多撰寫優質文章的動力喔!