🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
如何使用Excel計算最小平方迴歸線的預測區間
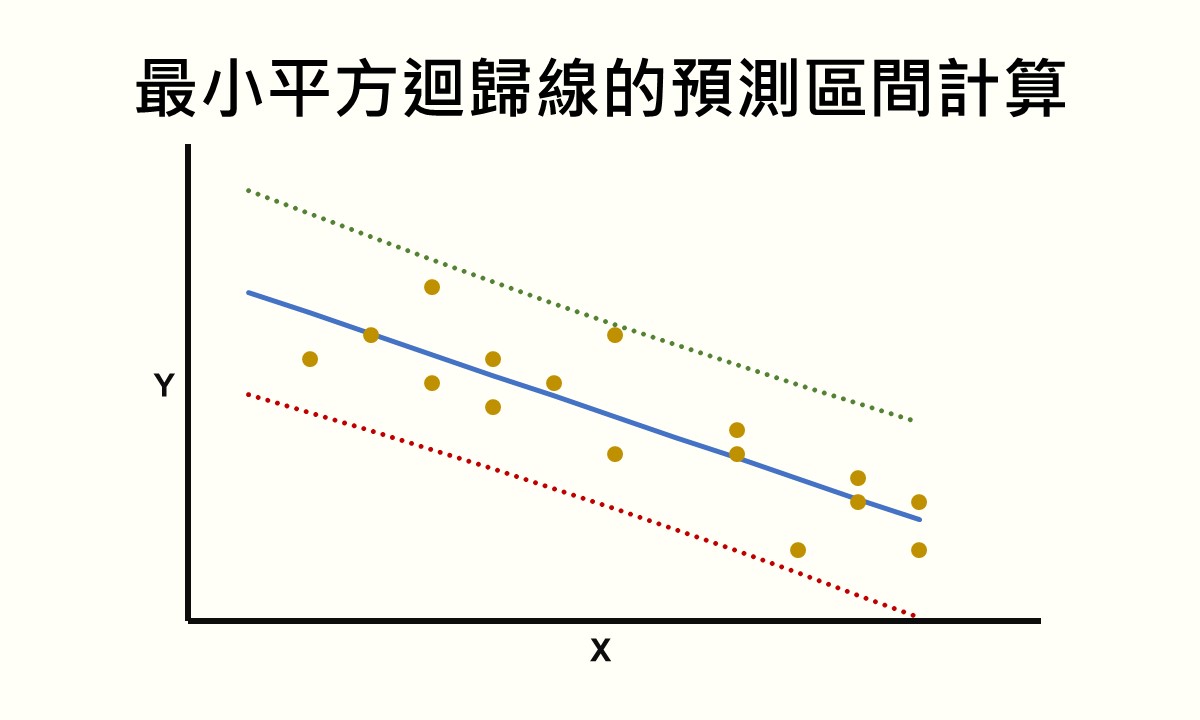
最小平方迴歸線的一個最主要的應用層面即在於預測某個自變項數值的依變項結果,且通常會用來預測不在樣本裡的自變項數值。當利用最小平方迴歸線進行預測時,雖然可以得到單一的預測值,但這一個預測值實為平均的預測結果。既然是個平均的預測結果,就會有變異,因此能夠計算出預測區間,也就是包含依變項預測結果的數值範圍。
利用統計分析軟體如 SPSS 可以很簡單地輸出預測區間的上、下界限,但若沒有統計分析軟體,也可以透過較容易取得的微軟 Excel 來計算。雖然計算過程牽涉較多的步驟,須使用到數個函數,但在沒有統計分析軟體的情況下,不失為一個好的方法。下面將直接示範操作方法,不做學理說明,若想瞭解預測區間的用途和計算過程,請參考最小平方迴歸線的預測區間計算。
這裡使用〈最小平方迴歸線的預測區間計算〉裡孩童年齡和問題解決時不相關回應的例子,自變項為年齡 AGE,依變項為不相關的回應次數 RESPONSE。樣本裡共有12位孩童,他們的年齡和不相關回應次數的資料如下表。

若要利用 Excel 求得不在樣本裡的8歲和10歲孩童的不相關回應次數的95%預測區間,可以依循下列的操作步驟來計算。
- 資料輸入至 Excel 活頁簿或工作表
- COUNT 函數計算樣本數
- AVERAGE 函數計算平均數
- DEVSQ 函數計算離差平方和
- STEYX 函數計算估計標準誤
- T.INV.2T 函數取得t臨界值
- FORECAST.LINEAR 函數求得依變項的預測值
- 運用公式計算個別預測的標準誤
- 運用公式計算預測區間
資料輸入至 Excel 活頁簿或工作表
把上面表格中的12位孩童的資料輸入至空白的活頁簿或工作表裡,一欄為一個變項,第1列為變項的名稱。在 AGE 和 RESPONSE 這2個變項前,加入1個孩童編碼 ID 的變項,可以清楚地看出樣本總數。
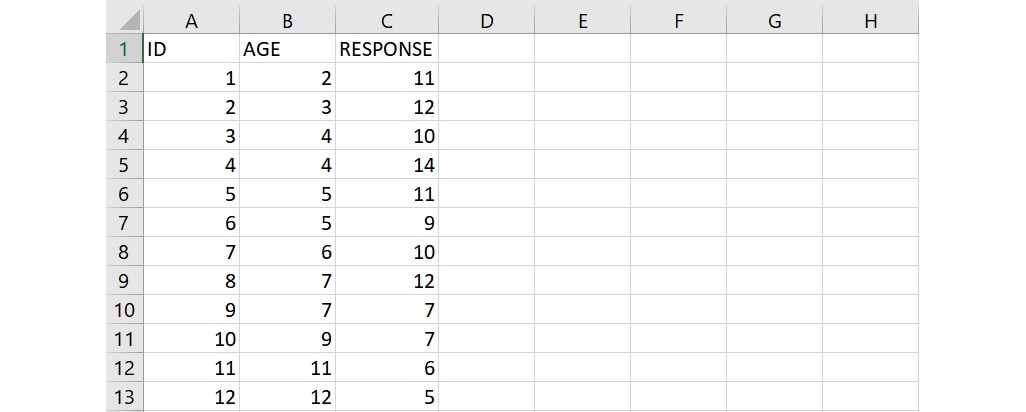
資料輸入完成後,在儲存格E5或任一空白的儲存格從上至下輸入 N、p、mean_X、devsq_X、s_e、t_critical,這6個名稱代表的數值分別為:
- N:樣本總數;
- p:預測區間的機率值;
- mean_X:自變項的平均數;
- devsq_X:自變項的離差平方和;
- s_e:最小平方迴歸線的估計標準誤;
- t_critical:t臨界值。
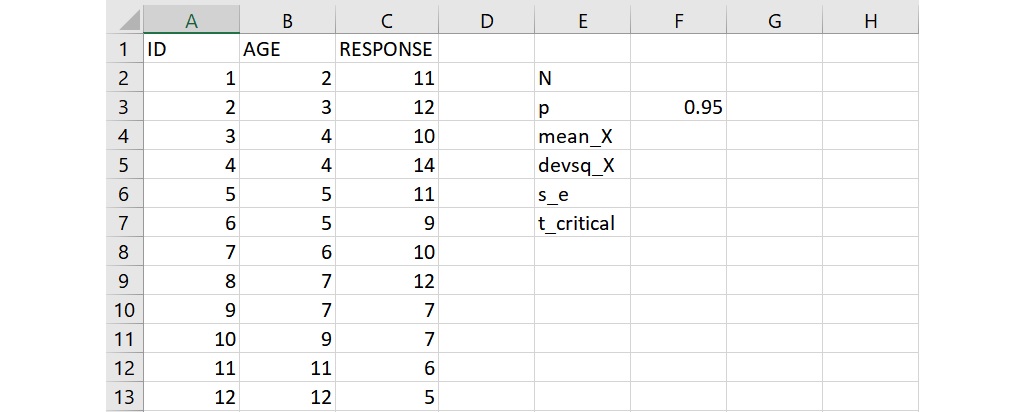
這6個數值為預測區間計算所需要的數值,而這裡面唯一不須使用函數就可以知道的數值為預測區間的機率值 p,因為要求得95%的預測區間,所以在 p 右邊的儲存格F3輸入0.95。
COUNT 函數計算樣本數
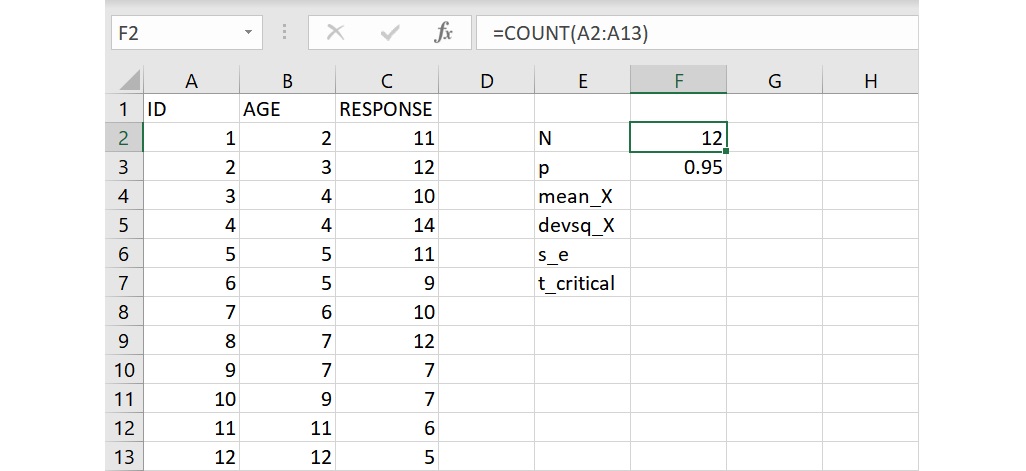
若要計算樣本總數,或是說帶有數值的儲存格數目,可以使用 COUNT 函數。雖然這裡的例子可以很輕易地看出樣本數,但當樣本數較大而無法一眼看出,或沒有參與者編碼變項的時候,使用這函數來計算會相對地輕鬆。在 N 右邊的儲存格F2裡輸入下面的語法:
=COUNT(A2:A13)
語法裡面的引數 A2:A13 指從儲存格A2到儲存格A13,整個語法要求計算出從儲存格A2到A13裡帶有數值的儲存格數目。語法輸入完成後,按下 Enter 會傳回數值12,代表樣本數為12。若您想瞭解其他數目計算的函數,可以參考如何使用 Excel 計算數目。
除了直接在儲存格裡輸入語法或公式外,也可以點選儲存格後,在資料編輯列或公式欄(formula bar)輸入語法或公式。
不論是在儲存格或資料編輯列輸入語法或公式,計算結果都會顯示在儲存格裡,您可以選擇自己喜歡或習慣的方式來操作喔!
AVERAGE 函數計算平均數
若要計算一組資料的算數平均數,可以使用 AVERAGE 函數。因為這裡要求得自變項 AGE 的平均數,所以在 mean_X 右邊的儲存格F4或資料編輯列裡輸入下面的語法:
=AVERAGE(B2:B13)
語法裡的引數 B2:B13 指從儲存格B2到儲存格B13,也就是自變項的資料範圍,整個語法要求計算自變項 AGE 的平均數。語法輸入完成後,按下 Enter 會傳回數值6.25,代表這12位孩童的平均年齡為6.25歲。
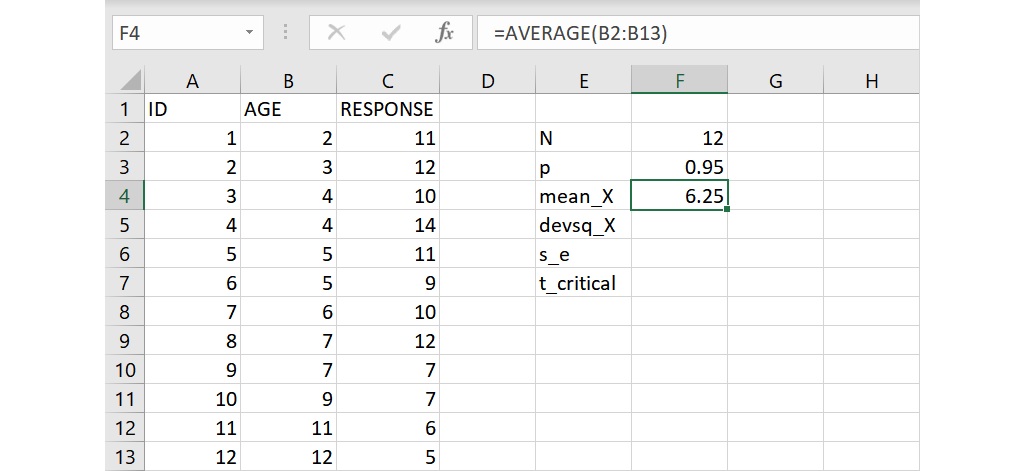
使用 AVERAGE 函數的時候,若資料範圍裡有文字或空白的儲存格,那些儲存格將不會被列入計算。另外,若儲存格的數值為0時,這個儲存格會被視為資料範圍的一部分而列入平均數的計算。
DEVSQ 函數計算離差平方和
若要求得離差平方和,也就是一個變項裡每一個數值和平均數的差值平方後的總和,可以使用 DEVSQ 函數。這裡要取得自變項的離差平方和,因此在 devsq_X 右邊的儲存格F5或資料編輯列裡輸入下面的語法:
=DEVSQ(B2:B13)
這語法要求計算位於儲存格B2到B13的自變項 AGE 的離差平方和,輸入完成後按下 Enter 會傳回數值106.25,代表年齡的離差平方和為106.25。
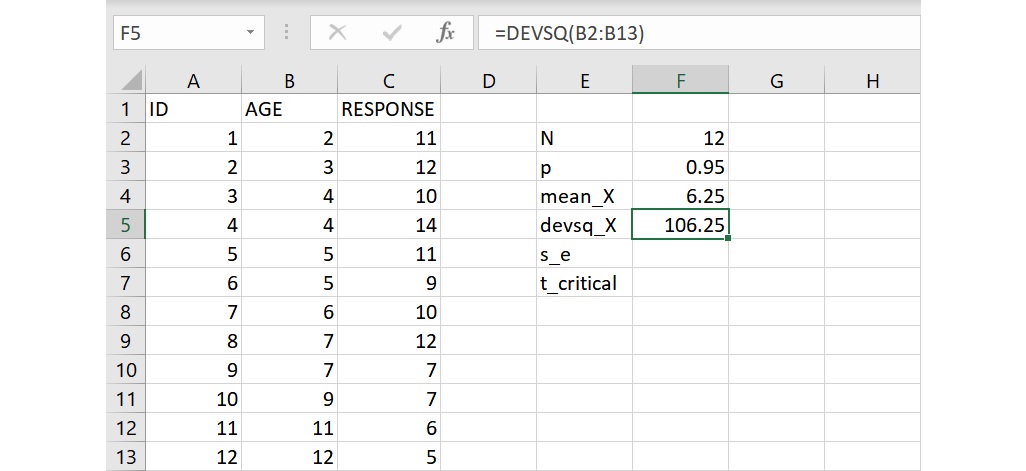
和上面的 AVERAGE 函數一樣,文字或空白的儲存格不會被列入計算,但數值為0的儲存格會被視為資料而列入離差平方和的計算。
STEYX 函數計算估計標準誤
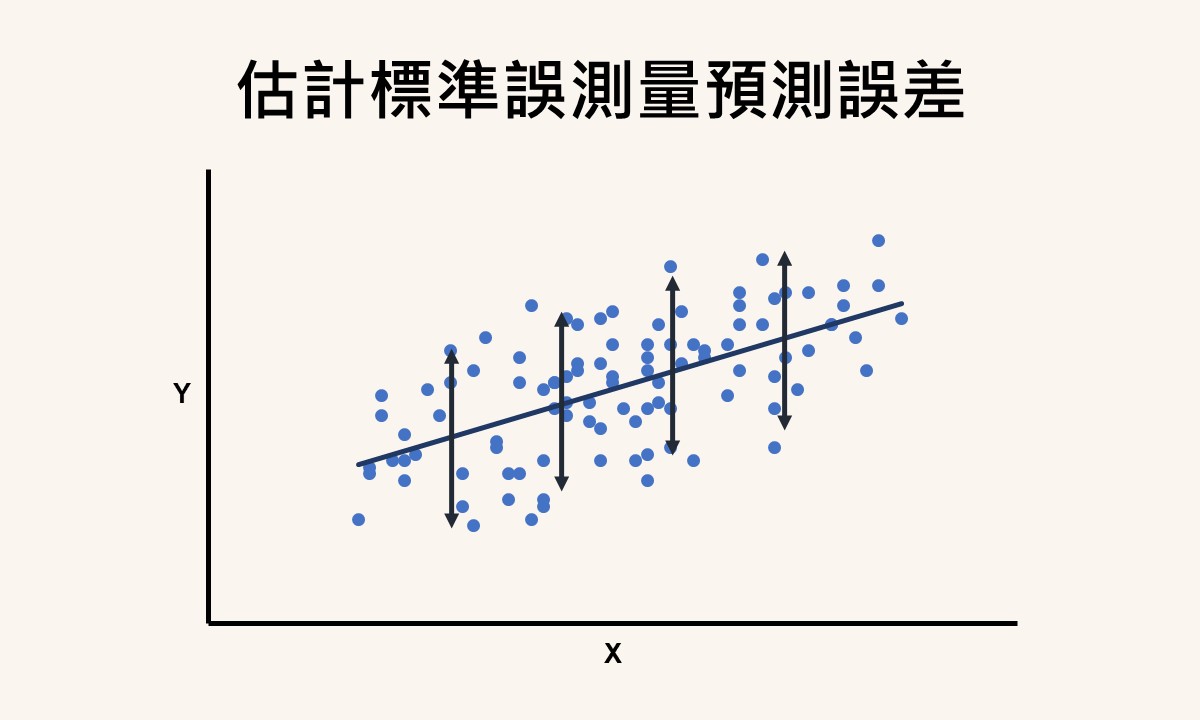
若要求得最小平方迴歸線的估計標準誤,也就是整體預測誤差的測量值,可以使用 STEYX 函數。使用這個函數時,須分別寫出依變項和自變項的資料範圍,在 s_e 右邊的儲存格F6或資料編輯列裡輸入下面的語法:
=STEYX(C2:C13, B2:B13)
語法裡 C2:C13 指依變項的資料範圍而 B2:B13 為自變項的資料範圍,整個語法要求計算以年齡 AGE 預測不相關回應次數 RESONSE 的最小平方迴歸線的估計標準誤。語法輸入完成後,按下 Enter 會傳回數值1.671(四捨五入至小數點後第3位),此即為這條迴歸線的估計標準誤。
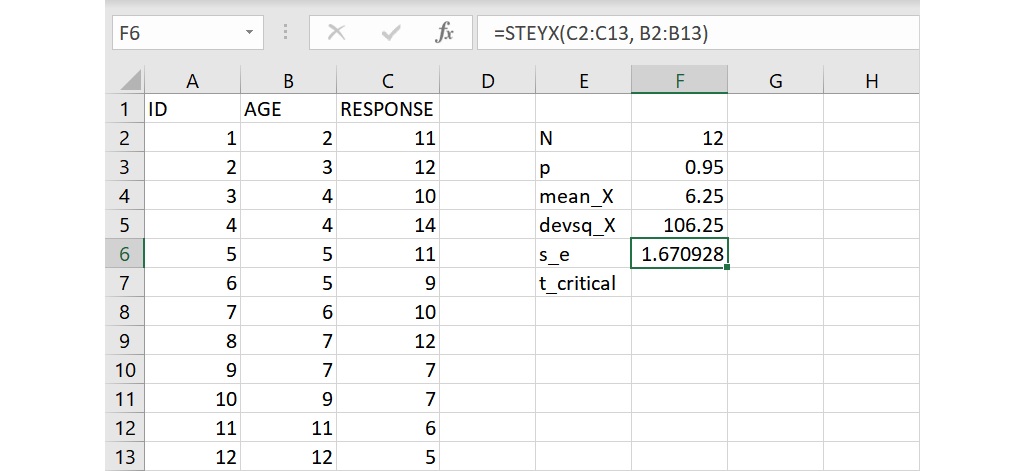
和上面的函數相同,帶有文字或空白的儲存格不會被列入計算,但數值為0的儲存格會被視為資料而列入計算。另外,如果兩變項的資料個數不一致時,例如依變項的資料範圍為儲存格C2到C10但自變項的資料範圍為B2到B9,STEYX 函數會傳回「#N/A」 的錯誤訊息。
T.INV.2T 函數取得t臨界值
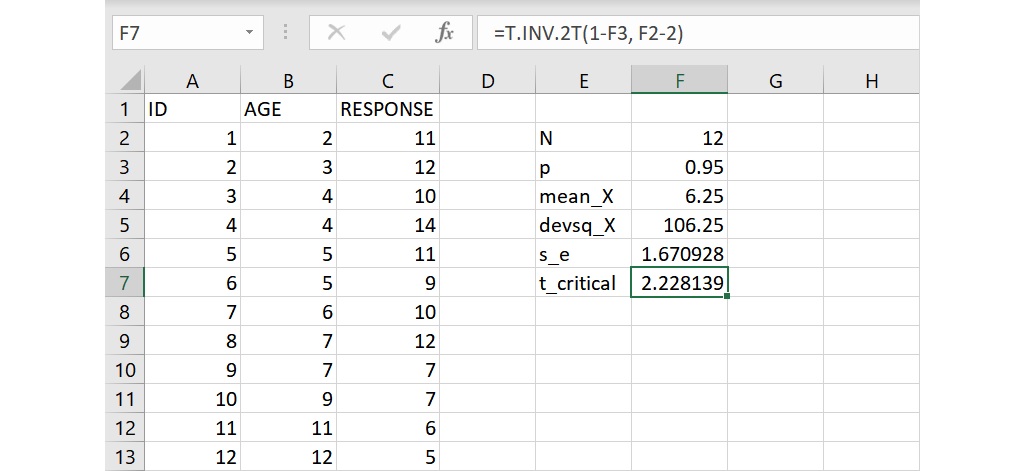
預測區間的計算須使用到t分配和t臨界值,利用 T.INV.2T 函數可以省去查表的麻煩,直接取得雙尾檢定的t臨界值。使用這函數時須寫出機率和自由度,機率為1減去預測區間機率 p 而自由度為樣本數 N 減去2,在 t_critical 右邊的儲存格F7或資料編輯列裡輸入下面的語法:
=T.INV.2T(1-F3, F2-2)
儲存格F3為預測區間的機率而儲存格F2為樣本總數,透過這樣的語法,可得到機率為0.05且自由度為10的雙尾檢定t臨界值,數值為2.228(四捨五入至小數點後第3位)。若您不太清楚t分配和t臨界值的概念,請參考小樣本或σ未知的信賴區間之計算。
透過上面的方法取得了樣本數、自變項的平均數、自變項的離差平方和、最小平方迴歸線的估計標準誤和t臨界值後,就可開始預測區間的計算。在儲存格H1或任一空白的儲存格,從左至右分別輸入 X、pred_Y、pred_se、lower_PI、upper_PI,這5個名稱代表的數值分別為:
- X:想預測依變項結果的自變項數值;
- pred_Y:利用最小平方迴歸線計算出來的依變項預測值;
- pred_se:個別預測的標準誤;
- lower_PI:預測區間的下限;
- upper_PI:預測區間的上限。
由於這裡要預測年齡為8歲和10歲孩童在問題解決時不相關的回應次數,所以先在上圖 X 下方的2個儲存格分別輸入8和10。利用最小平方迴歸線進行預測可使用 FORECAST.LINEAR 函數,而個別預測的標準誤和預測區間須運用上面已得到的6個數值來計算,下面分別示範操作方法。
FORECAST.LINEAR 函數求得依變項的預測值
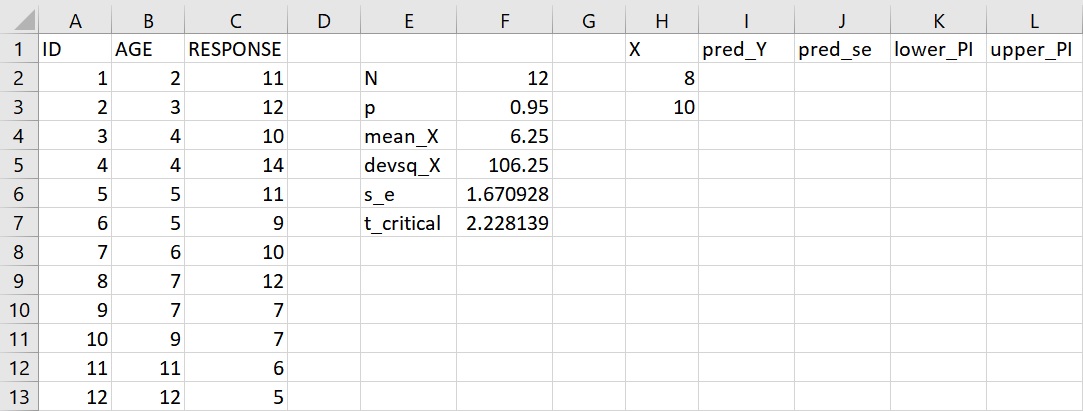
最小平方迴歸線可作為預測的用途,帶入已知的自變項數值,即可獲得依變項的預測值。這個預測的過程可以簡單地利用 FORECAST.LINEAR 函數來達成,只需要指出想探討的自變項數值、依變項和自變項的資料範圍即可。在年齡為8的右邊、pred_Y 下方的儲存格I2或資料編輯列裡輸入下面的語法:
=FORCAST.LINEAR(H2, C$2:C$13, B$2:B$13)
引數 C$2:C$13 指把儲存格固定在C2到C13的位置而 B$2:B$13 指把儲存格固定在B2到B13的位置,若複製這語法至其他的儲存格,依變項和自變項的資料範圍不會改變。整個語法要求建構一條以 AGE 預測 RESPONSE 的最小平方迴歸線,並利用這條迴歸線預測8歲孩童的不相關回應次數。這語法傳回數值8.24,代表8歲孩童在問題解決時的不相關回應次數預測值為8.24次。
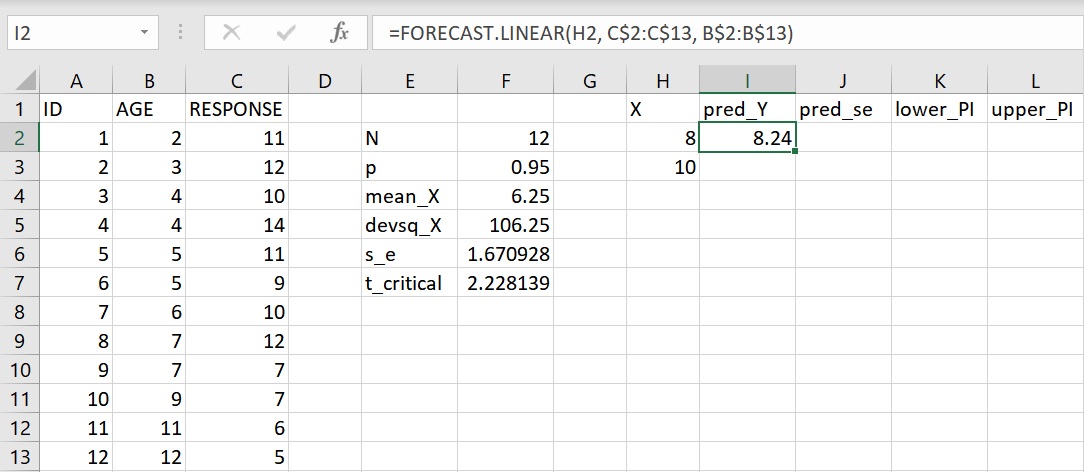
利用相同的方法來預測10歲孩童的不相關回應次數,複製儲存格I2並貼上至儲存格I3,想探討的自變項數值會自動變成儲存格H3的10歲,但依變項和自變項的資料範圍仍維持不變,得到的數值為6.80,代表10歲孩童在問題解決時的不相關回應次數預測值為6.80次。
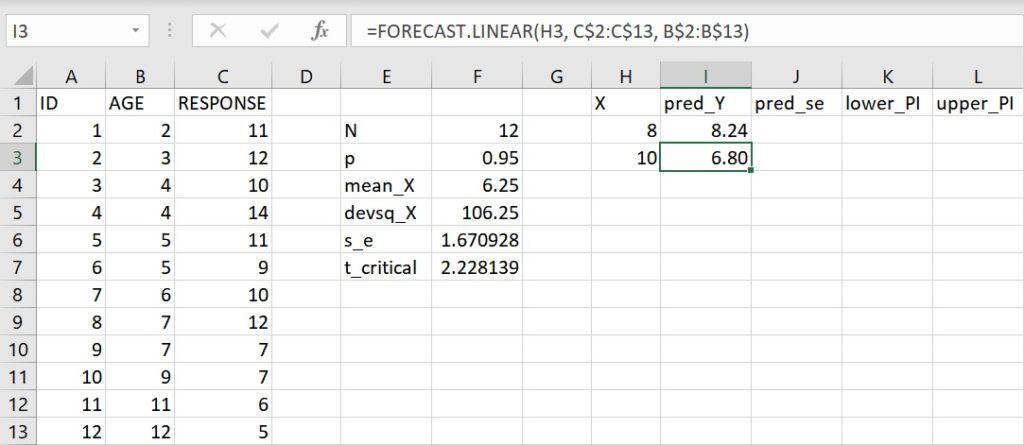
使用這個函數時,若依變項和自變項的資料個數不一致的時候,會傳回「#N/A」的錯誤訊息。另外,當想探討的自變項數值不是數值而是文字的時候,會傳回「#VALUE!」的錯誤訊息。
運用公式計算個別預測的標準誤
個別預測的標準誤沒有函數可以使用,必須利用上面已經求得的數值來計算。個別預測的標準誤公式如下:
![\[ \mathsf {pred\_se = s\_e \sqrt {1+\frac {1}{N}+\frac {(X-mean\_X)^2}{devsq\_X}}} \]](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-b06284c5c357c3c6faacef08468bf256_l3.png "Rendered by QuickLaTeX.com")
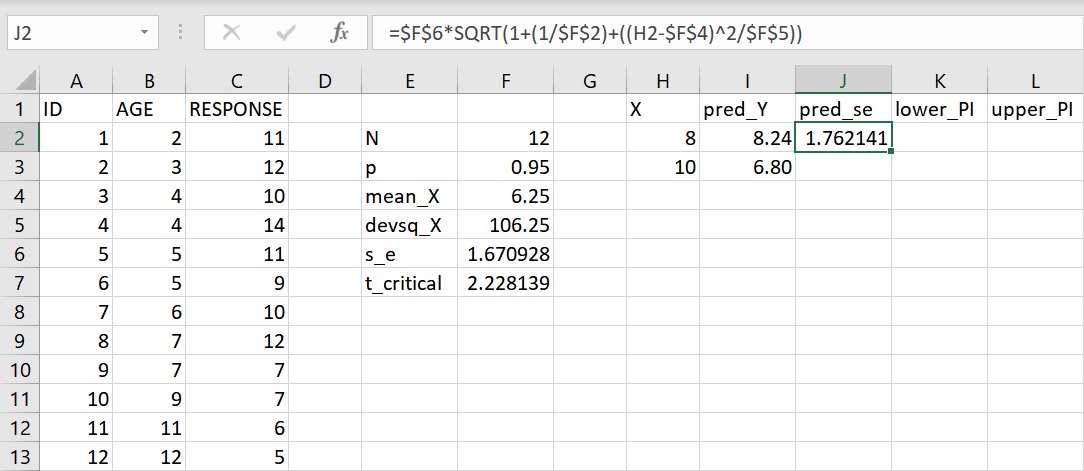
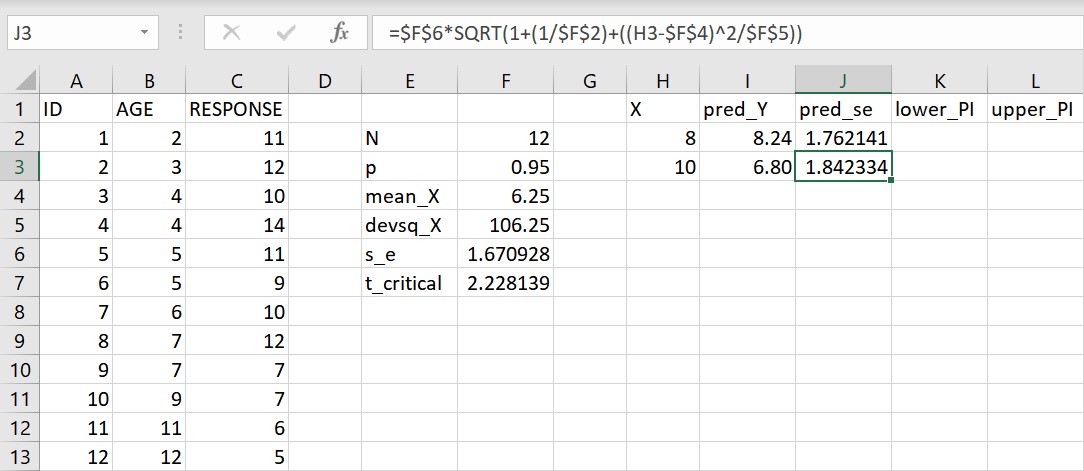
參考上面的個別預測的標準誤公式,把相關的數值帶入公式裡並輸入至儲存格J2或資料編輯列裡,完整的語法如下:
=$F$6*SQRT(1+(1/$F$2)+((H2-$F$4)^2/$F$5))
引數 $F$6 代表把儲存格固定在F6的位置,其他使用到「$」符號的儲存格都可以做相同的解釋。SQRT 是開根號的函數,而「^2」指將數值平方。公式輸入完成後,傳回數值1.762(四捨五入至小數點後第3位),代表年齡8歲的個別預測標準誤為1.762。
利用相同的方法來計算年齡10歲的個別預測標準誤,複製儲存格J2並貼上至儲存格J3。從資料編輯列的公式可以看到,除了 X 值從儲存格H2變成H3之外,其他數值的儲存格位置都維持不變。這公式傳回數值1.842(四捨五入至小數點後第3位),此即為年齡10歲的個別預測標準誤。
不論是透過公式或函數,在工作表裡可以直接進行數學計算,若您不清楚應用的方法,可以參考如何使用 Excel 進行數學計算【基礎篇】和如何使用 Excel 進行數學計算【進階篇】。
運用公式計算預測區間
在求得依變項的預測值 pred_Y 和個別預測的標準誤 pred_se 之後,就可計算出各個自變項的依變項預測區間。預測區間的公式如下:
![\[ \mathsf {PI = pred\_Y \pm (t\_critical \times pred\_se)} \]](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-3ee883e705ef7c0342266446d22fbbd9_l3.png "Rendered by QuickLaTeX.com")
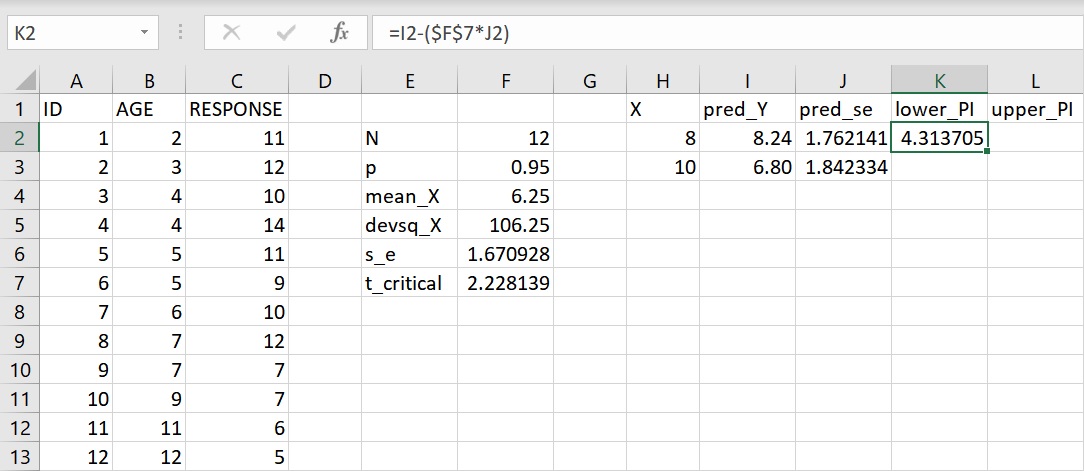
先計算年齡8歲的預測區間下限,在 lower_PI 下方的儲存格K2或資料編輯列輸入下面的語法:
=I2-($F$7*J2)
引數 $F$7 指把t臨界值固定在儲存格F7的位置,以利之後公式的複製與貼上。這語法傳回數值4.314(四捨五入至小數點後第3位),為8歲孩童的不相關回應次數的預測區間下限。
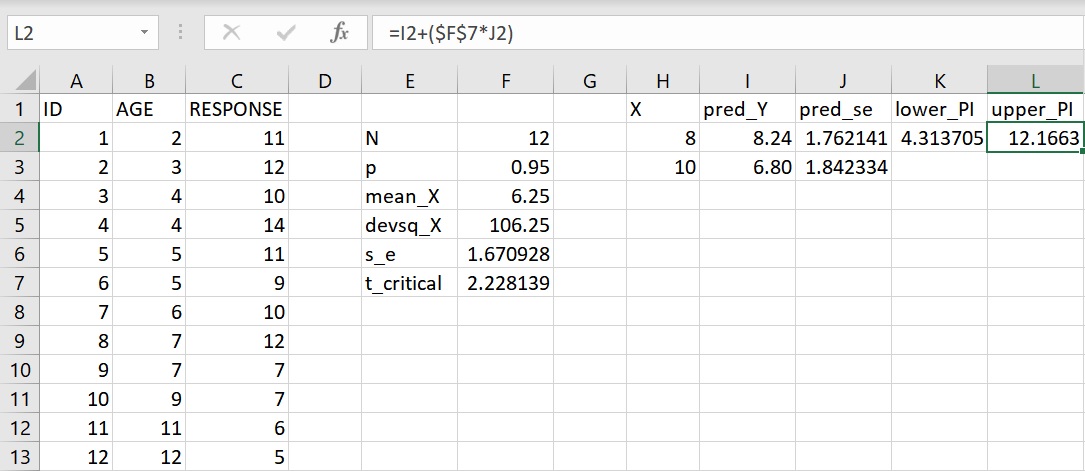
然後計算8歲孩童的預測區間上限,在 upper_PI 下方的儲存格L2或資料編輯列輸入下面的語法:
=I2+($F$7*J2)
這語法傳回數值12.166(四捨五入至小數點後第3位),即為8歲孩童的預測區間上限。從計算結果可以看出,8歲孩童在問題解決時不相關的回應次數會介於4.313次到12.166次之間。
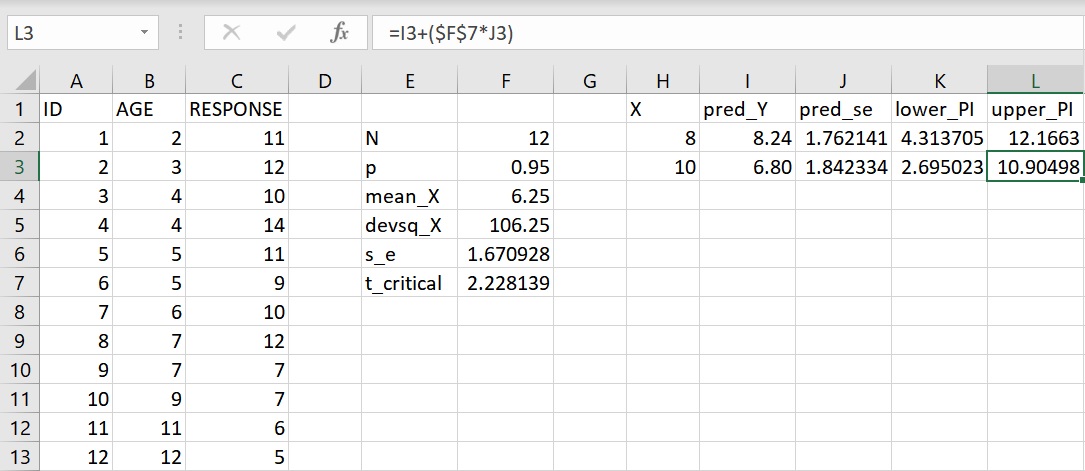
利用相同的方法來計算10歲孩童的不相關回應次數預測區間,複製K2儲存格公式並貼上至儲存格K3,再複製儲存格L2公式並貼上至儲存格L3,就可以得到10歲孩童的預測區間下限和上限。若把所有的數值四捨五入至小數點後第3位,計算結果指出10歲孩童在問題解決時不相關的回應次數會介於2.695次和10.905次之間。
使用 Excel 計算最小平方迴歸線的預測區間雖然比較麻煩,過程中牽涉到許多函數,但這些函數都很實用,即使沒有用在預測區間的計算,也可應用在其他相關的統計分析上。使用這些函數前,務必正確地輸入資料至活頁簿或工作表裡,且指明兩變項的資料範圍時也要注意資料個數是一致的狀態,因為只有在資料無誤的情況下才能獲得正確的輸出結果。
以上為本篇文章對如何使用 Excel 計算最小平方迴歸線預測區間的介紹,希望透過本篇文章,您學會了最小平方迴歸線預測區間的計算過程中所運用到的函數與這些函數的操作方法。若您喜歡本篇文章,請將本網站加入書籤,並持續回訪本網站喔!另外,也歡迎您追蹤本網站的 Facebook 和/或 X(Twitter) 專頁喲!
如果您覺得本篇文章對您有幫助,歡迎買杯珍奶給 Dr. Fish!小小珍奶,大大鼓勵,您的支持將給 Dr. Fish 更多撰寫優質文章的動力喔!