🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
單因子變異數分析的事後比較
獨立群組的單因子變異數分析(以下直接稱「單因子變異數分析」)的假設檢定結束後,若分析結果為拒絕虛無假設,代表自變項整體有效果,但這結果並沒有指出自變項的哪些群組間有顯著的不同。顯著的F值只告訴我們至少有一個群組不同於另一個群組,但實際上群組之間到底如何地不同則須透過單因子變異數分析的事後比較才能知道。
事後比較(a posteriori comparisons 或 post hoc comparisons)屬於一種非計畫性的比較,研究人員通常是在單因子變異數分析的假設檢定後,視綜合檢定(omnibus test)的F值是否達到統計上顯著再決定是否進行群組間的比較。這一點有別於事前比較(a priori comparisons),是在單因子變異數分析執行前就擬定好群組之間如何不同的對立假設,屬於一種計畫性的比較。
事後比較是進行數個群組和群組間的成對樣本比較,類似於數個獨立樣本t檢定的執行。不過數個成對樣本的比較會增加第一類型錯誤的機率,也就是拒絕真實的虛無假設,所以事後比較必須控制這個膨脹的錯誤率,稱為實驗錯誤率(experimentwise error rate)。
事後比較的檢定方法有很多種,大多數都會控制實驗錯誤率,且採用Student化全距統計量和Student化全距分配(Studentized range distribution),符號為 。另外,也有沒有採用Student化全距統計量和全距分配的事後比較方法,例如Scheffé檢定、Dunnett檢定。
。另外,也有沒有採用Student化全距統計量和全距分配的事後比較方法,例如Scheffé檢定、Dunnett檢定。
本篇文章將以Student化全距統計量為基礎的事後比較為主,介紹Tukey HSD、Newman-Keuls和REGWQ等3個較常用的事後比較方法。由於本篇文章牽涉假設檢定和單因子變異數分析,建議您先閱讀假設檢定的步驟和範例、單因子變異數分析的假設檢定,將有助於以下內容的理解喔。
Student化全距統計量
當執行單一的獨立樣本t檢定時,研究人員將願意犯下第一類型錯誤的機率設定為α,代表拒絕虛無假設時願意承擔錯誤的機率,這個機率稱為比較錯誤率(comparisonwise error rate)。但是,當執行多個獨立樣本t檢定時,犯下第一類型錯誤的機率會高於α,這時的錯誤稱為實驗錯誤率,更近期的名稱為族系錯誤率(familywise error rate)。這兩種錯誤之間的關係為:

上面的公式裡,α指比較錯誤率,c指成對比較的數目。假設在單一實驗裡要進行5個成對比較且成對比較的α為0.05時,實驗錯誤率為 ,這數值代表犯下第一類型錯誤的機率為0.226,也就是說,有22.6%的機會研究人員會拒絕一個或數個真實的虛無假設。
,這數值代表犯下第一類型錯誤的機率為0.226,也就是說,有22.6%的機會研究人員會拒絕一個或數個真實的虛無假設。
為了避免這種膨脹的第一類型錯誤機率,事後比較的檢定採用Student化全距統計量和Student化全距抽樣分配。讓 和
和 分別代表數值最大和最小的平均數、
分別代表數值最大和最小的平均數、 指自變項裡群組的數目、
指自變項裡群組的數目、 指組內變異數估計值、
指組內變異數估計值、 為各組的分數個數,在各組的分數個數都相同的情況下,Student化全距統計量的公式如下:
為各組的分數個數,在各組的分數個數都相同的情況下,Student化全距統計量的公式如下:
(1) 
Student化全距抽樣分配是從一個母群體中隨機抽取出個數為的 個樣本,計算出數值最大的平均數和數值最小的平均數間的差值後,再除以
個樣本,計算出數值最大的平均數和數值最小的平均數間的差值後,再除以 ,藉由這樣的過程產生Student化全距抽樣分配。這個抽樣分配和t抽樣分配很相似,只是t抽樣分配僅能用在單一成對樣本的比較上,而Student化全距抽樣分配可用在多個成對樣本的比較上。
,藉由這樣的過程產生Student化全距抽樣分配。這個抽樣分配和t抽樣分配很相似,只是t抽樣分配僅能用在單一成對樣本的比較上,而Student化全距抽樣分配可用在多個成對樣本的比較上。
利用上面的公式(1)求得Student化全距統計量之後,透過被比較的平均數數目、組內自由度 與顯著水準(α水準),查詢Student化全距分配臨界值表,決定的臨界值。若計算出來的統計量等於或大於臨界值,即可拒絕虛無假設,接受對立假設,代表被比較的平均數間確實存在差異;反之,則保留虛無假設。
與顯著水準(α水準),查詢Student化全距分配臨界值表,決定的臨界值。若計算出來的統計量等於或大於臨界值,即可拒絕虛無假設,接受對立假設,代表被比較的平均數間確實存在差異;反之,則保留虛無假設。
瞭解了Student化全距統計量和Student化全距分配後,下面介紹使用這種統計量來進行事後比較的3種檢定方法,分別為Tukey HSD檢定、Newman-Keuls檢定和REGWQ檢定。
Tukey HSD檢定
Tukey HSD檢定的全名為Tukey honestly significant difference test,是一種很常被使用且很受歡迎的事後比較檢定。Tukey HSD檢定是把實驗錯誤率維持在α的情況下,進行所有可能的成對樣本比較。這個檢定使用下面的公式計算統計量:
(2) 

從公式(2)可以看出,計算統計量時,會使用較大的平均數減較小的平均數,所以統計量永遠是正數。另外,上面公式(1)裡的在Tukey HSD檢定裡等於,就是群組的數目,也就是被比較的平均數個數。透過或、組內自由度和α水準,查詢Student化全距分配臨界值表,決定臨界值。比較統計量和臨界值,若統計量等於或大於臨界值,即可拒絕虛無假設,接受對立假設。
在單因子變異數分析的假設檢定裡不同治療方法和輕度憂鬱症治療效果的例子,因為分析結果顯示F值達到統計上顯著,代表不同治療方法確實影響輕度憂鬱症的治療效果,所以可進一步執行事後比較,判斷哪些治療方法之間具有不同的效果。下表為這個例子裡3種不同治療方法的平均數、總平均數和參與人數,而這個研究的組內自由度為12、組內變異數估計值為1.9。

利用上表的資訊來執行Tukey HSD檢定,因為有3種治療方法,所以會有3組的成對比較:relax和talk、placebo和relax、placebo和talk。首先,使用公式(2)來計算3組成對比較的統計量,計算過程如下:

接著,透過Student化全距分配臨界值表尋找臨界值。在這個研究裡,群組的數目(也就是被比較的平均數數目)為3、組內自由度為12、事先設定的α水準為0.05,在 、
、 、
、 時,臨界值為3.773。
時,臨界值為3.773。
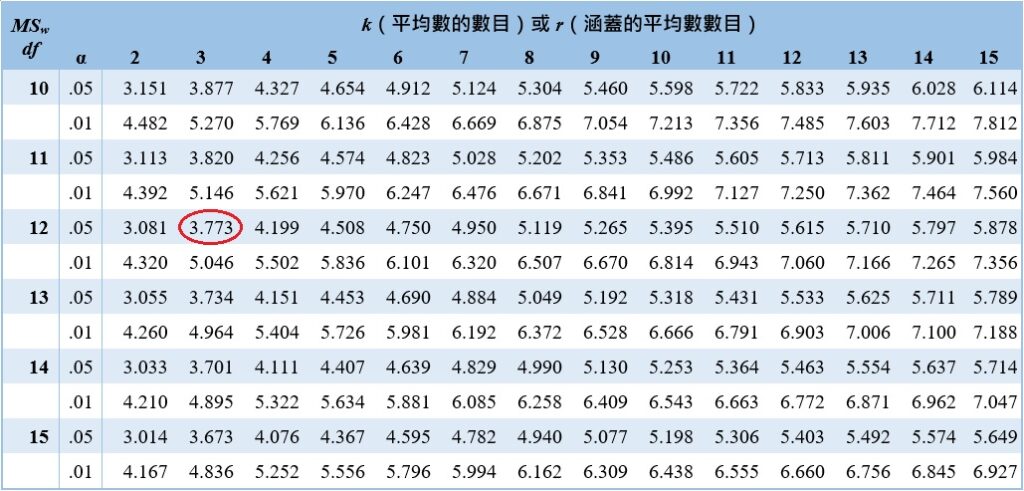
比較3個統計量和臨界值,只有placebo和talk這組的統計量大於臨界值( ),其他兩組的統計量都小於臨界值,這結果指出談話治療明顯較安慰劑控制的效果來得好。
),其他兩組的統計量都小於臨界值,這結果指出談話治療明顯較安慰劑控制的效果來得好。
Newman-Keuls檢定
第2種很常被使用的事後比較檢定為Newman-Keuls檢定,也稱為Student-Newman-Keuls檢定,同樣是用來進行自變項裡所有可能的成對比較。這個檢定和Tukey HSD檢定一樣,先計算出各組成對比較的統計量,再和臨界值比較,進而評估是否拒絕虛無假設。但是,Newman-Keuls檢定不像Tukey HSD檢定把實驗錯誤率控制在α,而是把成對比較錯誤率維持在α。
由於Newman-Keuls檢定把比較錯誤率維持在α,所以每一組成對比較的臨界值都不相同。執行這個檢定時,須先將被比較的平均數從小至大排序,再依據被比較的兩個平均數所涵蓋的平均數個數來決定的數值。也就是說,Newman-Keuls檢定裡的會受到被比較的平均數的影響,而持續地調整的數值。
同樣使用不同治療方法和輕度憂鬱症治療效果的例子,利用Newman-Keuls檢定來進行事後比較。首先,將3種治療方法的平均數從小至大排序,如下表。

因為有3種治療方法,所以會有3組成對比較,分別為placebo和talk、placebo和relax、relax和talk。接著,和Tukey HSD檢定一樣,利用上面的公式(2)計算出3組的統計量,計算過程如下:

得到3組的統計量後,再查詢Student化全距分配臨界值表,決定各組的臨界值。Newman-Keuls檢定的臨界值須依據兩個被比較的平均數所涵蓋的平均數個數來決定,變動的數值為,不變的數值為組內自由度和α水準。這3組的臨界值分別為:
- placebo vs. talk:placebo和talk間涵蓋了3個平均數(參考上表),所以
 。當、、時,臨界值為3.773。
。當、、時,臨界值為3.773。 - placebo vs. relax:placebo和relax間涵蓋了2個平均數,所以
 。當、、時,臨界值為3.081。
。當、、時,臨界值為3.081。 - relax vs. talk:relax和talk間涵蓋了2個平均數,所以。當、、時,臨界值為3.081。
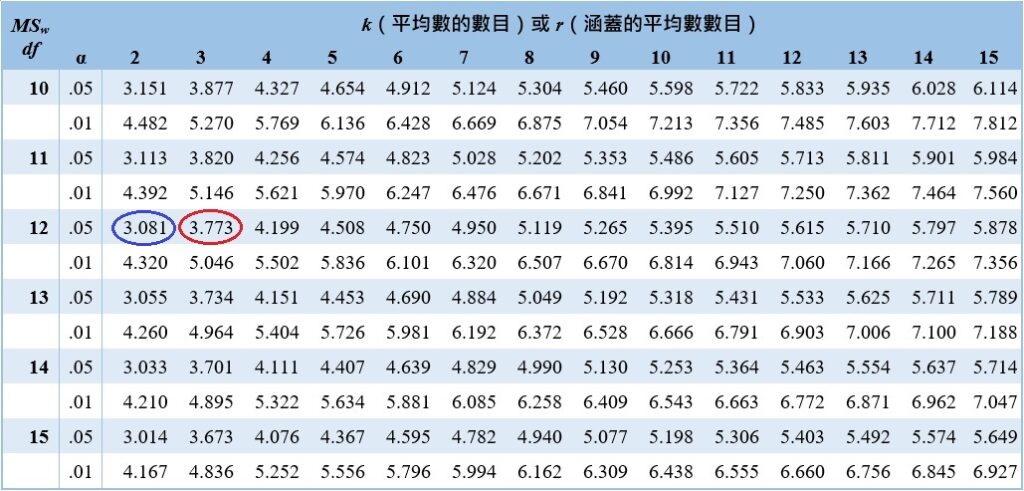
最後,比較各組的統計量和相對應的臨界值,結果顯示placebo和talk、relax和talk這兩組的統計量大於臨界值。也就是說,談話治療明顯較安慰劑控制的效果來得好;此外,談話治療也明顯地較放鬆治療來得有效果。原本在Tukey HSD檢定裡沒有達到顯著的relax和talk組,在Newman-Keuls檢定裡則達到顯著。

比較Tukey HSD和Newman-Keuls這兩種事後比較的檢定可以發現,Tukey HSD檢定不管成對比較的數目,都把實驗錯誤率控制在α,Newman-Keuls檢定則允許實驗錯誤率隨著成對比較的數目增多而增加。因此,Tukey HSD檢定雖然控制了第一類型的錯誤卻降低了檢定力,而Newman-Keuls雖然提高了檢定力卻增加了第一類型錯誤的機率。
REGWQ檢定
Tukey HSD和Newman-Keuls檢定雖然都是很常用到的事後比較檢定,但有各自的優缺點,其中尤以Newman-Keuls檢定受到的批評最多,因為這個檢定的第一類型錯誤機率會隨著成對比較的數目變多而增加。為了尋找折衷方案,讓實驗錯誤率可以維持在α但又不降低事後比較的檢定力,Ryan, Einot, Gabriel, & Welsch發展出REGWQ檢定。
REGWQ檢定同樣使用Student化全距統計量和Student化全距分配,並且保留了Tukey HSD和Newman-Keuls檢定各自的優點,不但讓整體的實驗錯誤率維持在α,也讓臨界值隨著每一成對比較所涵蓋的平均數個數而有不同。為了把實驗錯誤率控制在α,取得臨界值的α水準(用符號 表示)須因應成對比較涵蓋的平均數個數和群組的組數做如下的調整(Welsch, 1977):
表示)須因應成對比較涵蓋的平均數個數和群組的組數做如下的調整(Welsch, 1977):
- 當
 或
或 ,
, 。
。 - 當
 ,
, 。
。
透過這樣的α水準調整,不但能夠讓整體的實驗錯誤率維持在α,還能夠提升事後比較的統計檢定力。不過很可能會是奇怪的小數,例如群組的組數為5、涵蓋的平均數個數為3且α水準為0.05時,因為,所以 。這α水準已經不是慣用的0.05或0.01,因此很難利用Student化全距分配臨界值表去找到正確的臨界值,而須借用統計軟體的運算。
。這α水準已經不是慣用的0.05或0.01,因此很難利用Student化全距分配臨界值表去找到正確的臨界值,而須借用統計軟體的運算。
以不同治療方法和輕度憂鬱症治療效果的例子來看,群組的組數為3且涵蓋的平均數個數為2或3,因為或,所以 。也就是說,在這個例子裡,所有成對比較的α水準皆為0.05,利用REGWQ檢定的結果和利用Newman-Keuls檢定的結果是相同的。由此可見,REGWQ檢定不但將實驗錯誤率控制在α,而且比Tukey HSD檢定更具統計檢定力。
。也就是說,在這個例子裡,所有成對比較的α水準皆為0.05,利用REGWQ檢定的結果和利用Newman-Keuls檢定的結果是相同的。由此可見,REGWQ檢定不但將實驗錯誤率控制在α,而且比Tukey HSD檢定更具統計檢定力。
總結來說,上面介紹的3種單因子變異數分析事後比較的檢定方法雖然都使用Student化全距統計量和Student化全距分配,但對實驗錯誤率的控制卻不盡相同。Tukey HSD檢定把實驗錯誤率維持在α,而Newman-Keuls檢定把比較錯誤率維持在α,REGWQ檢定則擷取Tukey HSD和Newman-Keuls檢定的優點(見下表)。

這3種事後比較的檢定都可利用SPSS或SAS來執行,若您有任一軟體,建議可優先選擇REGWQ檢定,因為這個檢定不僅把實驗錯誤率維持在α,而且統計檢定力較Tukey HSD檢定來得高。下面就來示範運用SPSS執行這3種事後比較檢定的操作方法。
運用SPSS執行單因子變異數分析的事後比較
將不同治療方法和輕度憂鬱症治療效果例子的資料輸入至SPSS資料編輯器裡,輸入完成後,點選功能表的分析 » 比較平均數 » 單因數變異數分析,帶出「單因子變異數分析」視窗。關於SPSS的資料輸入方法,請參考SPSS操作環境和資料輸入。
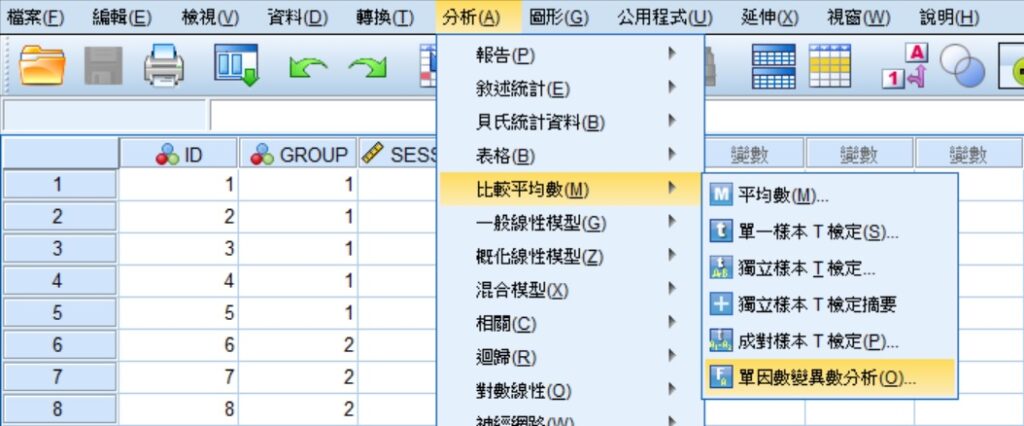
在「單因子變異數分析」視窗裡,將依變項SESSION移至依變數清單(E),自變項GROUP移至因子(F),然後點選視窗右邊的事後(H),會出現「單因子變異數分析:事後多重比較」視窗。在這個視窗的假設相等的變異方框中,勾選R-E-G-W Q、S-N-K(就是Newman-Keuls檢定)、Tukey這3個選項,完成後點選視窗下方的繼續(C)。回到上一視窗後,再點選確定。
經過上面的步驟後,SPSS會輸出3個表格。第1個表格為「變異數分析」表,為單因子變異數分析的分析結果,這部分的相關說明請參考單因子變異數分析的假設檢定。
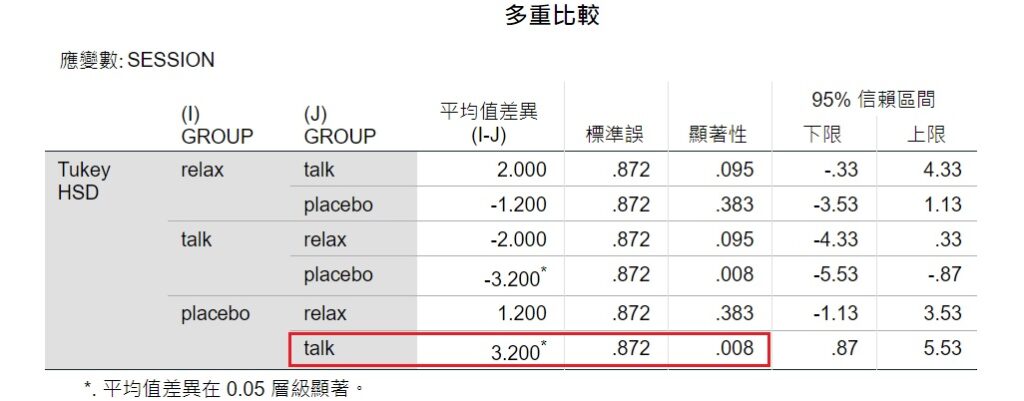
第2個表格為「多重比較」表,顯示Tukey HSD檢定的結果。這表格列出研究裡所有可能的成對比較,從這些成對比較裡可發現僅有placebo和talk這兩群組間達到統計上顯著,即是談話治療和安慰劑控制的效果有明顯差異,這結果和上面紙筆計算的結果是相同的。
第3個表格為其他事後比較檢定的分析結果。這個表格列出各個事後比較檢定裡沒有達到統計上顯著的成對比較,例如Newman-Keuls檢定的結果指出relax和placebo的顯著性為0.194,因為大於0.05,所以沒有達到統計上顯著,顯示放鬆治療和安慰劑控制之間的效果沒有存在差異。
換句話說,talk和relax、talk和placebo這兩組成對比較達到統計上顯著,代表談話治療和放鬆治療的效果有明顯差異,而談話治療和安慰劑控制的效果也有明顯差異。另外,從下表也可看出Newman-Keuls檢定和REGWQ檢定的結果是一樣的,這些分析結果和上面紙筆計算的結果都是相同的。
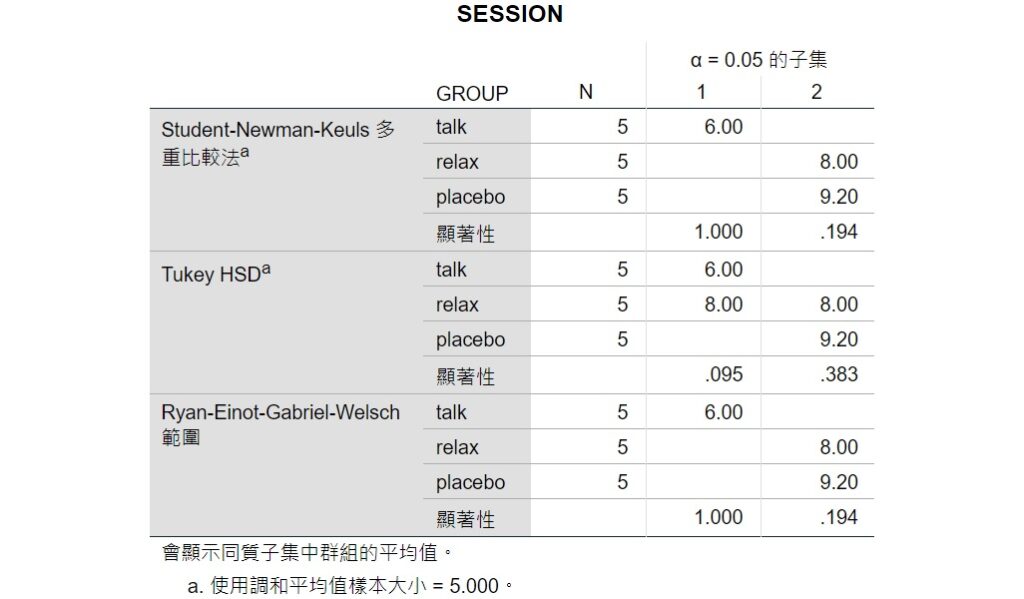
上表有個地方要注意一下,表格下方的註解「使用調和平均值樣本大小 = 5.000」指出SPSS使用調和平均數(harmonic mean)進行事後比較的檢定。若各個群組的樣本數不相等,使用調和平均數來取代各個群組的樣本數能夠減少樣本數不相等所造成的偏誤。讓為群組的組數、 為第組的個數,調和平均數
為第組的個數,調和平均數 的公式如下:
的公式如下:
![\[ \overline X_h=\frac {k}{\dfrac {1}{n_1}+\dfrac {1}{n_2}+\dfrac {1}{n_3}+\cdots+\dfrac {1}{n_k}} \]](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-5848e4fae78b98d88b78ef909e772ce8_l3.png "Rendered by QuickLaTeX.com")
以不同治療方法和輕度憂鬱症治療效果的例子來看,因為每個群組的個數皆為5,所以調和平均數也是5。運用上面的公式示範計算過程:
![\[\overline X_h = \frac {k}{\dfrac {1}{n_1}+\dfrac {1}{n_2}+\dfrac {1}{n_3}} = \frac {3}{\dfrac {1}{5}+\dfrac {1}{5}+\dfrac {1}{5}} = 5\]](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-e03e8a48cfbef45cf0d0a55a692d72a9_l3.png "Rendered by QuickLaTeX.com")
但是,使用調和平均數取代各組樣本數的方法僅適合在樣本數差異沒有太大的情況下(Howell, 2018)。若各組的樣本數不相等且差異很大,建議改使用Tukey-Kramer方法,會是個較合適的解決方式,以下稍做介紹。
樣本數不相等或變異數異質性的處理方法
Tukey HSD、Newman-Keuls和REGWQ等使用Student化全距統計量的事後比較檢定方法原本是以各組樣本數相同的前提下發展出來,但實務上確實會發生各組樣本數不相等的情況。為了解決樣本數不相等的問題,一個合適的方式為Tukey-Kramer方法。
Tukey-Kramer方法考量了各個群組的樣本數,若 、
、 為成對比較的兩個群組各自的樣本數,用下面的公式取代上面公式(2)的分母
為成對比較的兩個群組各自的樣本數,用下面的公式取代上面公式(2)的分母 :
:
(3) 
把公式(2)的分母換成上面的公式(3),並計算出各個成對比較的統計量後,其餘的分析過程皆相同於各群組的樣本數相等的時候。這個方法不只適用在Tukey HSD檢定上,也適用在其他使用Student化全距統計量的事後比較檢定上,同時也是SPSS預設的解決方法。
SPSS裡並沒有Turkey-Kramer的選項,根據SPSS官網,只要執行單因數變異數分析,且在事後多重比較的選項裡勾選Tukey,當各個群組的樣本數不相等時,即會自動採用Tukey-Kramer方法進行運算,並將結果輸出至「多重比較」表格裡。
如果不只樣本數不相等,連樣本變異也不相等(指變異數異質性)的情況下,可改使用Games和Howell(1976)提出的修正方法。他們以Tukey-Kramer方法為基礎,進一步允許兩個群組可以有不同的變異。若 、
、 代表成對比較的兩群組各自的變異數,他們提出公式(3)可調整為:
代表成對比較的兩群組各自的變異數,他們提出公式(3)可調整為:
(4) 
把公式(2)的分母換成公式(4),計算出各個成對比較的統計量後,查詢Student化全距分配臨界值表時,Games和Howell(1976)指出與誤差項相關的組內自由度也須跟著做調整。讓 代表調整後的組內自由度,其公式如下:
代表調整後的組內自由度,其公式如下:
(5) 
利用公式(5)計算出各個成對比較的調整自由度之後,才有辦法決定各個成對比較的臨界值。從公式(4)和公式(5)可發現,當樣本數不相等且樣本變異也不相等時,事後比較檢定的計算過程變得很複雜。若您有SPSS或SAS等統計分析軟體,此時使用軟體進行分析將能節省許多時間。
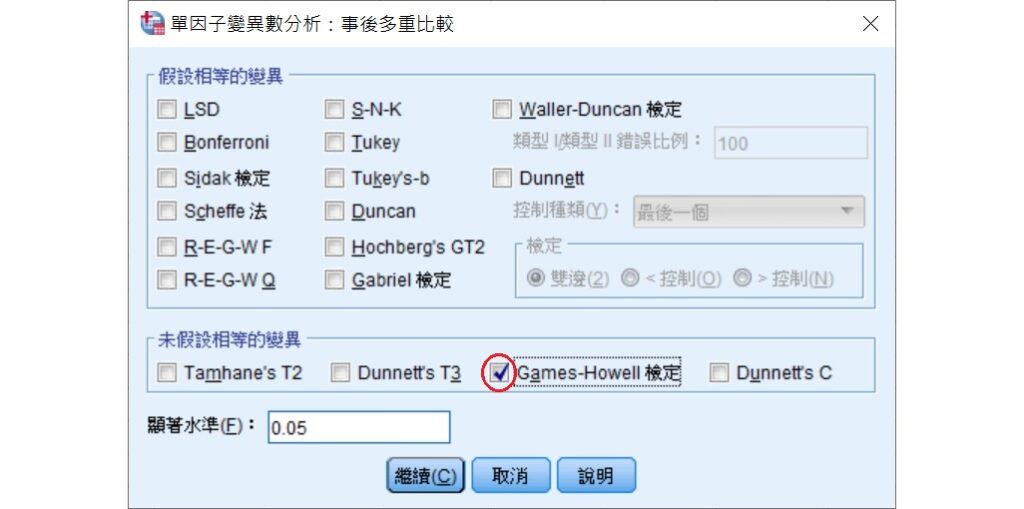
SPSS的單因數變異數分析的事後多重比較視窗裡,在未假設相等的變異的選項裡即有Games-Howell檢定。Games-Howell檢定是一個很強力的事後比較檢定,雖然樣本較小時可能變得較寬鬆,也就是容易拒絕虛無假設(Sauder & DeMars, 2019),但在各個群組的樣本數不相等且變異也不相等時,會是一個不錯的事後比較檢定方法。
以上為本篇文章對單因子變異數分析的事後比較的介紹,希望透過本篇文章,您瞭解了Student化全距統計量以及運用該統計量的Tukey HSD、Newman-Keuls和REGWQ這3種事後比較檢定的使用,也學會了利用SPSS執行事後比較檢定的操作方法。
若您喜歡本篇文章,請將本網站加入書籤,作為您的學習資源,並持續回訪本網站喔!另外,您也可以在Facebook和Twitter上找到我們喲!
參考資料
Games, P. A., & Howell, J. F. (1976). Pairwise multiple comparison procedures with unequal N´s and/or variances: A Monte Carlo study. Journal of Educational and Statistics, 1(2), 113-125. https://doi.org/10.2307/1164979
Howell, D. C. (2018, February 27). Multiple comparisons with unequal sample sizes. https://www.uvm.edu/~statdhtx/StatPages/MultipleComparisons/unequal_ns_and_mult_comp.html
Sauder, D. C., & DeMars, C. E. (2019). An updated recommendation for multiple comparisons. Advances in Methods and Practices in Psychological Science, 2(1), 26-44. https://doi.org/10.1177/2515245918808784
Welsch, R. E. (1977). Stepwise multiple comparison procedures. Journal of the American Statistical Association, 72(359), 566-575. https://doi.org/10.2307/2286218