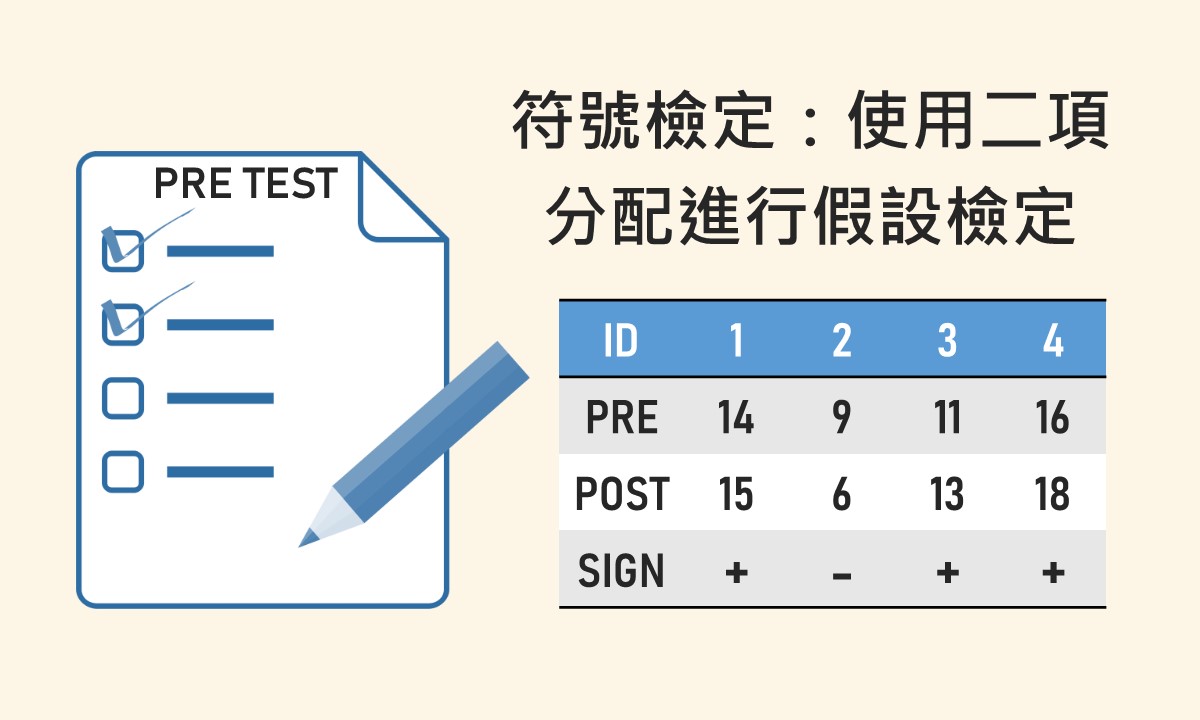
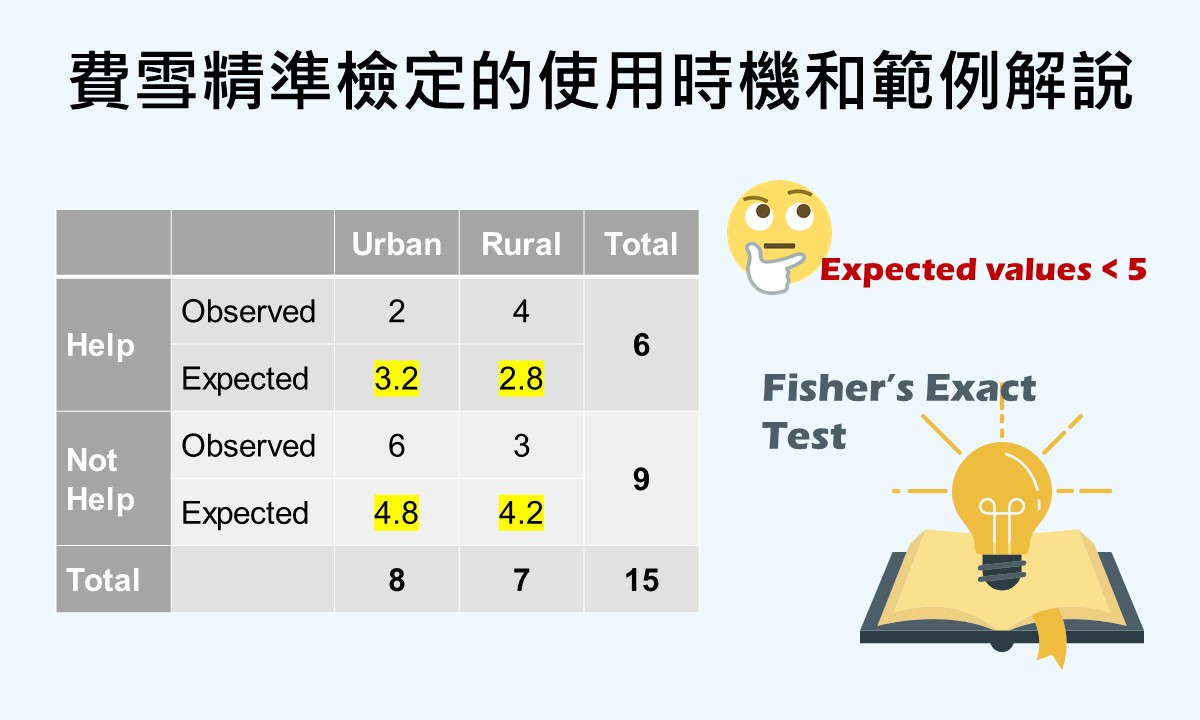
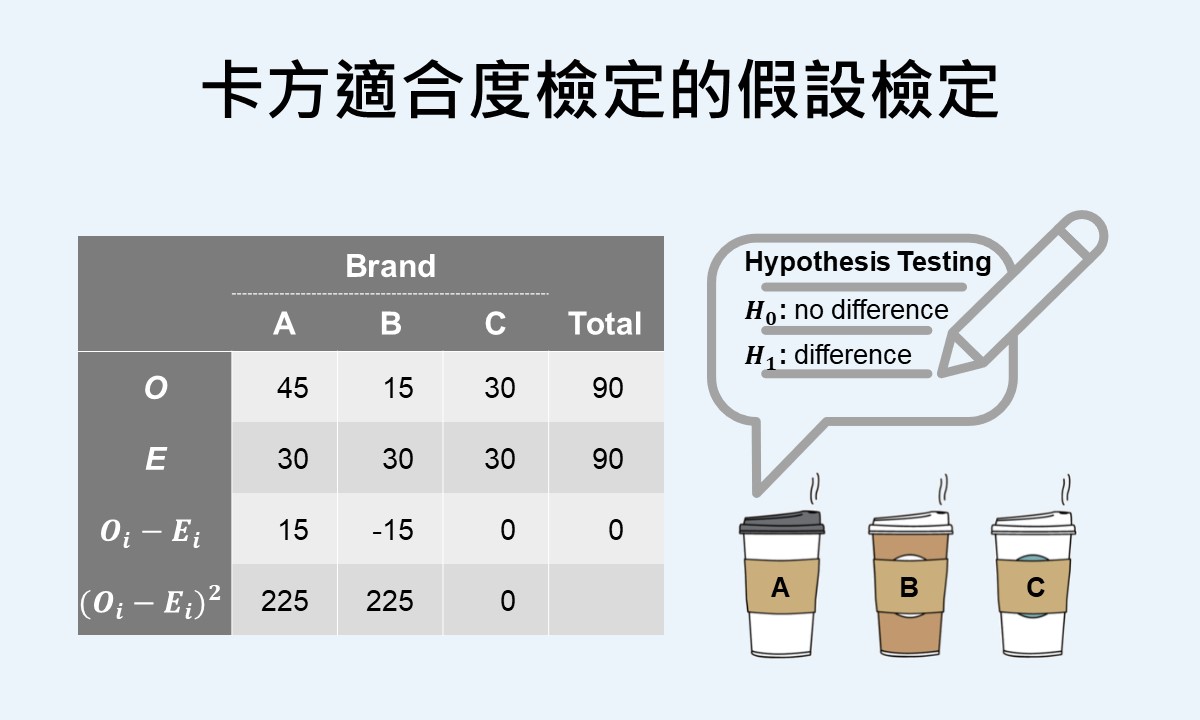
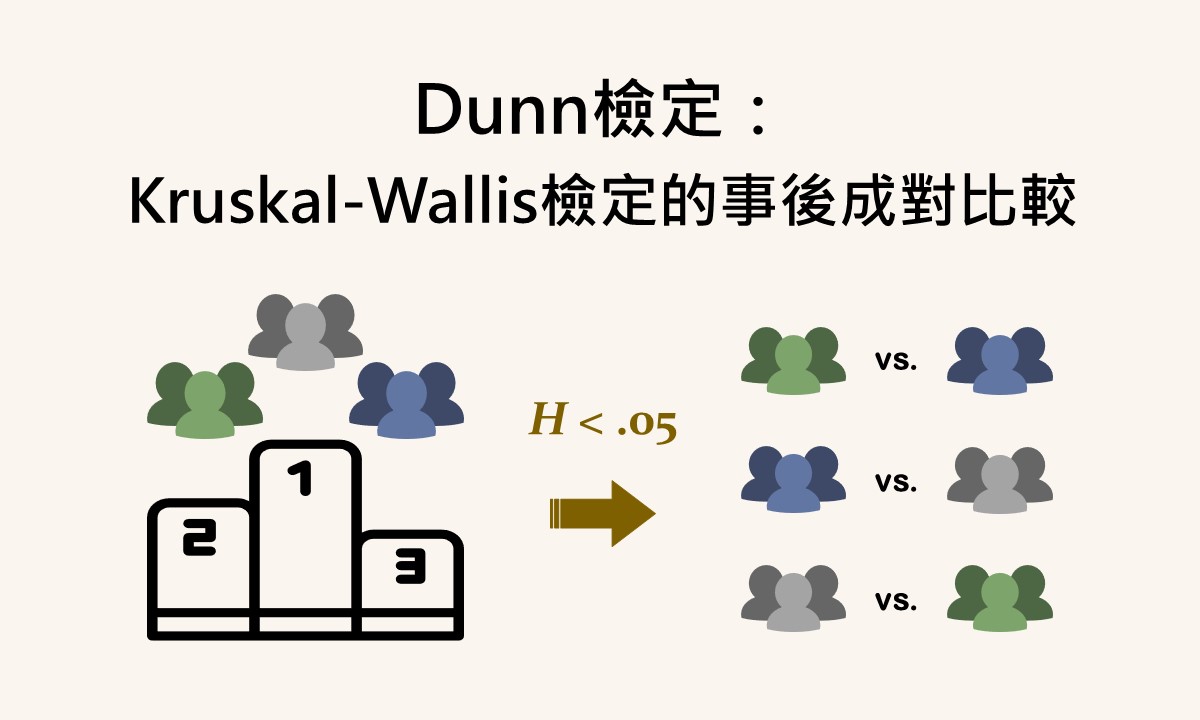
🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
曼–惠特尼U檢定的假設檢定
曼–惠特尼U檢定(Mann-Whitney U test)是用來探討兩個獨立的群體或樣本是否有所不同且變項資料至少為次序尺度的一種無母數檢定,而曼–惠特尼U檢定的假設檢定即在檢驗兩個獨立的群體或樣本是否來自於極為相似的母群體之虛無假設。
曼–惠特尼U檢定是獨立樣本t檢定的一種替代檢定方法,用在資料為次序尺度或獨立樣本t檢定的基本假設受到嚴重違反的時候。透過數值等級的比較,評估兩個群體或樣本是否有顯著的差異。雖然曼–惠特尼U檢定是一種無母數檢定,但因為使用了資料裡多數的量化訊息,所以是一種頗受歡迎的統計檢定方法。
由於本篇文章內容涉及假設檢定的過程,若您不清楚或尚未熟悉假設檢定的意義和步驟,建議您先閱讀假設檢定的步驟和範例,將有助於以下內容的理解。
下面將先介紹曼–惠特尼U檢定的使用時機,再使用例子說明曼–惠特尼U檢定的假設檢定過程,最後示範利用SPSS執行曼–惠特尼U檢定的操作方法。若您只對文章某部分的內容感興趣,也可點選下方的連結,即可直接跳至您想瞭解的內容喔。
曼–惠特尼U檢定的使用時機
曼–惠特尼U檢定用來探討兩個獨立的群體或樣本是否有所不同,是類似於獨立樣本t檢定的一種統計檢定方法。當變項資料的測量尺度為次序尺度或獨立樣本t檢定的基本假設受到嚴重違反的時候,曼–惠特尼U檢定會是一種比獨立樣本t檢定更合適的統計檢定方法。
基本上,獨立樣本t檢定適用在測量尺度為等距或比率尺度的變項資料上,當資料為次序尺度的時候,該檢定方法就變得不合適。然而,曼–惠特尼U檢定可用在測量尺度至少為次序尺度的資料上,所以當資料為次序尺度時,曼–惠特尼U檢定是較好的選擇。
此外,獨立樣本t檢定是一種對樣本來自的母群體有特定要求的母數檢定,也就是樣本資料須滿足常態分配和變異數同質性(homogeneity of variance)兩個假設。雖然獨立樣本t檢定是一種穩健(robust)的檢定方法,當兩個基本假設受到輕度或中度違反時,檢定結果可能仍具可信度;但當假設受到嚴重違反的時候,獨立樣本t檢定便不太合適。
反觀曼–惠特尼U檢定,將兩個獨立群體或樣本裡的數值轉換成等級後再進行比較,為一種對樣本來自的母群體沒有什麼特定要求的無母數檢定。因此,當兩個群體或樣本來自的母群體沒有呈現常態分配,或變異不相等( )的情況下,曼–惠特尼U檢定可代替獨立樣本t檢定。
)的情況下,曼–惠特尼U檢定可代替獨立樣本t檢定。
總結來說,曼–惠特尼U檢定適用在測量尺度至少為次序尺度的變項資料上,或兩個獨立群體或樣本來自的母群體沒有呈現常態分配或變異不相等的情況下。也就是說,當樣本資料嚴重違反獨立樣本t檢定的基本假設時,曼–惠特尼U檢定是更為合適的統計檢定方法。
瞭解了曼–惠特尼U檢定的使用時間點後,下面舉個例子來說明曼–惠特尼U檢定的假設檢定過程。
曼–惠特尼U檢定的假設檢定
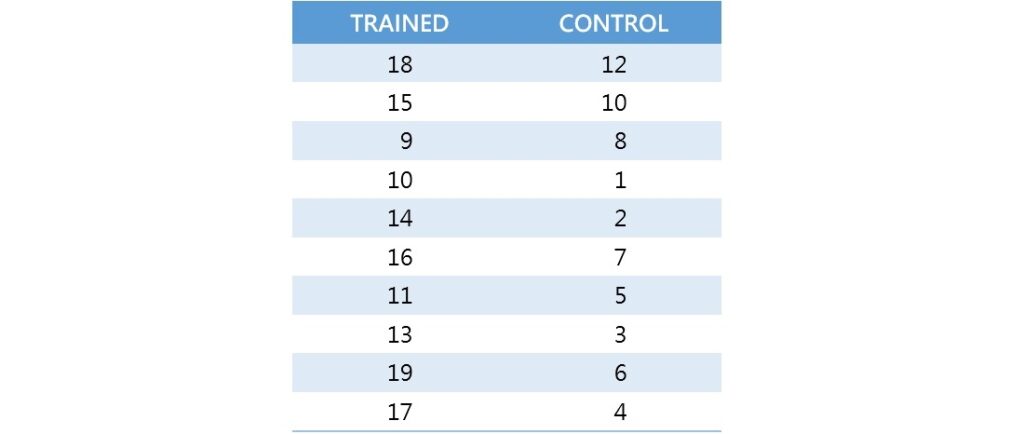
假設一位保險公司的經理主張受過人際關係訓練的業務人員比較能夠給客戶留下好印象,進而招攬到較多的客戶。為了檢驗這個假設,她從新進的業務人員裡隨機抽取出20位,分配其中的10位至人際關係訓練課程,剩下的10位則沒有參與任何課程。課程結束後,20位業務人員皆參與一個客戶招攬的模擬面談,並接受評比。分數為1到20分,分數愈高代表表現愈好。
若參與課程組的名稱為TRAINED、沒有參與課程組的名稱為CONTROL,每一組各有10位業務人員,這20位業務人員的成績如下表。使用曼–惠特尼U檢定, ,試問受過人際關係訓練的業務人員是否較能夠給客戶留下好印象?
,試問受過人際關係訓練的業務人員是否較能夠給客戶留下好印象?
假設檢定的過程包含研究假設的擬定、顯著水準的選擇、檢定統計量的計算和決策規則的行使等步驟,以下分別來討論。
研究假設的擬定和顯著水準的選擇
在這個研究裡,保險公司的經理主張受過人際關係訓練的業務人員比較能夠給客戶「留下好印象」,因為有指出方向,所以屬於有方向性的研究假設。研究假設可分為對立假設和虛無假設,在這個研究裡這兩個假設分別為:
- 對立假設(
 ):和沒有參與過課程的業務人員相比較,參與過人際關係訓練課程的業務人員較能讓客戶留下好印象。
):和沒有參與過課程的業務人員相比較,參與過人際關係訓練課程的業務人員較能讓客戶留下好印象。 - 虛無假設(
 ):和沒有參與過課程的業務人員相比較,參與過人際關係訓練課程的業務人員沒有較能讓客戶留下好印象。也就是說,參與過人際關係訓練課程的業務人員在客戶對自己的印象上沒有影響,或讓客戶留下不好的印象。
):和沒有參與過課程的業務人員相比較,參與過人際關係訓練課程的業務人員沒有較能讓客戶留下好印象。也就是說,參與過人際關係訓練課程的業務人員在客戶對自己的印象上沒有影響,或讓客戶留下不好的印象。
闡述完研究假設後,須選擇適當的顯著水準或稱為α水準,通常依據研究的性質、目的和可能帶來的後果來決定,習慣上為0.05或0.01。這個研究選擇了0.05的顯著水準,且因為研究假設具有方向性,所以採用單尾檢定,可用符號 來表示。
來表示。
由於這個研究使用1到20分來評估業務人員的面談表現,也是該研究的依變項,所以變項資料屬於次序尺度。另外,這個研究要比較參與過人際關係訓練課程和沒有參與過訓練課程的業務人員在模擬面談上的表現,屬於兩個群體或樣本的比較。考量這兩個因素,曼–惠特尼U檢定是合適的統計檢定方法。
檢定統計量的計算
為了評估能否拒絕虛無假設,須先計算出曼–惠特尼U檢定的檢定統計量, 或
或 。不論是或,都是用來測量兩組樣本數值之間的分離程度。若自變項(這裡為人際關係訓練課程)沒有效果,兩組樣本數值間的分離程度較低,這也代表數值的等級平均分配在兩個樣本裡,
。不論是或,都是用來測量兩組樣本數值之間的分離程度。若自變項(這裡為人際關係訓練課程)沒有效果,兩組樣本數值間的分離程度較低,這也代表數值的等級平均分配在兩個樣本裡, 。
。
反之,若自變項具有效果,兩組樣本數值間的分離程度會比較高,也就是一個樣本裡的數值等級偏低,另一個樣本的數值等級則偏高。當分離程度愈高的時候,會減少而會增加;當完全分離的時候, 。對任一研究而言,
。對任一研究而言, (
( 指第1個群體或樣本的個數,
指第1個群體或樣本的個數, 指第2個群體或樣本的個數)。
指第2個群體或樣本的個數)。
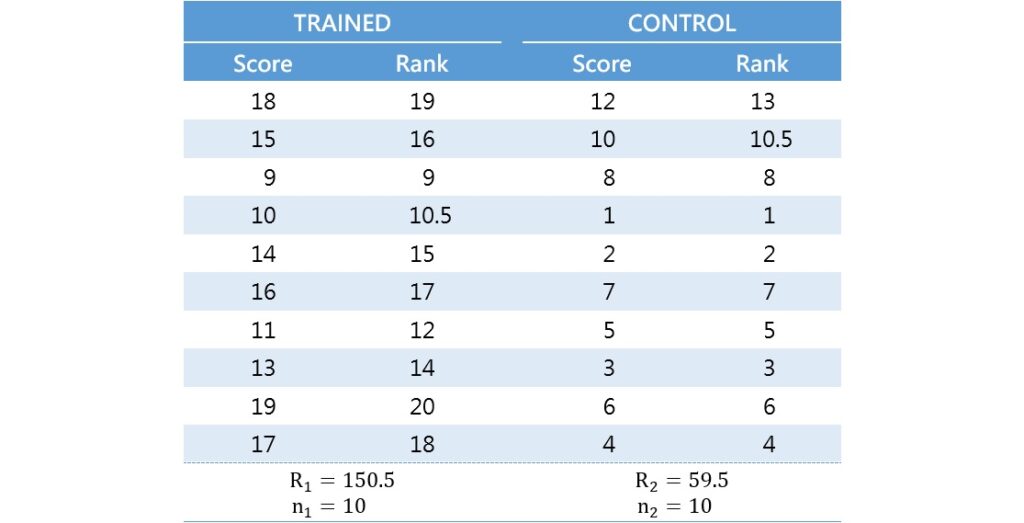
計算曼–惠特尼的檢定統計量包含3個步驟。首先,合併兩個樣本的分數,並將分數從小到大排序,給予最低分等級1、最高分等級20,如下表的Rank欄。如果有相同的分數,則給予平均等級。例如這個研究裡有2個10分,分別占據第10和11名,平均等級為 ,所以分配等級10.5給這2個10分,下一個分數11則從等級12開始排序。
,所以分配等級10.5給這2個10分,下一個分數11則從等級12開始排序。
接著,加總每一個樣本裡的等級。參與課程組(TRAINED)的分數等級總和 為150.5,人數為10;而沒有參與課程組(CONTROL)的分數等級總和
為150.5,人數為10;而沒有參與課程組(CONTROL)的分數等級總和 為59.5,人數為10,如下表的最後一列所示。
為59.5,人數為10,如下表的最後一列所示。
最後,利用兩個樣本各自的等級總和,計算出曼–惠特尼U檢定的檢定統計量和。和的計算公式分別如下:

將上表中已經計算出來的、、和帶入上面的兩個公式裡,計算過程如下:

計算結果得到 ,而
,而 。若您讓第1個樣本為沒有參與課程組、第2個樣本為參與課程組,計算出來的和數值會和這裡計算出來的數值顛倒,但這不會影響最後的結果。原則上,讓計算出來的較小數值為、較大的數值為。
。若您讓第1個樣本為沒有參與課程組、第2個樣本為參與課程組,計算出來的和數值會和這裡計算出來的數值顛倒,但這不會影響最後的結果。原則上,讓計算出來的較小數值為、較大的數值為。
另外有一點須留意,若是有方向性的研究假設,須注意兩個樣本各自的等級總和是否和對立假設所擬定的方向一致,若不一致,則無須進行至下一步驟的決策規則行使。例如這個研究的對立假設為參與過課程的業務人員較能給客戶留下好印象,因此參與課程組的等級總和應高於沒有參與課程組;如果計算結果是沒有參與課程組的等級總和較高,則因和對立假設的方向不一致,即應保留虛無假設,無須再執行剩餘的假設檢定步驟。
決策規則的行使
計算出曼–惠特尼U檢定的檢定統計量和後,須和和的臨界值比較,才能決定是否拒絕虛無假設。曼–惠特尼U檢定的臨界值表在兩個樣本的各種不同樣本大小組合下都會有兩個臨界值,一個數值較小,另一個數值較大,決策規則為:
- 如果
 較小數值,拒絕虛無假設且接受對立假設。
較小數值,拒絕虛無假設且接受對立假設。 - 如果
 較大數值,拒絕虛無假設且接受對立假設。
較大數值,拒絕虛無假設且接受對立假設。
因為和都在測量相同的分離程度,因此上面的兩個決策規則裡,只需要使用其中的一個,習慣上評估就好。
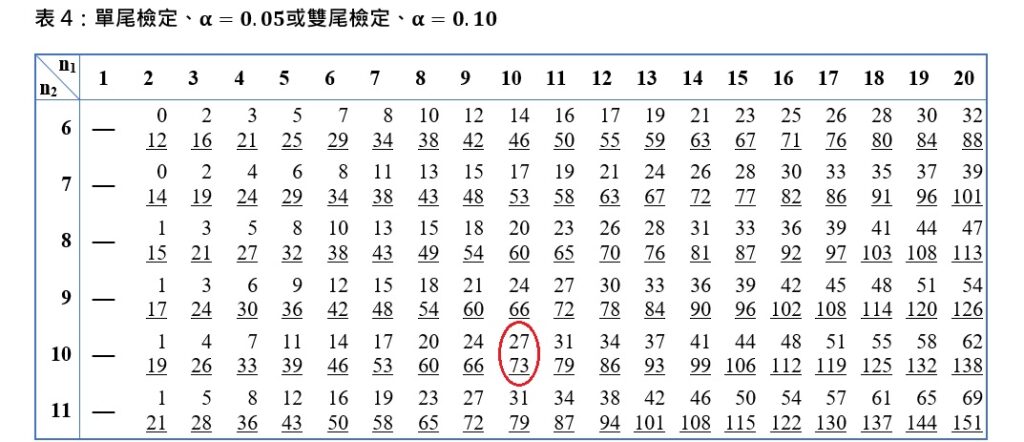
曼–惠特尼U檢定的臨界值表有4個表格,先依據事前選擇的α水準和檢定方向性的有無,決定使用哪一個表格;再根據兩個樣本各自的樣本個數,尋找臨界值。這個研究的α水準為0.05、單尾檢定,所以使用第4個表格。當 且
且 的時候,臨界值為27、臨界值為73。
的時候,臨界值為27、臨界值為73。
比較檢定統計量和臨界值,因為 ,所以拒絕虛無假設,接受對立假設。曼–惠特尼U檢定的分析結果指出,曾參與過人際關係訓練課程的業務人員比沒有參與過訓練課程的業務人員較能讓客戶留下好印象。
,所以拒絕虛無假設,接受對立假設。曼–惠特尼U檢定的分析結果指出,曾參與過人際關係訓練課程的業務人員比沒有參與過訓練課程的業務人員較能讓客戶留下好印象。
趨近於常態分配的曼–惠特尼U檢定
曼–惠特尼U檢定的臨界值表只提供到兩個樣本各自的樣本個數最大到20而已,若超出這些樣本大小,曼–惠特尼U檢定的抽樣分配已漸趨近於常態分配。理論上,當兩個樣本的樣本個數差不多,且其中一個樣本的樣本個數大於20的時候,便可使用常態分配和z檢定統計量來評估兩個樣本的數值等級是否有顯著的不同。
當趨近於常態分配時,可以用下面的公式來計算曼–惠特尼U檢定的z檢定統計量:
![\[ z=\frac {U-\displaystyle \frac {n_1n_2}{2}}{\sqrt {\displaystyle \frac {n_1n_2(n_1+n_2+1)}{12}}} \]](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-c59581aa3a564eeb17951b950ec2d6d3_l3.png "Rendered by QuickLaTeX.com")
若用上面的例子來練習,將已經計算出來的、和帶入上面的公式裡,計算過程如下:

計算結果得到z檢定統計量為-3.439。接著,查詢標準常態分配表,當α水準為0.05、單尾檢定,也就是下表的B欄為0.05時,z臨界值為 。
。
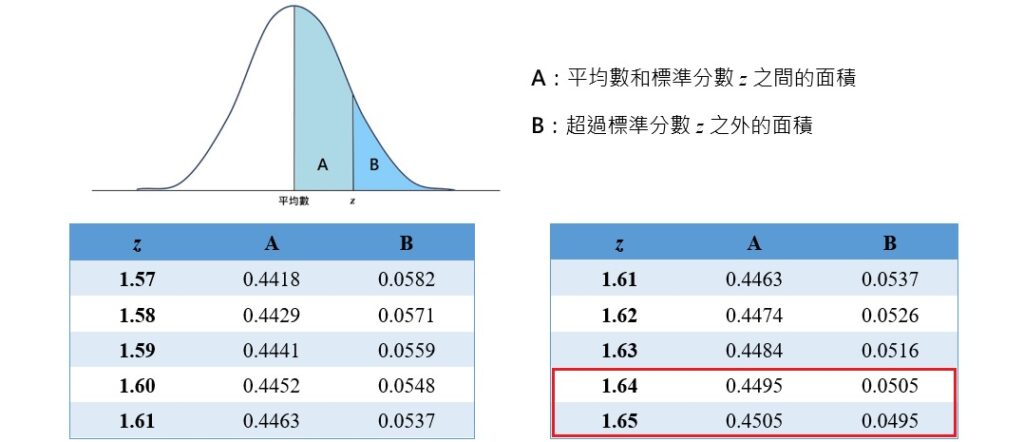
由於這個研究的對立假設為參與過訓練課程的業務人員較能夠給客戶留下「好」印象,單尾檢定的方向落在常態分配的右側尾端,所以取z檢定統計量的絕對值使其變成正數後,再和z臨界值相比較。
因為 ,所以可拒絕虛無假設,接受對立假設。透過常態逼近的曼–惠特尼U檢定,分析結果顯示參與過人際關係訓練課程的業務人員比沒有參與過課程的業務人員更能讓客戶留下好印象。
,所以可拒絕虛無假設,接受對立假設。透過常態逼近的曼–惠特尼U檢定,分析結果顯示參與過人際關係訓練課程的業務人員比沒有參與過課程的業務人員更能讓客戶留下好印象。
運用SPSS執行曼–惠特尼U檢定
將上面研究範例的資料輸入至SPSS資料編輯器裡,除了變項分數(SCORE)之外,還要有一個組別(GROUP)的變項。組別變項的標籤值1為參與訓練課程組(TRAINED),標籤值2為沒有參與訓練課程組(CONTROL)。關於SPSS的資料輸入方法,請參考SPSS操作環境和資料輸入。
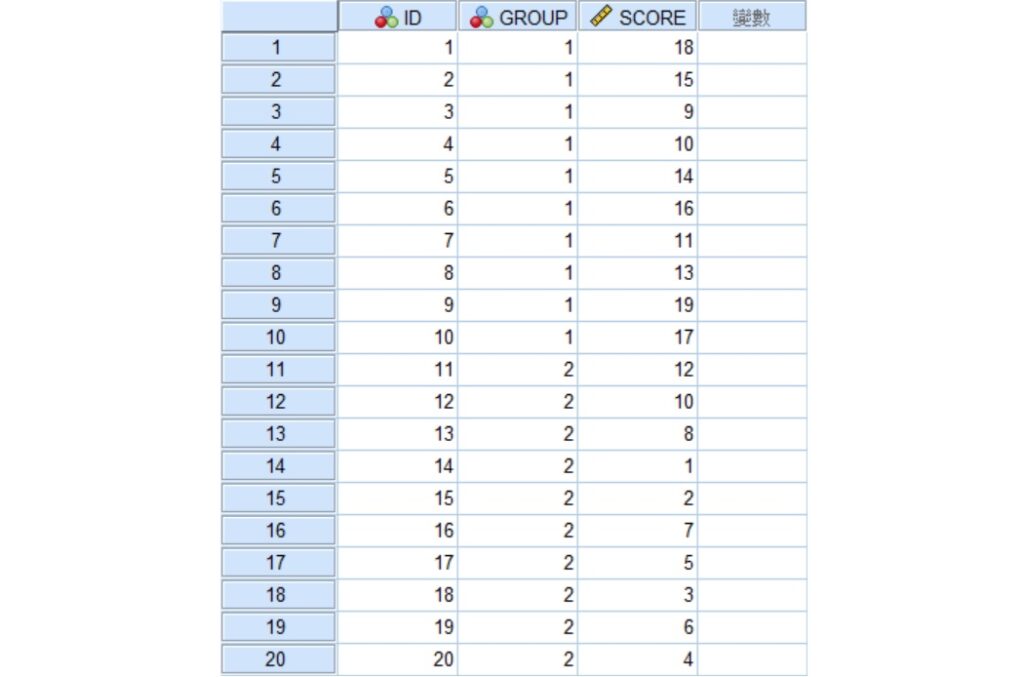
資料輸入完成後,點選功能表的分析 » 無母數檢定 » 舊式對話框 » 2個獨立樣本,帶出「兩個獨立樣本檢定」視窗。
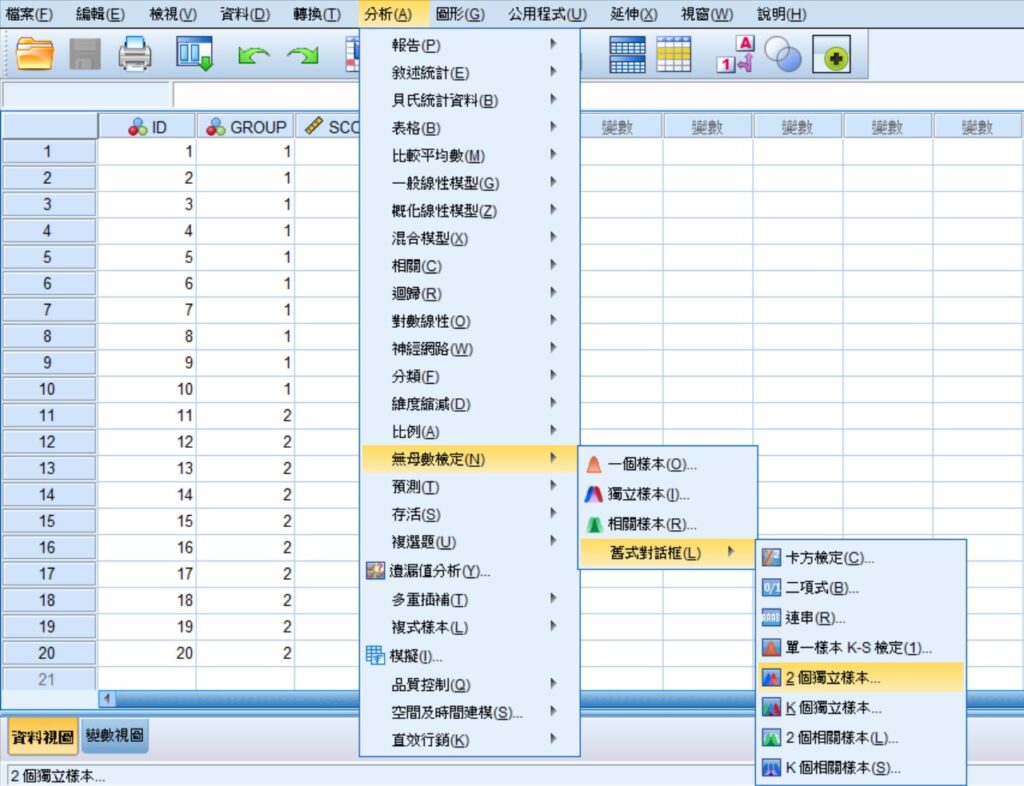
在「兩個獨立樣本檢定」視窗裡,將SCORE移到檢定變數清單(T)方框中,GROUP移到分組變數(G)裡。接著,點選定義群組(D),在隨即出現的小視窗裡,群組1裡輸入1、群組2裡輸入2(也就是組別變項GROUP的兩個標籤值),完成後點選繼續(C)。
回到「兩個獨立樣本檢定」視窗後,檢定類型的長方框中勾選Mann-Whitney U(M)的選項,完成後點選視窗最下方的確定。
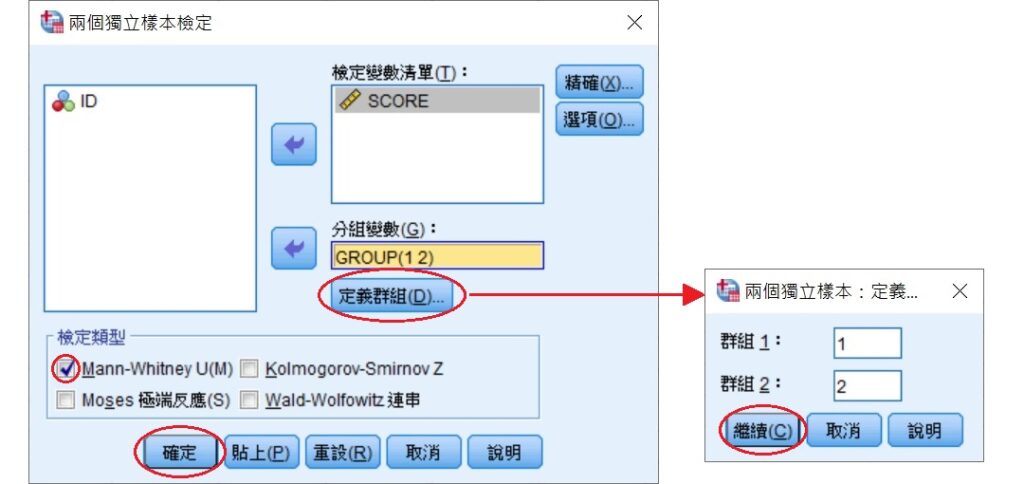
經過上述的操作後,SPSS會輸出兩個表格。第1個表格為「等級」表,會顯示各個群組或樣本的個數和等級總和;第2個表格則是曼–惠特尼U檢定的「統計量」表,會顯示曼–惠特尼U檢定的檢定統計量和獲得該檢定統計量的機率 值。。
值。。
從「等級」表可以看出,兩個樣本的樣本大小各為10,參與訓練課程組(TRAINED)的等級總和為150.5,沒有參與訓練課程組(CONTROL)的等級總和為59.5。這兩個等級總和與紙筆計算的結果相同,也就是和。
從「統計量」表可以看出,檢定統計量為4.5,和上面紙筆計算的結果相同。SPSS使用常態逼近的曼–惠特尼U檢定來進行假設檢定,z檢定統計量為-3.441,而獲得該結果的機率值(漸近顯著性)為0.001。由於SPSS顯示雙尾檢定的機率,所以須將該機率除以2才是單尾檢定的機率。
比較單尾檢定的機率( )和事先選擇的α水準,因為
)和事先選擇的α水準,因為 ,所以拒絕虛無假設,接受對立假設。常態逼近的曼–惠特尼U檢定的分析結果指出,參與過人際關係訓練課程的業務人員比沒有參與過訓練課程的業務人員更能讓客戶留下好印象。
,所以拒絕虛無假設,接受對立假設。常態逼近的曼–惠特尼U檢定的分析結果指出,參與過人際關係訓練課程的業務人員比沒有參與過訓練課程的業務人員更能讓客戶留下好印象。
眼尖的您會發現SPSS輸出的z檢定統計量(-3.441)和上面紙筆計算的結果(-3.439)有些微差距,這是因為SPSS考量了資料裡的平分情況而調整了公式分母的標準差計算方法。若資料裡有平分的情形,也就是相同等級的存在,SPSS和多數的統計分析軟體會採用下列的公式計算z檢定統計量:
![\[ z=\frac {U-\displaystyle \frac {n_1n_2}{2}}{\sqrt {\displaystyle \frac {n_1n_2}{12} \left [ (n_1+n_2+1)-\frac {\sum_{i=1}^g (t_i^3-t_i)}{(n_1+n_2)(n_1+n_2-1)} \right ] } }\]](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-5028a5e4774438e3b2253428f7893908_l3.png "Rendered by QuickLaTeX.com")
在上面的公式裡, 指資料裡平分的組數,
指資料裡平分的組數, 指第
指第 組裡平分的數值數目。以這裡的研究範例來看,平分的組數為1組,而該組裡平分的數值有2個,所以
組裡平分的數值數目。以這裡的研究範例來看,平分的組數為1組,而該組裡平分的數值有2個,所以 的計算過程為:
的計算過程為:
![\[ \sum_{i=1}^g (t_i^3-t_i)=2^3-2=6 \]](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-c7857020a53c1462632fb9f3f43f01b8_l3.png "Rendered by QuickLaTeX.com")
將上面的計算結果帶入分母經過調整的z檢定統計量公式裡,計算過程如下:
![\begin{align*}z &= \frac {4.5-\displaystyle \frac {10(10)}{2}}{\sqrt {\displaystyle \frac {10(10)}{12} \left [ (10+10+1)-\frac {6}{(10+10)(10+10-1)} \right ] }} \\&= \frac {4.5-50}{\sqrt {\displaystyle \frac {100}{12} \left [ 21-\frac {6}{20(19)} \right ] }} \\&\approx -3.441\end{align*}](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-a3e967c34c362ab516eab8783ebb5d31_l3.png "Rendered by QuickLaTeX.com")
利用分母經過調整的公式計算出來的z檢定統計量為-3.441,這就和SPSS輸出的結果相同。若資料裡只有少數幾組平分的組數,使用未經調整和經過調整的公式所計算出來的結果不會相差太多;但若平分的組數較多的話,使用分母經過調整的公式會得到較正確的結果。
總結來說,曼–惠特尼U檢定利用了資料裡滿多的量化訊息,且是獨立樣本t檢定的一種替代檢定,可說是一種強力的統計檢定方法。不過,曼–惠特尼U檢定畢竟只用到變項資料的次序屬性,不像獨立樣本t檢定利用變項資料的等距或比率屬性,因此沒有獨立樣本t檢定那麼地強大。
以上為本篇文章對曼–惠特尼U檢定的介紹,希望透過本篇文章,您瞭解了曼–惠特尼U檢定的使用時機和假設檢定過程,也學會了利用SPSS執行曼–惠特尼U檢定的操作方法。
如果您喜歡本篇文章,請將本網站加入書籤,作為您的學習工具,並持續回訪本網站喔!另外,也歡迎您按讚和追蹤我們的Facebook和Twitter專頁喲!