🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
概似比檢定:類別資料分析的另一種選擇
在行為和社會科學領域的研究裡,當我們想針對類別變項進行假設檢定的時候,很常使用卡方檢定(chi-square test)。若要探討1個類別變項裡各個類別的發生次數是否不同於假設的母群體次數時,可使用卡方適合度檢定;若要探討2個類別變項間為彼此獨立或具有關聯性時,可使用卡方獨立性檢定。此外,如果樣本數很小且2個變項都各只有2個類別時,則可使用費雪精準檢定。
除了卡方檢定之外,另一個可用來分析類別變項資料的檢定方法為概似比檢定(likelihood ratio test)。概似比檢定運用最大概似理論(maximum likelihood theory)來分析2個類別變項構成的列聯表,藉此探討2變項之間的關係。統計分析軟體如 SPSS 會在卡方檢定分析結果的輸出表格裡同時顯示概似比檢定的分析結果,可見概似比檢定也是很常見的一種類別資料假設檢定方法。
下面內容將介紹概似比檢定的概念和使用方法,並舉一例子說明假設檢定的過程,最後示範利用 SPSS 執行這個檢定的操作方法。由於文章內容涉及假設檢定的過程,若您不清楚或不熟悉假設檢定的意義和步驟,可先參考假設檢定的步驟和範例,將有助於下面內容的理解喔!
概似比檢定的概念
概似比檢定是一種可以用來分析類別變項的統計檢定方法,而類別變項就是測量尺度為名義尺度的變項。依據最大概似理論,概似比檢定透過列聯表的分析來檢驗類別變項之間的關係。因為概似比檢定和卡方檢定一樣都是在探討類別變項間的關聯,所以可視為卡方檢定外的另一種統計檢定方法選擇。
概似比檢定的基本概念為2個概度(likelihood)或機率的比較,第1個概度為虛無假設為真時獲得研究所蒐集到資料(也就是觀察資料)的機率,第2個概度為在對立假設下獲得研究所蒐集到資料的最大機率。如果在對立假設下獲得觀察資料的可能性遠大於虛無假設為真時的可能性,可拒絕虛無假設;如果在對立假設下獲得觀察資料的可能性相似於虛無假設為真時的可能性,則保留虛無假設。
不論是單一變項的適合度檢定或2個變項的獨立性檢定都可用概似比的方法來進行分析,由於計算出來的檢定統計量帶有卡方分配(chi-square distribution)的型態,所以也可以稱為「最大概似卡方檢定」。評估分析結果時,和卡方檢定一樣,藉由事先設定的顯著水準(α水準)和自由度在卡方分配臨界值表裡尋找臨界值,再比較檢定統計量和臨界值,當檢定統計量等於或大於臨界值時,即可拒絕虛無假設。
單一變項的適合度檢定
適合度檢定適用在單一的類別變項上,檢驗各個類別的觀察次數是否不同於假設的母群體次數。若讓 代表第
代表第 個類別的觀察次數,
個類別的觀察次數, 代表第個類別的期望次數,
代表第個類別的期望次數, 為自然對數,利用概似比方法來計算適合度檢定的檢定統計量
為自然對數,利用概似比方法來計算適合度檢定的檢定統計量 公式如下:
公式如下:
(1) 
適合度檢定的自由度為類別變項的類別數目減1,如果類別數目為 ,自由度即為
,自由度即為 。接著,查詢卡方分配臨界值表,利用事先設定的α水準和自由度找到卡方臨界值,再比較利用公式(1)計算得到的數值和臨界值,當前者數值等於或大於後者時,即可拒絕虛無假設,接受對立假設。
。接著,查詢卡方分配臨界值表,利用事先設定的α水準和自由度找到卡方臨界值,再比較利用公式(1)計算得到的數值和臨界值,當前者數值等於或大於後者時,即可拒絕虛無假設,接受對立假設。
兩個變項的獨立性檢定
獨立性檢定適用在2個類別變項上,探討這2個變項彼此獨立或相互關聯,通常會先製作2個變項組成的列聯表後再進行分析。若讓 代表列聯表裡第列第
代表列聯表裡第列第 欄細格的觀察次數,
欄細格的觀察次數, 代表第列第欄細格的期望次數,為自然對數,利用概似比方法來計算獨立性檢定的檢定統計量公式如下:
代表第列第欄細格的期望次數,為自然對數,利用概似比方法來計算獨立性檢定的檢定統計量公式如下:
(2) 
列聯表裡各個細格的期望次數計算方法和卡方獨立性檢定相同,若讓 代表第個類別的列總和,
代表第個類別的列總和, 代表第個類別的欄總和,
代表第個類別的欄總和, 為樣本總數,一個細格的期望次數的計算公式為:
為樣本總數,一個細格的期望次數的計算公式為:
(3) 
獨立性檢定的自由度須用到列聯表的列和欄數目,若讓列的數目為 而欄的數目為
而欄的數目為 ,自由度為
,自由度為 。接著,利用事先設定的α水準和自由度在卡方分配臨界值表裡尋找臨界值,再比較利用公式(2)計算得到的數值和臨界值,當前者數值等於或大於後者時,就可拒絕虛無假設。
。接著,利用事先設定的α水準和自由度在卡方分配臨界值表裡尋找臨界值,再比較利用公式(2)計算得到的數值和臨界值,當前者數值等於或大於後者時,就可拒絕虛無假設。
從上面的說明可以發現,概似比檢定和卡方檢定同樣用來分析類別變項的資料,且兩者的檢定統計量同樣具有卡方分配的型態,是很類似的統計檢定方法。當樣本數較大時,2種方法的分析結果會差不多;但當樣本數較小時,卡方檢定會比概似比檢定更近似於卡方分配型態,因此卡方檢定會是較合適的檢定方法(Agresti, 2013)。
概似比檢定的例子
這裡使用卡方獨立性檢定的假設檢定裡生理性別和政黨傾向的例子,假設有位政治學者想探討生理性別和政黨支持傾向之間的關聯,她隨機抽取出500位成年女性和男性,並調查他們傾向於支持政黨A、政黨B或政黨C。資料整理完成後,生理性別和政黨傾向組成的2X3列聯表如下。若α水準為0.05,統計檢定為概似比檢定,試問生理性別和政黨傾向間是否有關聯?
| 政黨A | 政黨B | 政黨C | 列合計 | |
|---|---|---|---|---|
| 生理女性 | 120 | 15 | 115 | 250 |
| 生理男性 | 90 | 10 | 150 | 250 |
| 欄合計 | 210 | 25 | 265 | 500 |
這位政治學者想要探討民眾的生理性別和他們的政黨支持傾向之間是否存在關聯,因此這研究的虛無假設和對立假設分別如下:
- 虛無假設(
 ):生理性別和政黨支持傾向之間彼此獨立。
):生理性別和政黨支持傾向之間彼此獨立。 - 對立假設(
 ):生理性別和政黨支持傾向之間具有關聯。
):生理性別和政黨支持傾向之間具有關聯。
在這個例子裡,生理性別為2個類別的名義尺度變項而政黨支持傾向為3個類別的名義尺度變項,為了瞭解2個類別變項之間為彼此獨立或相互關聯,概似比檢定為合適的統計檢定方法。(當然,卡方獨立性檢定也是合適的統計檢定方法。)
因為要探討2個類別變項間的關係,所以適用獨立性檢定,須利用上面的公式(2)來計算檢定統計量。首先,利用上面的公式(3)計算出列聯表裡各個細格的期望次數,例如生理女性傾向支持政黨A的期望次數為:
![\[ \frac {250 \times 210}{500} = 105 \]](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-f5bf596ff80e96eed1d98227ea26d1e5_l3.png "Rendered by QuickLaTeX.com")
利用和上面相同的計算方法,求得列聯表裡其他細格的期望次數,完成後各個細格的期望次數會如下表:
| 政黨A | 政黨B | 政黨C | 列合計 | |
|---|---|---|---|---|
| 生理女性 | 105 | 12.5 | 132.5 | 250 |
| 生理男性 | 105 | 12.5 | 132.5 | 250 |
| 欄合計 | 210 | 25 | 265 | 500 |
接著,把每一個細格的觀察次數和期望次數帶入上面的公式(2),計算出概似比檢定的檢定統計量。由於算式很長,所以先分別計算每個細格的數值後再加總,運算過程中所有無法整除的數值都四捨五入到小數點後第5位,最後的答案再四捨五入到小數點後第3位,計算過程如下:
![\begin{gather*}\begin{alignat*}{3}\text {Female-Party A} &\Rightarrow 120 &&\ln \left ( \frac {120}{105} \right ) &&= 16.02377 \\[5pt]\text {Female-Party B} &\Rightarrow 15 &&\ln \left ( \frac {15}{12.5} \right ) &&= 2.73482 \\[5pt]\text {Female-Party C} &\Rightarrow 115 &&\ln \left ( \frac {115}{132.5} \right ) &&= -16.28981 \\[5pt]\text {Male-Party A} &\Rightarrow 90 &&\ln \left ( \frac {90}{105} \right ) &&= -13.87356 \\[5pt]\text {Male-Party B} &\Rightarrow 10 &&\ln \left ( \frac {10}{12.5} \right ) &&= -2.23144 \\[5pt]\text {Male-Party C} &\Rightarrow 150 &&\ln \left ( \frac {150}{132.5} \right ) &&= 18.60790\end{alignat*}\end{gather*}](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-185d30ef9af6b8d7679a0986a9e760d1_l3.png "Rendered by QuickLaTeX.com")
![\begin{align*}L \chi^2 &= 2(16.02377 + 2.73482 - 16.28981 - 13.87356 - 2.23144 + 18.60790) \\[5pt]&= 2(4.97168) \\[5pt]&\approx 9.943\end{align*}](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-c2d1a7385192bb3b706fd32642430dae_l3.png "Rendered by QuickLaTeX.com")
計算結果顯示檢定統計量為9.943,而2X3列聯表的自由度為 。從卡方分配臨界值表可以看到,當α水準為0.05且自由度為2的時候,卡方臨界值為5.991。
。從卡方分配臨界值表可以看到,當α水準為0.05且自由度為2的時候,卡方臨界值為5.991。
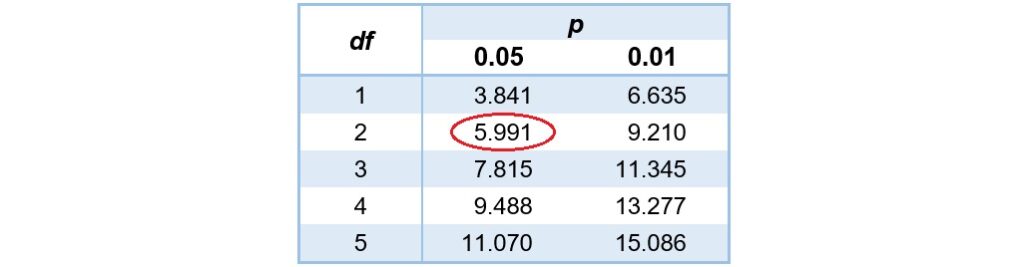
最後,運用決策規則,比較檢定統計量和臨界值。因為 ,所以拒絕虛無假設,接受對立假設。概似比檢定的分析結果指出,民眾的生理性別和他們的政黨支持傾向之間有關聯。
,所以拒絕虛無假設,接受對立假設。概似比檢定的分析結果指出,民眾的生理性別和他們的政黨支持傾向之間有關聯。
這樣的分析結果和在〈卡方獨立性檢定的假設檢定〉裡利用卡方獨立性檢定分析所得到的結果是一樣的,而且兩種方法的檢定統計量很相近,這也印證了當樣本數較大的時候,概似比檢定和卡方檢定的分析結果為一致的。
運用 SPSS 執行概似比檢定
在已經輸入資料的 SPSS 資料編輯器裡,點選功能表的分析 » 敘述統計 » 交叉資料表,帶出「交叉表」視窗。關於 SPSS 的介面和基本操作,請參考 SPSS操作環境和資料輸入。
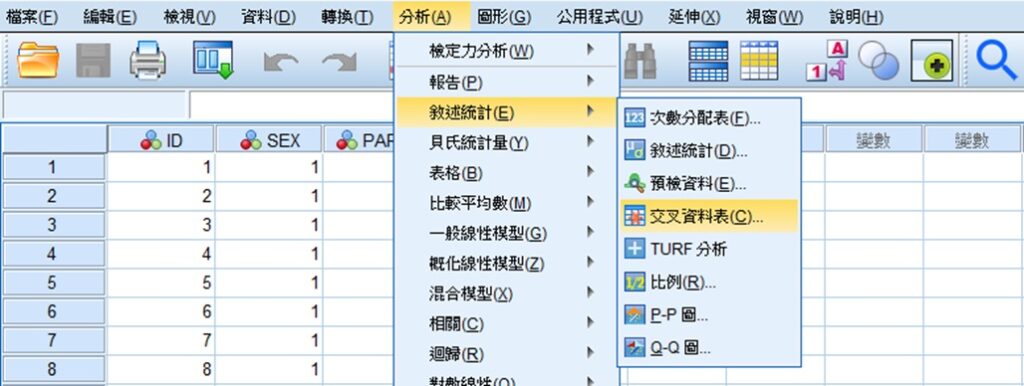
在「交叉表」視窗裡,把一個類別變項移至列(O),另一個類別變項移至欄(C),然後點選視窗最右側的統計量(S)。在「交叉資料表:統計量」視窗裡,勾選卡方檢定(H),完成後按下視窗下方的繼續(C)。回到「交叉表」視窗後,再按下視窗下方的確定。
經過上述的步驟,SPSS 會輸出如下的卡方檢定表格。表格裡的 Pearson Chi-Square 為我們熟悉的卡方獨立性檢定的分析結果,其下方的 Likelihood Ratio 就是概似比檢定的分析結果。
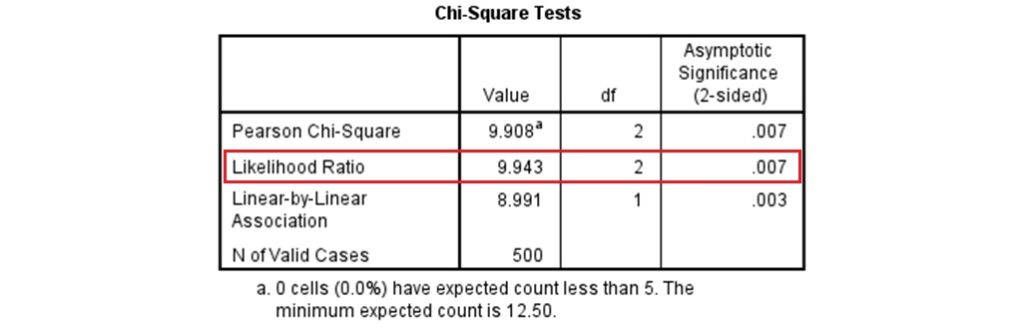
從上面的卡方檢定表可以看到,概似比檢定的檢定統計量為9.943,自由度為2,這樣的結果和上面利用紙筆計算得到的結果是相同的。利用 SPSS 評估分析結果時,可以直接比較獲得研究結果的機率( 值)與事先設定的α水準,當值等於或小於α水準時,可以拒絕虛無假設,接受對立假設;當值小於α水準時,則保留虛無假設。
值)與事先設定的α水準,當值等於或小於α水準時,可以拒絕虛無假設,接受對立假設;當值小於α水準時,則保留虛無假設。
上面的卡方檢定表顯示值為0.007,因為 ,所以拒絕虛無假設。也就是說,概似比檢定的分析結果顯示民眾的生理性別和他們的政黨支持傾向有關聯。
,所以拒絕虛無假設。也就是說,概似比檢定的分析結果顯示民眾的生理性別和他們的政黨支持傾向有關聯。
以上為本篇文章對概似比檢定的介紹,希望透過本篇文章,您瞭解了概似比檢定的概念和使用時機,也學會了運用 SPSS 執行概似比檢定的方法。若您喜歡這篇文章,請將本網站加入書籤,並隨時回訪本網站喔!另外,也歡迎您追蹤本網站的 Facebook 和/或 X(Twitter)專頁喲!
如果您覺得本篇文章對您有幫助,歡迎買杯珍奶給 Dr. Fish!小小珍奶,大大鼓勵,您的支持將給 Dr. Fish 更多撰寫優質文章的動力喔!
參考資料
Agresti, A. (2013). Categorical data analysis (3rd ed.). Hoboken, NJ: John Wiley & Sons, Inc.