🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
推論統計
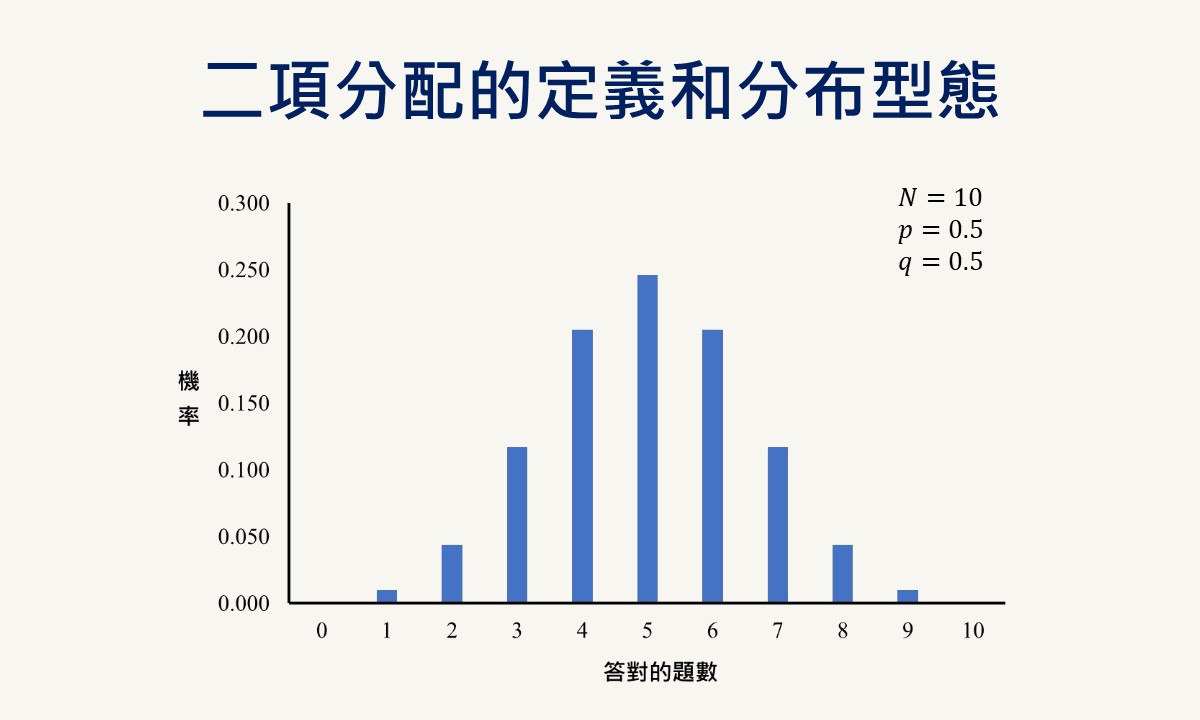
二項分配是呈現只有兩種互斥結果的一連串獨立試驗所出現的所有不同結果的機率分配,為一種間斷分配。二項分配會隨著不同的成功機率而有不同的分布型態,當成功的機率愈偏離0.5時,二項分配的偏態程度會愈高。但當試驗的次數愈多時,二項分配就會愈趨近於常態分配。
魚博士的專業漫談和課後隨筆
🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
二項分配是呈現只有兩種互斥結果的一連串獨立試驗所出現的所有不同結果的機率分配,為一種間斷分配。二項分配會隨著不同的成功機率而有不同的分布型態,當成功的機率愈偏離0.5時,二項分配的偏態程度會愈高。但當試驗的次數愈多時,二項分配就會愈趨近於常態分配。
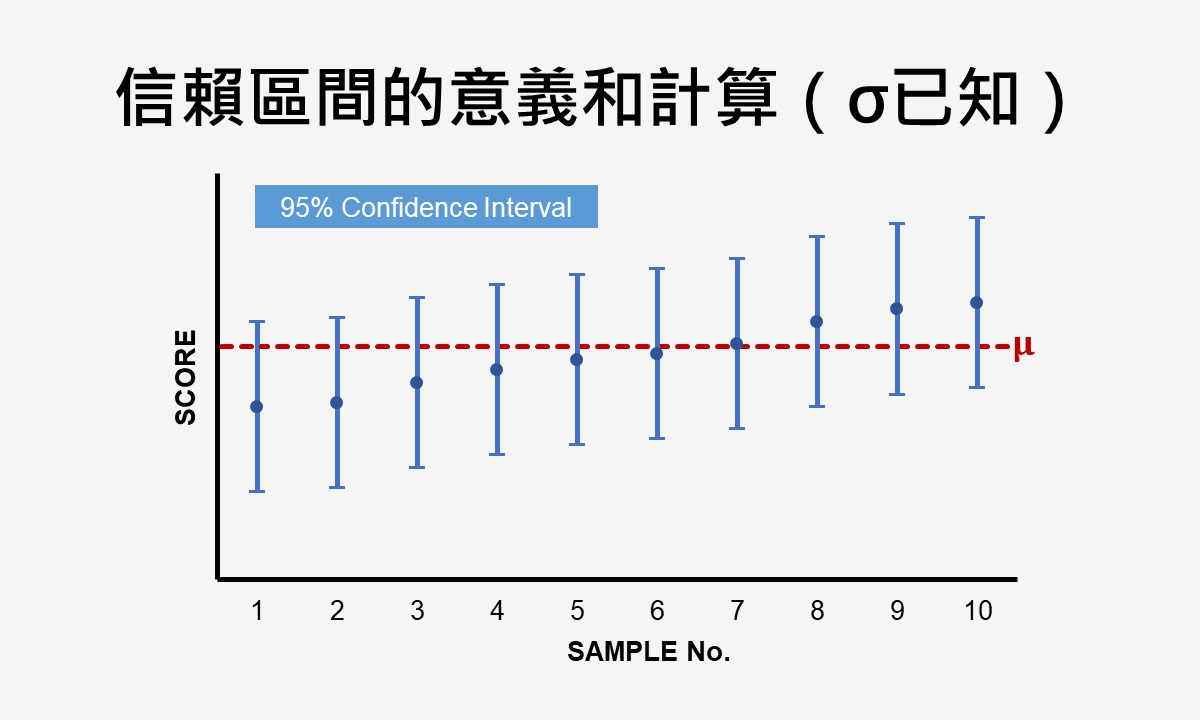
信賴區間是指可能包含母群體參數的數值範圍。以平均數為例,從同一母群體中抽取樣本數目相同的不同樣本,因為無法得知哪一個樣本的平均數為真正的母群體平均數,所以能夠透過標準誤,計算出涵蓋母群體平均數的上、下信賴限,而兩個信賴限涵蓋的範圍即為信賴區間。
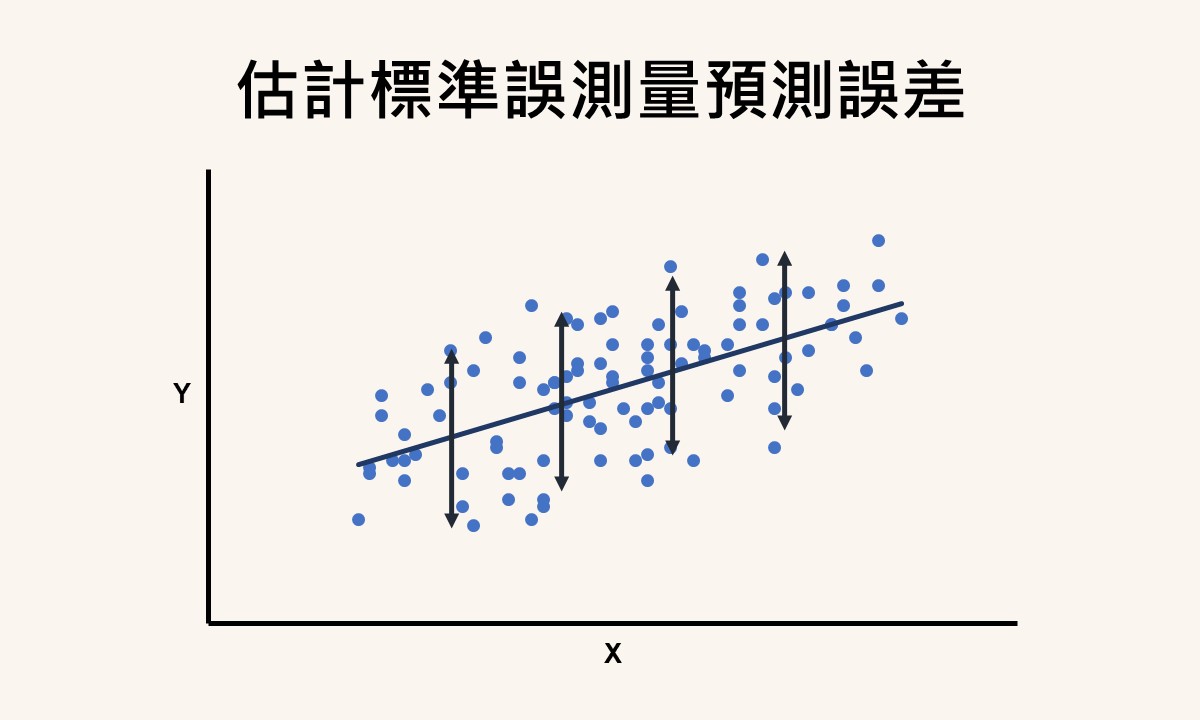
估計標準誤是在最小平方迴歸線建立之後,用來測量預測誤差的一個量化數值。若估計標準誤的數值愈大,代表預測誤差愈大,預測愈沒有信心;相反地,若數值愈小,代表預測誤差愈小,則預測的準確性愈高。為了使該數值有意義,資料必須滿足同質性或變異數同質性的假設。
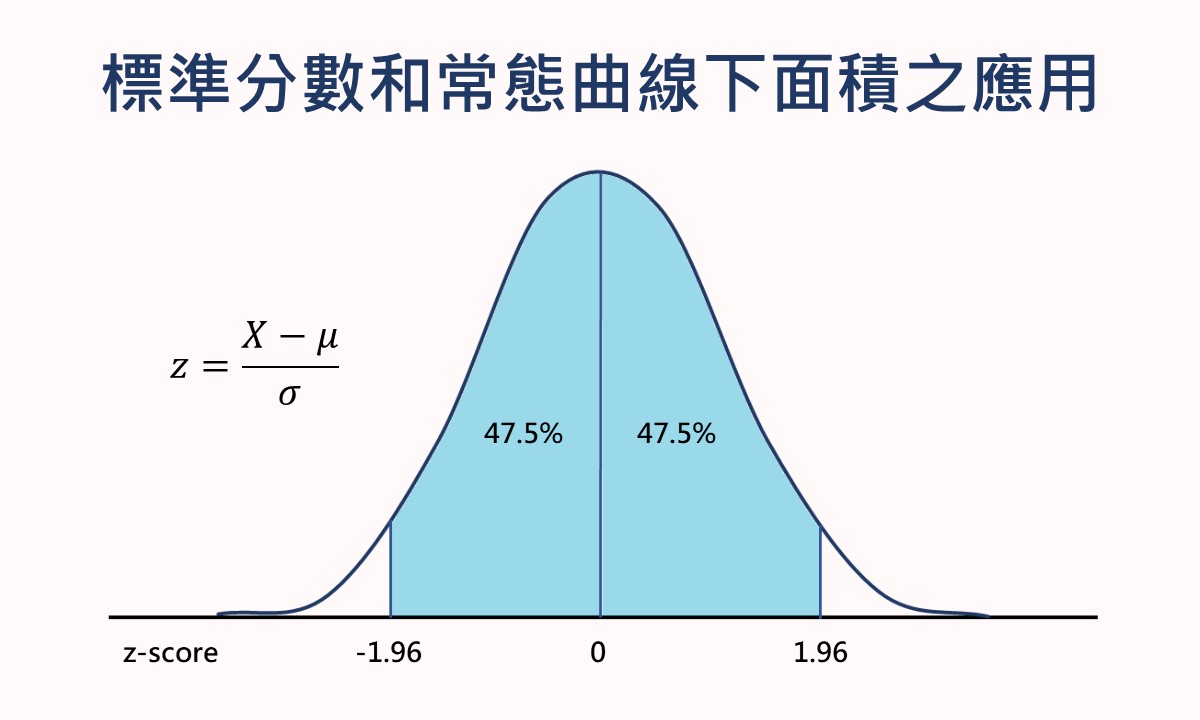
標準分數是一個轉換後的分數,將欲轉換的數值減去所有數值的平均數再除以標準差,帶有大於或小於平均數多少個標準差單位的意義。找尋大於或小於一個標準分數的常態曲線下面積,或從面積來找標準分數,皆可透過標準常態分配表或SPSS的累積分配函數或逆分配函數來達成。
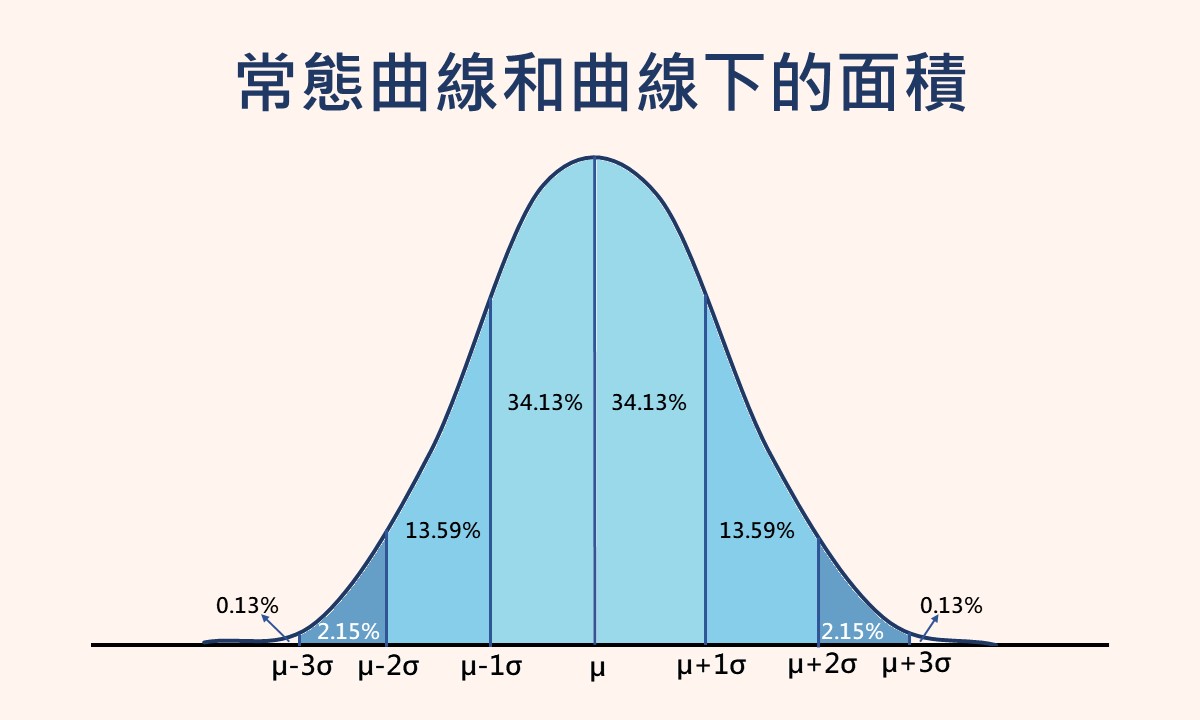
在社會和行為科學領域,最常見也最重要的一種分配就是常態分配,而象徵該分配外形的曲線即為常態曲線,也稱為鐘形曲線。常態曲線下的面積和分配的平均數、標準差之間有層特殊的關係,也就是曲線下的面積會隨著平均數加減1個、2個和3個標準差而呈現固定的比率分配。