🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
迴歸線和皮爾森積差相關係數間的關係
迴歸線和皮爾森積差相關係數(Pearson product-moment correlation coefficient)間具有相當密切的關係,皮爾森積差相關係數用來探討兩個變項間關係的方向和程度,而迴歸線是利用兩變項間的關係建構出一條作為預測用途的直線。
由於迴歸線可用來預測,所以只要知道自變項的數值,就可利用該條迴歸線的方程式估計依變項的數值。若依變項的原始數據稱為觀察值、透過迴歸線估計出來的數值稱為預測值,在知道觀察值、預測值和依變項數值平均數的情況下,即可求得皮爾森積差相關係數。
此外,迴歸線的斜率(slope)和皮爾森積差相關係數間也帶有一層關係。若將兩變項的數值都轉換成標準分數,再利用兩變項的標準分數數值去計算迴歸線的斜率,則斜率會等於皮爾森積差相關係數。
下面的內容將介紹這些迴歸線和皮爾森積差相關係數間的關係,若您不清楚或不熟悉迴歸線的建立或/和皮爾森積差相關係數的意義,建議您先閱讀最小平方迴歸線的建構和計算與何謂皮爾森積差相關係數,將有助於文章內容的理解喔。
可被解釋的變異和不可被解釋的變異
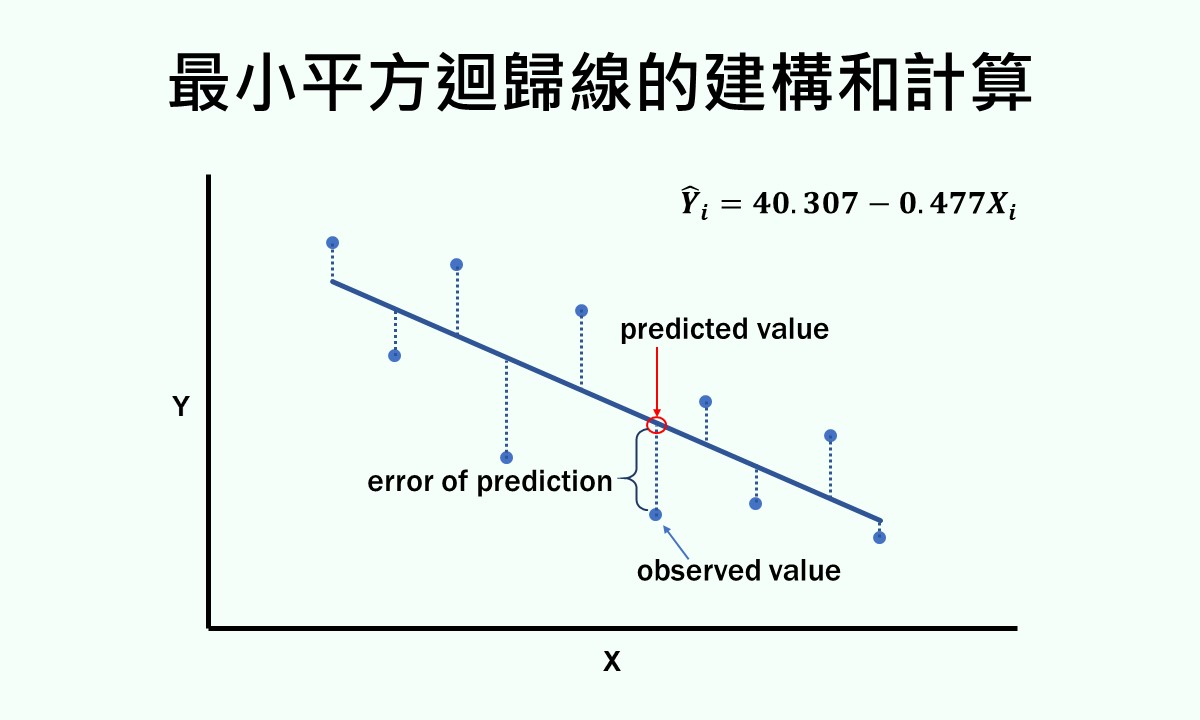
當兩個至少為等距尺度的自變項和依變項呈現不完全的線性關係時,在這兩個變項的成對數值所構成的點中,能夠畫出一條適合所有點的直線,且這條直線的方程式可作為自變項預測依變項的用途。因為這條線是一條將預測誤差最小化的直線,所以稱為最小平方迴歸線,一般簡稱為迴歸線(regression line)。
假設依變項的原始數據(或觀察值)為 ,透過迴歸線預測出來的數值為
,透過迴歸線預測出來的數值為 ,依變項數值的平均數為
,依變項數值的平均數為 ,運用這3個數值可以組成3種不同的變異,分別為總變異、可被解釋的變異和不可被解釋的變異,這3種變異的意義分別為:
,運用這3個數值可以組成3種不同的變異,分別為總變異、可被解釋的變異和不可被解釋的變異,這3種變異的意義分別為:
- 總變異(total variation):由觀察值和平均數的差值構成,為下圖中的
 。若將每個觀察值和平均數的差值平方後再相加,即為總變異,用
。若將每個觀察值和平均數的差值平方後再相加,即為總變異,用 來表示,也稱為的總平方和。
來表示,也稱為的總平方和。 - 可被解釋的變異(explained variation):由預測值和平均數的差值構成,為下圖中的
 ,代表依變項能夠被自變項
,代表依變項能夠被自變項 解釋的部分。若將每個預測值和平均數的差值平方後再相加,即為可被解釋的變異,用
解釋的部分。若將每個預測值和平均數的差值平方後再相加,即為可被解釋的變異,用 來表示,又稱為迴歸平方和(regression sum of squares)。如果兩變項間的關聯程度愈高,預測值和平均數的差值會愈大,而可被解釋的變異也會愈大。
來表示,又稱為迴歸平方和(regression sum of squares)。如果兩變項間的關聯程度愈高,預測值和平均數的差值會愈大,而可被解釋的變異也會愈大。 - 不可被解釋的變異(unexplained variation):由觀察值和預測值間的差值構成,為下圖中的
 ,即為預測誤差。若將每個預測值和觀察值的差值平方後再相加,即是不可被解釋的變異,用
,即為預測誤差。若將每個預測值和觀察值的差值平方後再相加,即是不可被解釋的變異,用 來表示,又稱為誤差平方和(error sum of squares)。如果兩變項間的關聯程度愈高,觀察值和預測值的差值會愈小,而不可被解釋的變異也會愈小。
來表示,又稱為誤差平方和(error sum of squares)。如果兩變項間的關聯程度愈高,觀察值和預測值的差值會愈小,而不可被解釋的變異也會愈小。
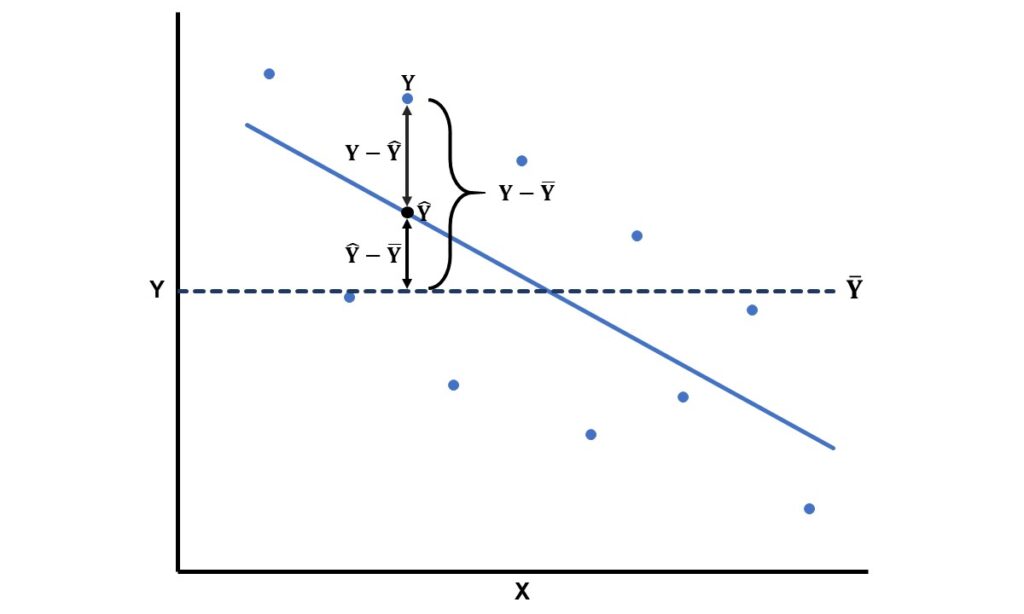
上述的3種變異在數學上有一層關係,總變異為可被解釋的變異與不可被解釋的變異之和。讓 表示第
表示第 個的數值、
個的數值、 為第個的預測值、為變項的平均數,這3種變異間的關係可以用下面的公式來表示:
為第個的預測值、為變項的平均數,這3種變異間的關係可以用下面的公式來表示:
(1) 
這裡使用最小平方迴歸線的建構和計算裡年齡和平均行車速度的例子,證明這3個變異之間的關係。下表為年齡和平均行車速度例子裡每一位參與者的原始數據、預測值和3個變異的數值,預測值是透過迴歸線方程式 計算而來。為了得到較準確的計算結果,無法整除的數值一律四捨五入至小數點後第5位。
計算而來。為了得到較準確的計算結果,無法整除的數值一律四捨五入至小數點後第5位。
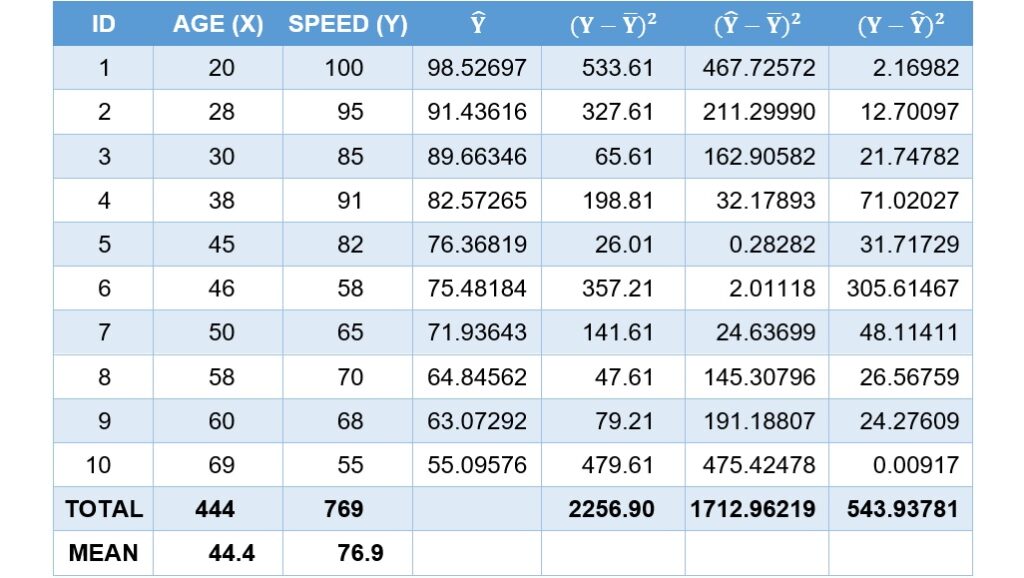
將上表中3種變異的各個總和帶入上面的公式(1)裡,可以發現總變異確實為可被解釋的變異和不可被解釋的變異之和。

這3種變異裡的可被解釋的變異和皮爾森積差相關係數有密切的關聯,下面就來介紹這兩者之間的關係。
可被解釋的變異和皮爾森積差相關係數的關係
回顧一下決定係數 (coefficient of determination)的意義,這個係數是皮爾森積差相關係數的平方,可用來說明依變項裡有多少的變異能夠被自變項解釋。
(coefficient of determination)的意義,這個係數是皮爾森積差相關係數的平方,可用來說明依變項裡有多少的變異能夠被自變項解釋。
上面提到的3種變異裡,可被解釋的變異是指依變項能夠被自變項解釋的變異,將這個可被解釋的變異除以總變異即為決定係數。
(2) 
皮爾森積差相關係數僅為決定係數的平方根, 。利用上面年齡和平均行車速度的例子,先透過公式(2)計算出決定係數,再求得皮爾森積差相關係數,計算過程如下:
。利用上面年齡和平均行車速度的例子,先透過公式(2)計算出決定係數,再求得皮爾森積差相關係數,計算過程如下:

計算結果得到決定係數為0.759,這個數值表示年齡可以解釋平均行車速度裡0.759或75.9%的變異。不過,皮爾森積差相關係數的數值有正數和負數,為了決定哪一個數值才是正確的相關係數,可以檢視兩個變項的散布圖,如下圖。
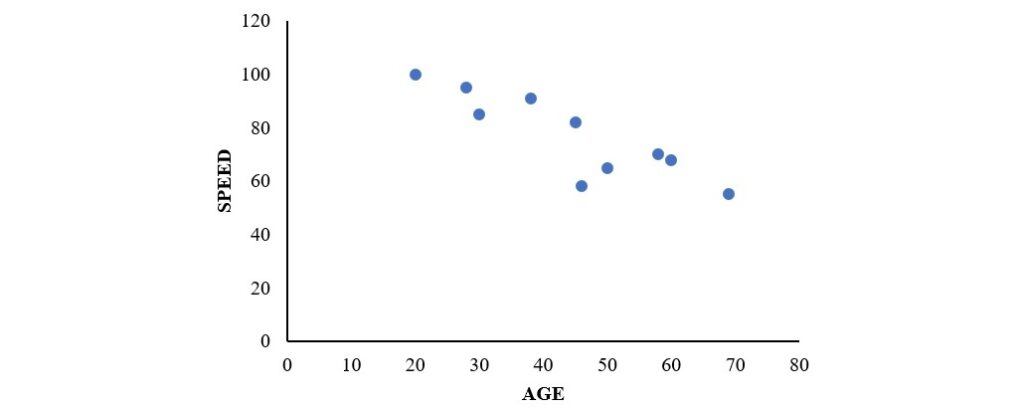
從上圖可以看出,兩個變項呈現負向的不完全關係,代表平均行車速度會隨著年齡增加而趨緩,所以年齡和平均行車速度的皮爾森積差相關係數 為-0.871,這個數值顯示兩者間的關聯程度相當地高。
為-0.871,這個數值顯示兩者間的關聯程度相當地高。
斜率和皮爾森積差相關係數的關係
皮爾森積差相關係數除了和迴歸線的可被解釋的變異有關聯之外,與迴歸線的斜率也有一層關係。在簡單線性迴歸(simple linear regression)裡,若將建構出迴歸線的兩個變項的數值都轉換成標準分數(z score),再用這兩變項的標準分數來建構迴歸線,則迴歸線斜率會等於皮爾森積差相關係數。
利用上面的年齡和平均行車速度的例子來證明這兩者之間的關係,下表為10位參與者的年齡(自變項)和平均行車速度(依變項)的原始資料、原始資料轉換後的標準分數、標準分數的交叉乘積與年齡標準分數的平方。為了得到較準確的計算結果,無法整除的數值一律四捨五入至小數點後第4位。
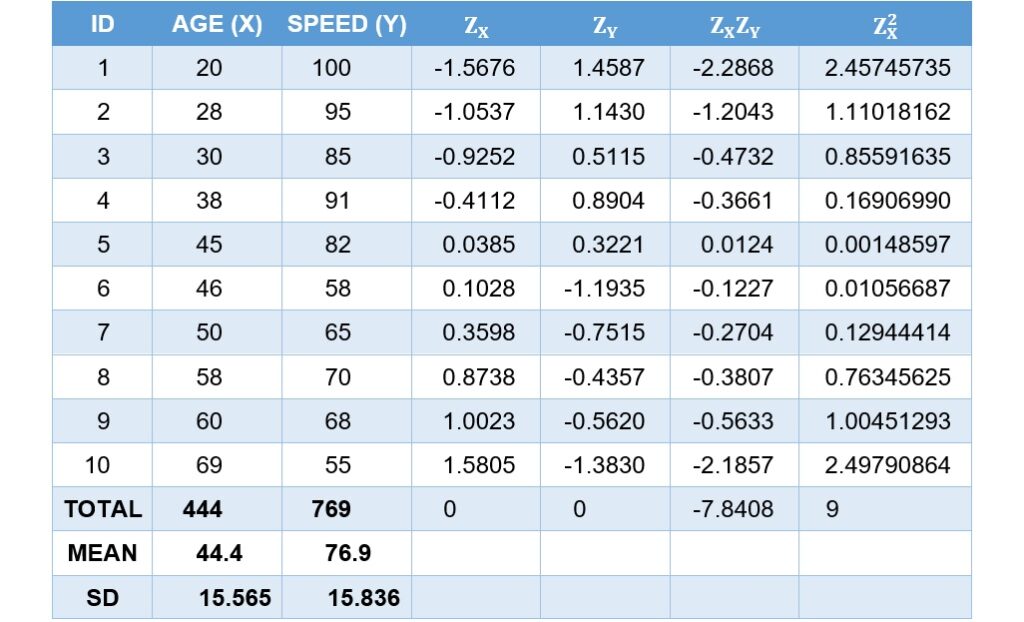
皮爾森積差相關係數在概念上即是將兩變項轉換成測量單位相同的標準分數後,再測量兩者之間關聯程度的一個量化數值。讓 表示兩變項成對標準分數的交叉乘積和、
表示兩變項成對標準分數的交叉乘積和、 為樣本總個數,皮爾森積差相關係數的概念公式如下:
為樣本總個數,皮爾森積差相關係數的概念公式如下:
(3) 
上表中已經計算出兩變項標準分數的交叉乘積和,將這個數值帶入上面的公式(3)裡,就可計算出皮爾森積差相關係數。
![\[ r=\frac {\sum {z_X z_Y}}{N-1}=\frac {-7.8408}{10-1} \approx -0.871 \]](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-38880a381bb2faf33c59134fff7df6c4_l3.png "Rendered by QuickLaTeX.com")
計算結果得到年齡和平均行車速度的皮爾森積差相關係數為-0.871,這個數值和上面利用迴歸線可被解釋的變異之方法所得到的結果是相同的。
接下來,利用上表中兩變項的標準分數( 和
和 )來計算以年齡預測平均行車速度的迴歸線斜率,計算公式和過程如下:
)來計算以年齡預測平均行車速度的迴歸線斜率,計算公式和過程如下:

從上面的計算過程可以發現,利用兩變項的標準分數計算出來的迴歸線斜率確實等於皮爾森積差相關係數。這個利用標準分數計算出來的斜率稱為標準化的迴歸係數(standardized regression coefficient),通常用β (beta)來表示,以便和非標準化的斜率 有所區別。
有所區別。
由於皮爾森積差相關係數是標準化的迴歸線斜率β,必定和非標準化的斜率相關聯,所以兩者之間具有如下公式的關係:
(4) 
也就是說,只要知道兩變項之間的皮爾森積差相關係數、兩變項各自的標準差,即可求得非標準化的迴歸線斜率。將上面年齡和平均行車速度例子的皮爾森積差相關係數、兩變項的標準差(上表中SD列的兩個數值)帶入上面的公式(4)裡,計算過程如下:

計算結果顯示非標準化的迴歸線斜率為-0.886,指當年齡增加1歲時,平均行車速度會減少0.886公里,而這個數值和最小平方迴歸線的建構和計算裡的計算結果是相同的。
運用SPSS取得迴歸線相關的變異和標準化係數
迴歸線相關的可被解釋的變異、不可被解釋的變異、總變異以及標準化的迴歸係數都是SPSS的標準輸出內容,只要透過SPSS的線性迴歸功能即可取得,下面示範操作方法。
將上面年齡和平均行車速度例子的資料輸入至SPSS資料編輯器裡,輸入完成後,點選功能表的分析 » 迴歸 » 線性,帶出「線性迴歸」視窗。關於SPSS資料輸入的方法,請參考SPSS操作環境和資料輸入。
在「線性迴歸」視窗裡,將平均行車速度SPEED移至應變數(D)長框裡、年齡AGE移至自變數(I)長方框裡,其他設定維持不變,最後按下視窗下方的確定。
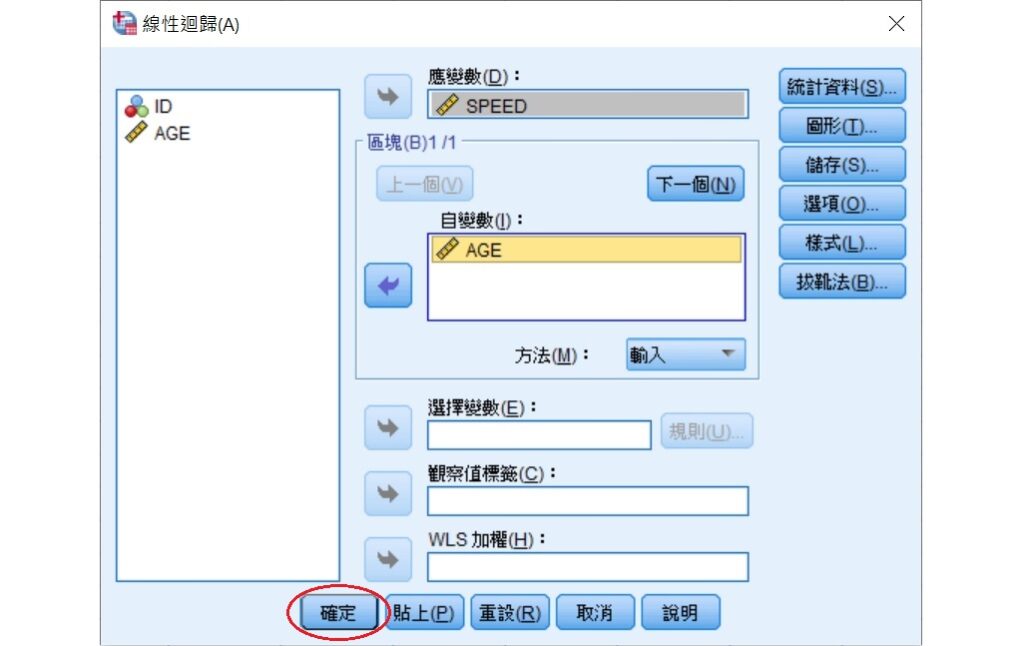
經過上面的步驟,SPSS即會輸出簡單線性迴歸的相關表格。在「變異數分析」表格裡,可以看到迴歸、殘差和總計平方和,這就是可被解釋的變異、不可被解釋的變異和總變異。可被解釋的變異為1712.962、不可被解釋的變異為543.938,而總變異為兩者之和2256.9,這些結果和上面使用紙筆計算的結果是相同的。
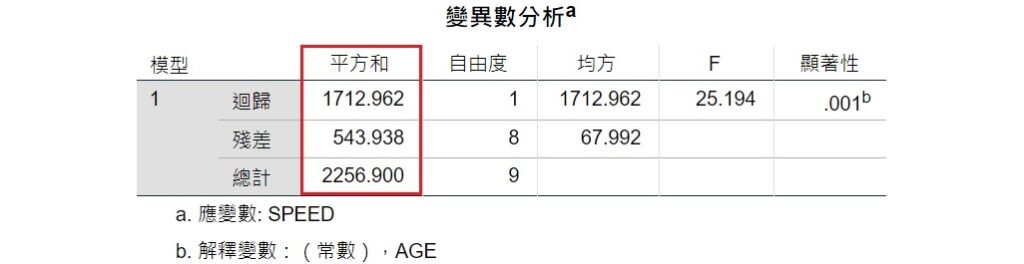
在「係數」表格裡,可以看到標準化係數β的數值為-0.871,這就是利用兩個變項的標準分數建構出來的迴歸線斜率。這個數值指出當年齡增加1個標準差單位時,平均行車速度會減少0.871個標準差單位。不過這樣的解釋方法較難讓人理解,因此通常還是會使用非標準化的係數(斜率)來解釋兩個變項之間的關係。
若想探討標準化係數β是否相同於皮爾森積差相關係數,可點選SPSS功能表的分析 » 相關 » 雙變異數,帶出「雙變量相關性」視窗。
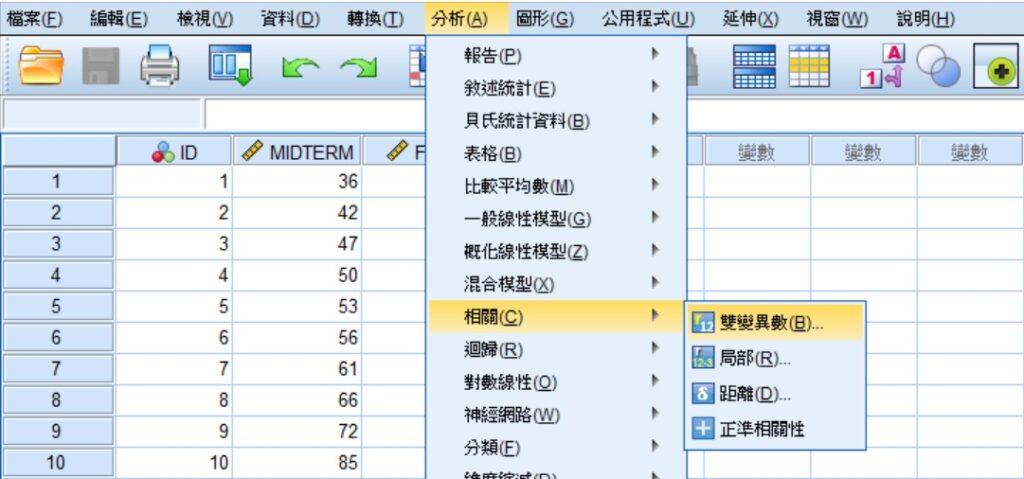
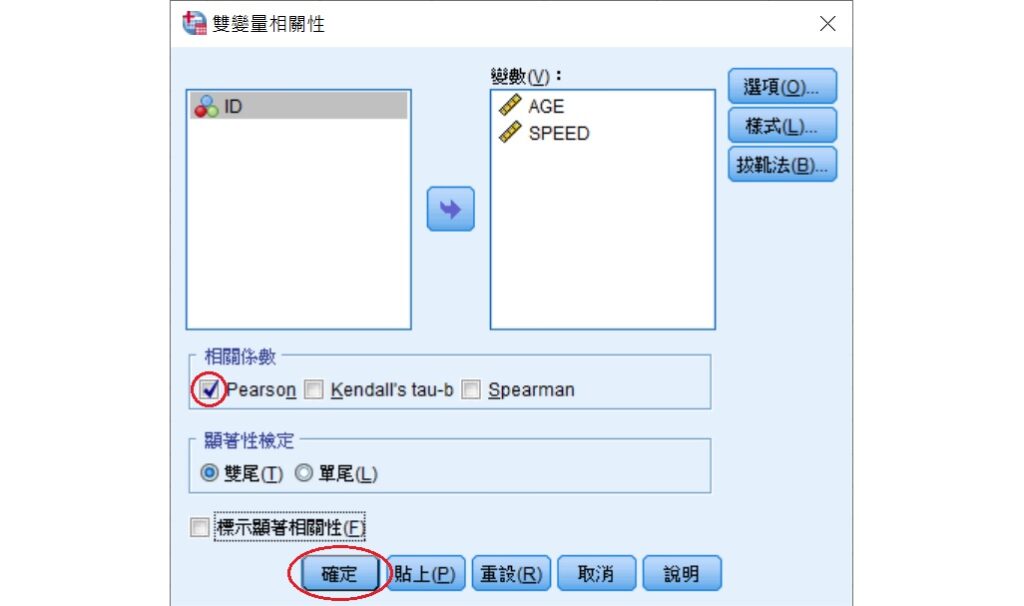
在「雙變量相關性」視窗裡,將年齡AGE和平均行車速度SPEED移至變數(V)方框中,並勾選相關係數長框中的Pearson選項。由於這裡沒有要進行假設檢定,所以可取消勾選顯著性檢定下方的標示顯著相關性(F)選項。完成後,按下視窗下方的確定。
透過上面的步驟,SPSS會輸出兩個變項的皮爾森積差相關係數。從下面的「相關性」表格可以看出,年齡和平均行車速度的相關係數為-0.871,而這個相關係數的數值確實相同於這兩個變項建構出來的迴歸線之標準化係數β。
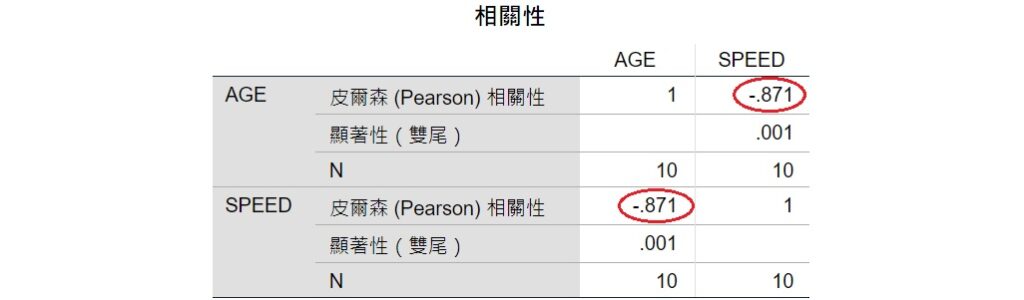
因此,在簡單線性迴歸裡,自變項和依變項建構出來的最小平方迴歸線的標準化迴歸係數β確實等於兩個變項的皮爾森積差相關係數。此外,只要有兩變項的皮爾森積差相關係數和兩變項各自的標準差,就可以求得非標準化的迴歸係數(斜率)。
以上為本篇文章對迴歸線和皮爾森積差相關係數間關係的介紹,希望透過本篇文章,您瞭解了迴歸線的可被解釋的變異、標準化迴歸係數與皮爾森積差相關係數之間的關聯,也學會了利用SPSS取得這些數值的方法。
若您喜歡本篇文章,請將本網站加入書籤,作為您的學習資源,並持續回訪本網站喔!另外,您也可以在Facebook和Twitter上找到我們喲!