🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
統計檢定力的意義和影響因素
在資料分析的假設檢定過程中,研究人員通常會控制第一類型錯誤(Type Ⅰ error),即是避免去拒絕一個真實的虛無假設。但與此同時,也要注意不犯下第二類型錯誤(Type Ⅱ error),也就是保留一個錯誤的虛無假設,更簡單地說,不願忽略一個確實存在的事實、關係或效果。
若一個研究無法偵測到確實存在的事實、關係或效果,該研究會失去發現真實的目的,也浪費了時間和精力,所以研究人員通常會努力去提高研究的統計檢定力(statistical power),以免錯失真實的發現。因此,統計檢定力是指在虛無假設確實是錯誤的情況下,一種統計檢定方法能夠拒絕該錯誤虛無假設的機率。
透過上述的定義,可以發現統計檢定力(以下簡稱「檢定力」)和第二類型錯誤息息相關。本篇文章將以檢定力為主軸,說明檢定力和第二類型錯誤之間的關係、檢定力的影響因素、用途和計算方式。
檢定力和第二類型錯誤之間的關係
一個統計檢定方式的檢定力是指在虛無假設為錯誤的情況下,研究人員能夠正確地拒絕該虛無假設的機率。反過來看,若在虛無假設為錯誤的情況下,研究人員無法拒絕該虛無假設,也就是保留了一個錯誤的虛無假設,此時研究人員犯下了第二類型錯誤,而該錯誤通常用符號 (beta)來表示。既然檢定力為第二類型錯誤的相反概念,所以可用
(beta)來表示。既然檢定力為第二類型錯誤的相反概念,所以可用 來呈現。
來呈現。
心理學家兼統計學家Cohen(1992)曾建議可被接受的最大第二類型錯誤機率為0.2,這代表著相對應的檢定力為 ,這也是為什麼很多研究將檢定力設定為0.8,這數值表示在虛無假設為錯誤的前提下,研究人員有80%正確地拒絕虛無假設的機會。因此,檢定力愈高代表一個研究能夠拒絕錯誤的虛無假設的機率也愈高。
,這也是為什麼很多研究將檢定力設定為0.8,這數值表示在虛無假設為錯誤的前提下,研究人員有80%正確地拒絕虛無假設的機會。因此,檢定力愈高代表一個研究能夠拒絕錯誤的虛無假設的機率也愈高。
為了說明上的方便,下面將以單一樣本t檢定為例,探討檢定力大小的影響因素。雖然說明是以單一樣本t檢定為主,但這些概念皆可適用到不同的統計檢定方法上。
檢定力的影響因素
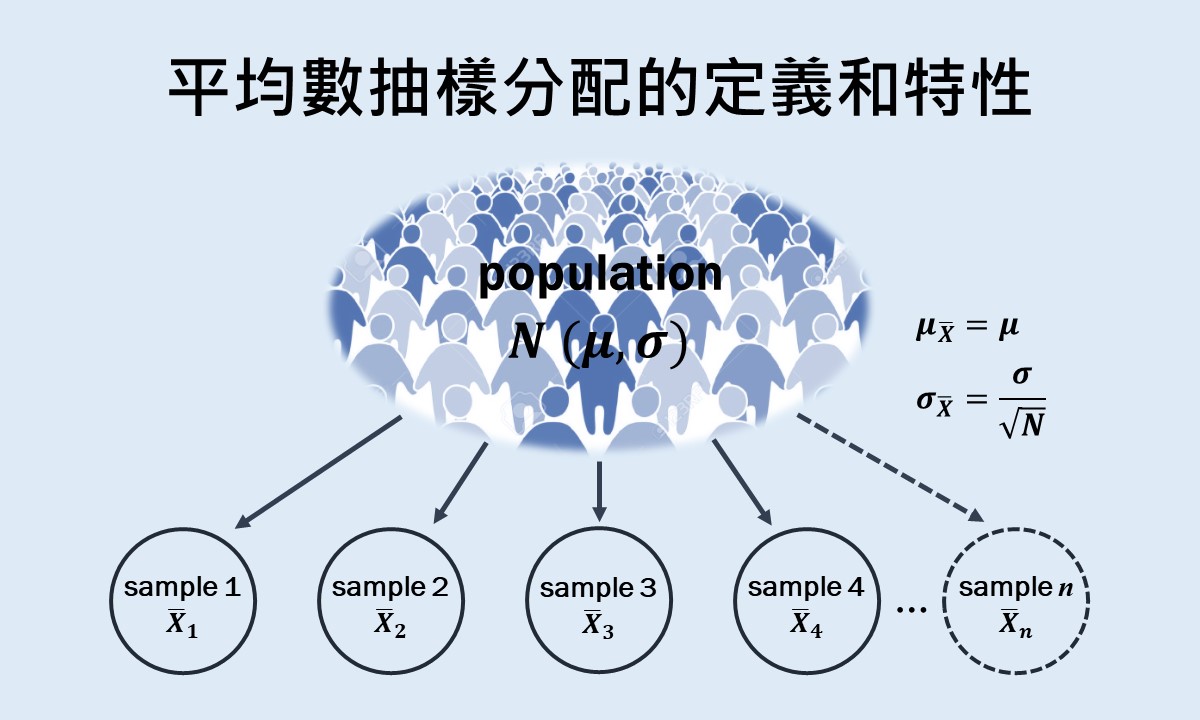
假設有兩個分配,左邊為虛無假設為真的平均數抽樣分配 ,右邊為虛無假設為誤且真實的母群體平均數為
,右邊為虛無假設為誤且真實的母群體平均數為 的平均數抽樣分配,請參考下圖1。
的平均數抽樣分配,請參考下圖1。
若此處使用單尾檢定(one-tailed test),圖中分配裡的深藍色尾端為 ,代表第一類型錯誤的機率,也稱為臨界區域。落在臨界區域邊界的數值稱為臨界值,只要計算後的檢定統計量等於或大於臨界值即可拒絕虛無假設。
,代表第一類型錯誤的機率,也稱為臨界區域。落在臨界區域邊界的數值稱為臨界值,只要計算後的檢定統計量等於或大於臨界值即可拒絕虛無假設。
從真實的母群體平均數所在的右邊分配可看出,即使虛無假設為錯誤,大多數計算後的檢定統計量仍會落在臨界值的左側,使得研究人員無法拒絕錯誤的虛無假設,因此犯下第二類型錯誤,也就是下圖1淺藍色的區域()。
只有當虛無假設為錯誤且檢定統計量落在臨界值右側的時候,才能夠正確地拒絕虛無假設,這就是所謂的檢定力,為下圖1裡分配的白色區域()。
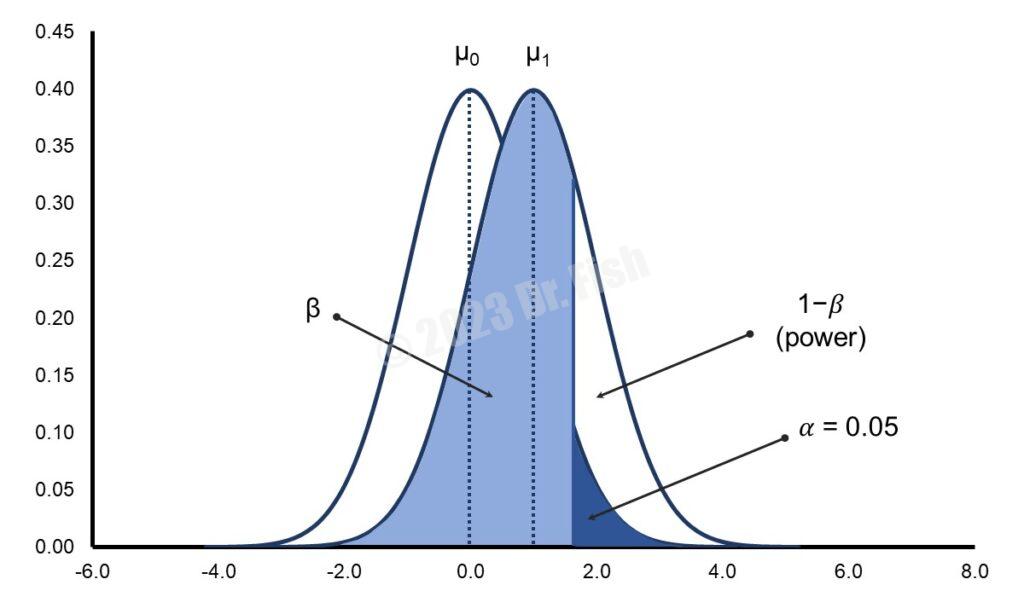
若以單一樣本t檢定的檢定統計量來看,影響檢定力的因素包含真實的對立假設、顯著水準(α水準)和檢定的方向性、樣本大小和變異性等4個因素,以下將分別說明。
真實的對立假設
檢定力會受到真實的對立假設之影響,更正確地說,會受到上圖1裡和之間距離的影響。當和之間的距離愈大時,檢定力也會愈高。
比較上圖1和下圖2,圖2裡和間的距離大於圖1裡兩者間的距離,雖然圖2裡第二類型錯誤的機率()仍舊不小,但是相較於圖1而言,檢定力()明顯地提高。
以單一樣本t檢定而言,和之間的距離是指樣本平均數 和一個已知的母群體平均數
和一個已知的母群體平均數 之間的差值。在其他條件維持不變的情況下,當樣本平均數和已知的母群體平均數之間的差值愈大,t檢定統計量的值也會愈大,使得檢定力也愈高。
之間的差值。在其他條件維持不變的情況下,當樣本平均數和已知的母群體平均數之間的差值愈大,t檢定統計量的值也會愈大,使得檢定力也愈高。
舉個簡單的例子來看,若已知的母群體平均數為100、樣本標準差 為15、樣本數
為15、樣本數 為36。假設有兩個樣本平均數,第一個平均數
為36。假設有兩個樣本平均數,第一個平均數 為102、第二個平均數
為102、第二個平均數 為106,則兩個單一樣本t檢定的檢定統計量分別為:
為106,則兩個單一樣本t檢定的檢定統計量分別為:
![\begin{align*}t &= \frac {\overline X_1-\mu}{\dfrac {s}{\sqrt N}}=\frac {102-100}{\dfrac {15}{\sqrt {36}}}=\frac {2}{2.5}=0.8 \\[10pt]t &= \frac {\overline X_2-\mu}{\dfrac {s}{\sqrt N}}=\frac {106-100}{\dfrac {15}{\sqrt {36}}}=\frac {6}{2.5}=2.4\end{align*}](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-9af476511d9b196e2b3efa5e7662c963_l3.png "Rendered by QuickLaTeX.com")
查詢t分配表,當 、
、 、單尾檢定時,t分配右側的臨界值為1.690。運用決策規則,比較上面兩個t檢定統計量和t臨界值,因為
、單尾檢定時,t分配右側的臨界值為1.690。運用決策規則,比較上面兩個t檢定統計量和t臨界值,因為 ,所以保留虛無假設;但
,所以保留虛無假設;但 ,所以拒絕虛無假設。若您不清楚或不熟悉假設檢定的過程,請參考假設檢定的步驟和範例。
,所以拒絕虛無假設。若您不清楚或不熟悉假設檢定的過程,請參考假設檢定的步驟和範例。
從上面的計算結果可發現,當樣本平均數和母群體平均數的差值增加的時候(也就是圖中和間的距離),t檢定統計量的值也會變大。由於檢定力提高,所以更有可能拒絕虛無假設。
α水準和檢定的方向性
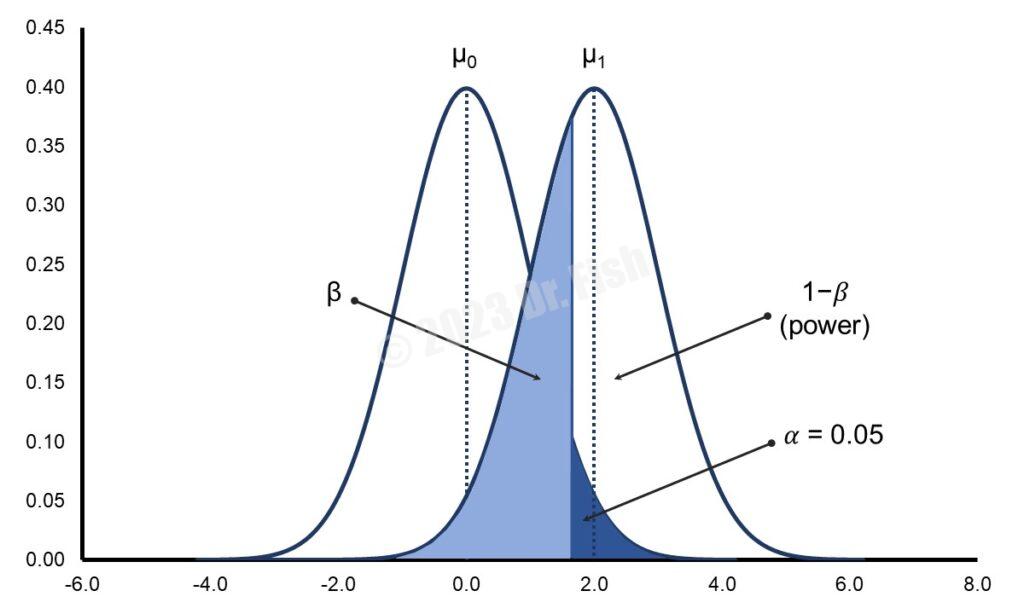
第2個影響檢定力的因素為顯著水準,也稱為α水準。顯著水準和第一類型錯誤息息相關,較嚴苛的α水準能夠降低第一類型錯誤,也就是避免去拒絕一個真實的虛無假設。但是降低第一類型錯誤的機率會提高第二類型錯誤的機率,而當第二類型錯誤的機率提高時,檢定力則會下降。
比較上圖1和下圖3,圖1裡分配的α水準為0.05,圖3裡分配的α水準則為0.01。從兩張圖可以看出,當α水準為0.01的時候,分配裡的白色區域明顯地變小,代表檢定力()降低。換句話說,若α水準的設定比較寬鬆,檢定力則會提升。
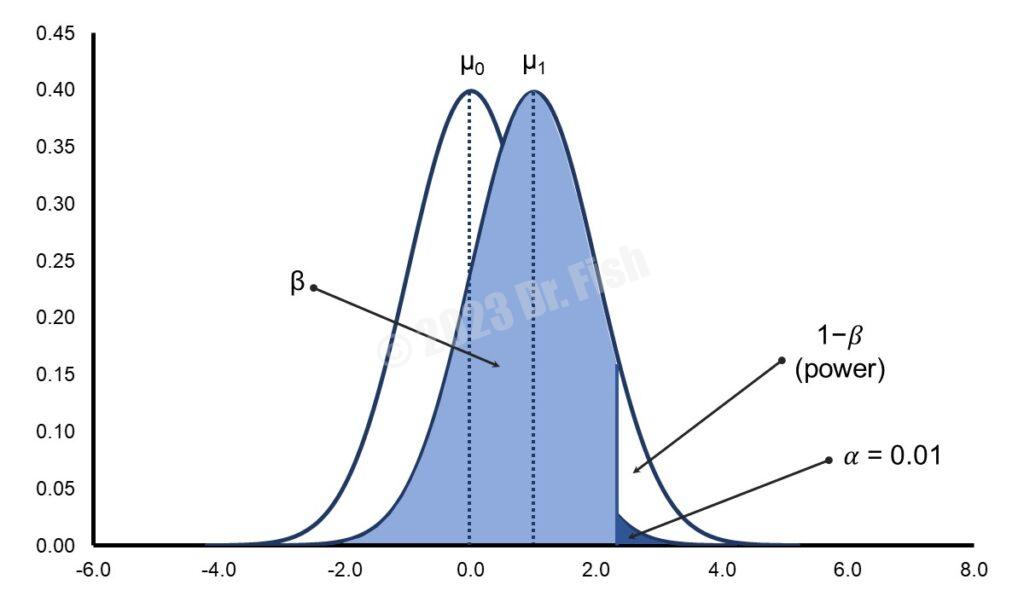
此外,檢定的方向性也會影響檢定力。圖1至圖3皆為單尾檢定,若是雙尾檢定,分配尾端的藍色區域會減半( ),並平均分配在分配的兩側尾端,可想而知,一側的藍色區域會更小。此種情況即類似於上面提到的α水準的改變,當圖中的藍色區域變得愈小時,檢定力會愈低。
),並平均分配在分配的兩側尾端,可想而知,一側的藍色區域會更小。此種情況即類似於上面提到的α水準的改變,當圖中的藍色區域變得愈小時,檢定力會愈低。
舉個例子來說,當、 、單尾檢定時,t分配右側的臨界值為1.690。然而,當、、雙尾檢定時,t分配右側的臨界值則為2.030。由於單尾檢定的t臨界值比較小,計算後的t檢定統計量比較容易大於該臨界值,所以也比較容易拒絕虛無假設。
、單尾檢定時,t分配右側的臨界值為1.690。然而,當、、雙尾檢定時,t分配右側的臨界值則為2.030。由於單尾檢定的t臨界值比較小,計算後的t檢定統計量比較容易大於該臨界值,所以也比較容易拒絕虛無假設。
因此,從上面的說明可知道,選擇較寬鬆的α水準或使用單尾檢定,都可以提高一種統計檢定方法的檢定力。
樣本大小
第3個影響檢定力的因素為樣本大小,通常用符號來表示。樣本大小是推估母體參數的一個重要因素,因為當樣本數愈大的時候,母體參數的估計值愈正確。此外,當樣本數愈大的時候,抽樣分配的分布範圍會變得比較窄。
回顧平均數抽樣分配的其中一個特性,平均數抽樣分配的標準差(也稱為標準誤)等於母群體的標準差 除以
除以 ,由此可知,當樣本數增加的時候,平均數抽樣分配的標準差會變小。而當標準差變小的時候,計算出來的檢定統計量會變大,所以更有可能拒絕虛無假設。
,由此可知,當樣本數增加的時候,平均數抽樣分配的標準差會變小。而當標準差變小的時候,計算出來的檢定統計量會變大,所以更有可能拒絕虛無假設。
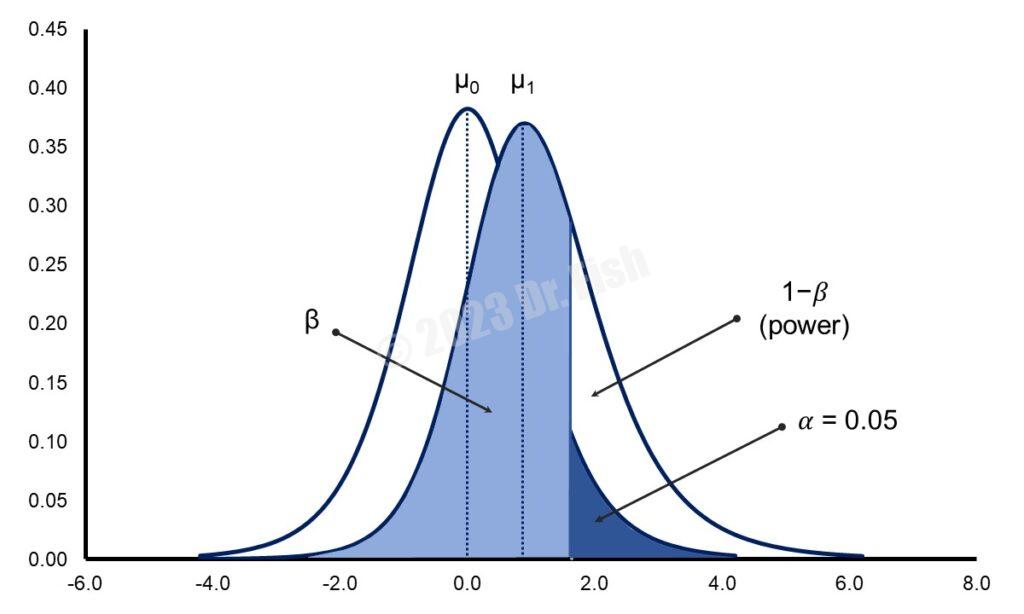
比較下面的圖1和圖4,圖4是樣本數較少的和分配。乍看之下,會覺得兩張圖很像,但仔細看可發現圖1的淺藍色區域()較圖4少一點,相對地讓代表檢定力()的白色區域比圖4多一點。換句話說,在其他條件維持不變的情況下,當樣本數愈大時,檢定力會愈高。
舉個簡單的例子來看,若已知的母群體平均數為100、樣本平均數為103、樣本標準差為15。假設有兩個樣本,第1個樣本的樣本數為36,第2個樣本的樣本數為81,則兩個單一樣本t檢定的檢定統計量分別為:
![\begin{align*}t &= \frac {\overline X-\mu}{\dfrac {s}{\sqrt N}}=\frac {103-100}{\dfrac {15}{\sqrt {36}}}=\frac {3}{2.5}=1.2 \\[10pt]t &= \frac {\overline X-\mu}{\dfrac {s}{\sqrt N}}=\frac {103-100}{\dfrac {15}{\sqrt {81}}}=\frac {3}{1.667} \approx 1.8\end{align*}](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-9b22d58937b103728ecb583416a67e07_l3.png "Rendered by QuickLaTeX.com")
當、、單尾檢定時,t分配右側的臨界值為1.690。運用決策規則,比較t檢定統計量和t臨界值,因為 ,所以保留虛無假設。另一方面,當、
,所以保留虛無假設。另一方面,當、 、單尾檢定時,t分配右側的臨界值為1.664,因為
、單尾檢定時,t分配右側的臨界值為1.664,因為 ,所以拒絕虛無假設。
,所以拒絕虛無假設。
從這個例子可清楚地看出,當樣本數較大的時候,會讓t檢定統計量的數值變得比較大,進而提高檢定力,因此更有可能拒絕虛無假設。
變異性
最後一個影響檢定力的因素為變異性(variability)。當樣本來自的母群體變異較大的時候,抽樣分配也會呈現出較大的變異,也就是分布的範圍會比較廣。
由於標準差為測量變異的一個數值,運用上面樣本大小因素裡提到的「平均數抽樣分配的標準差等於母群體的標準差除以」的概念,當母群體的標準差變大的時候,平均數抽樣分配的標準差也會變大。而當標準差變大的時候,計算出來的檢定統計量則會變小,因此較不容易拒絕虛無假設。
同樣舉個簡單的例子來看,若已知的母群體平均數為100、樣本平均數為105、樣本大小為36。假設有兩個樣本標準差,第1個樣本標準差 為15,第2個樣本標準差
為15,第2個樣本標準差 為24,則兩個單一樣本t檢定統計量分別為:
為24,則兩個單一樣本t檢定統計量分別為:
![\begin{align*}t &= \frac {\overline X-\mu}{\dfrac {s_1}{\sqrt N}}=\frac {105-100}{\dfrac {15}{\sqrt {36}}}=\frac {5}{2.5}=2 \\[10pt]t &= \frac {\overline X-\mu}{\dfrac {s_2}{\sqrt N}}=\frac {105-100}{\dfrac {24}{\sqrt {36}}}=\frac {5}{4}=1.25\end{align*}](https://drfishstats.com/wp-content/ql-cache/quicklatex.com-38b95039be58b8bfa9556ad09ed8206f_l3.png "Rendered by QuickLaTeX.com")
當、、單尾檢定時,t分配右側的臨界值為1.690。運用決策規則,比較t檢定統計量和t臨界值,因為 ,所以拒絕虛無假設;但因為
,所以拒絕虛無假設;但因為 ,所以保留虛無假設。
,所以保留虛無假設。
從這個例子可以看出,當樣本來自的母群體變異較大時,會使得t檢定統計量的數值變小,造成檢定力降低,因此不容易拒絕虛無假設。換句話說,降低母群體的變異將有助於檢定力的提升。
總結來說,檢定力的大小受到真實的對立假設、
檢定力的用途
檢定力和α水準、檢定的方向性、樣本大小和自變項效果的大小(或稱為效果量,和上面提到的「真實的對立假設」有關)相互連結,若知道其中的4個資訊,便能夠得到剩下的那一個資訊。一般而言,檢定力會用在下列的兩個方面:
- 計算一種統計檢定方法的檢定力:屬於事後分析(post-hoc analysis),通常是在研究已經執行完畢後,用來討論所使用的統計檢定方法的檢定力。由於研究已經完成,所以會有α水準、樣本大小與效果量等資訊,研究人員可利用這些資訊來計算出檢定力。若檢定力很高,例如0.8或更高的數值,研究人員可以有信心地主張研究能夠偵測出任何可能存在的效果;但若檢定力很低,研究人員則可指出研究沒有偵測到效果的可能原因之一為檢定力不足,之後可複製該研究,並增加樣本數來提高檢定力。
- 計算用來達到某特定檢定力所需的樣本數:屬於事前分析(priori analysis),在研究開始之前,計算出達到某一檢定力所需要的樣本數。研究開始前,先設定好α水準和預期達到的檢定力,並藉由過往的研究或類似的研究來預測效果量。當α水準、檢定力和效果量的資訊俱備時,即可計算出樣本大小。
上面兩個檢定力的使用時間點,一個是研究已經完成,另一個則是在研究開始前,雖然沒有哪一種用途較佳之說,但與其事後檢討不如事前計算好達到預期檢定力所需的樣本數,避免錯失發現真實的機會。
檢定力的計算並不簡單,但可利用專門軟體來協助計算。免費軟體如G*Power、R的pwr套件,付費軟體如nQuery、PASS(Power Analysis & Sample Size)皆可用來計算檢定力和樣本數。以下利用免費軟體G*Power來示範求得檢定力和樣本數的操作方法。
運用G*Power計算檢定力或樣本數
G*Power可用來計算多種統計檢定方法的檢定力或研究所需的樣本數,雖然是免費的軟體,但功能相當強大。目前只有英文版本,沒有其他語言的介面。一開始可能會覺得難以操作,但若瞭解了上面說明的檢定力概念後,便可慢慢上手。
這裡使用3.1.9.7的版本,並以單一樣本t檢定為例。假設研究的母群體平均數為100、樣本平均數為105、樣本標準差為14、樣本數為36,並使用0.05的α水準和雙尾檢定。下面先示範事後分析的檢定力計算,再示範事前分析的樣本數計算之操作過程。
檢定力的計算
開啟G*Power後,會出現如下圖的視窗,可能會因為版本的不同而有些微的差異,但不會影響接下來的操作。視窗的上半部為圖形顯示的區域,先暫且忽略該部分,直接看下半部。
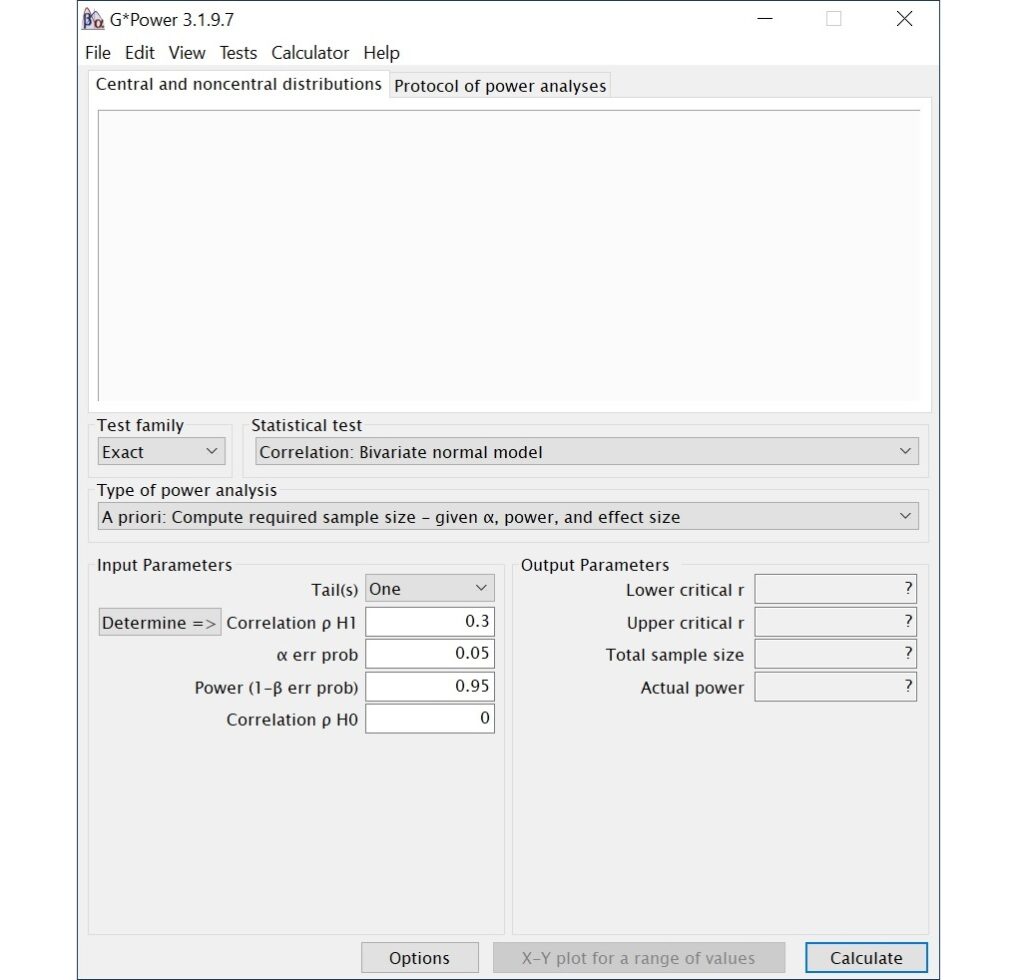
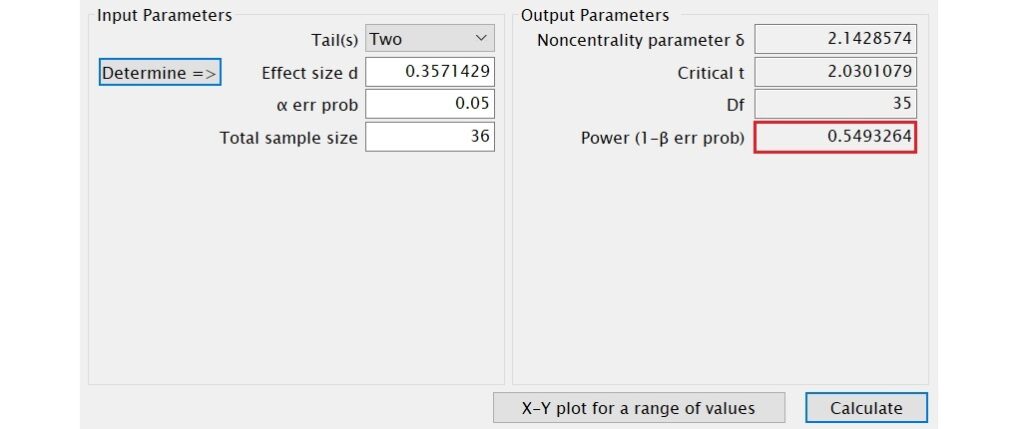
從Test family的下拉選單中選擇t test,再從Statistical test的下拉選單中點選Means: Difference from constant (one sample case),最後從Type of power analysis的下拉選單中選擇Post hoc: Compute achieved power – given α, sample size, and effect size。

在Input Parameters方框裡,從Tail(s)的下拉選單中選擇Two(指雙尾檢定),在α err prob的欄位裡輸入0.05(指α水準),在Total sample size的欄位裡輸入36。
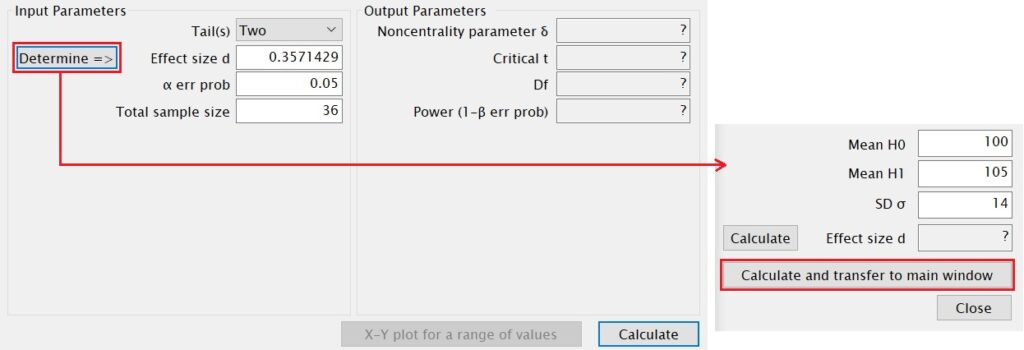
您可自行計算效果量或點選Determine,會出現一個小視窗,在這裡可以輸入兩個平均數和標準差的數值,再按下Calculate and transfer to main window,G*Power即會將計算出來的效果量帶入主視窗的Effect size d欄位裡。當數值皆輸入至Input Parameters方框裡的所有欄位後,按下視窗右下方的Calculate。
計算結果會出現在Output Parameters方框裡,Power (1-β err prob)即為檢定力,結果顯示檢定力約為0.55。這裡也會顯示t臨界值(Critical t)約為2.030、自由度(Df)為35。
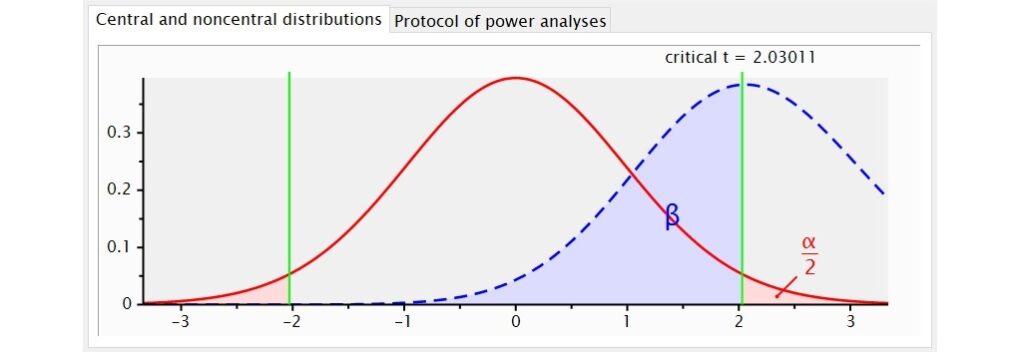
視窗的上半部會顯示虛無假設 和對立假設
和對立假設 兩個分配的圖形,樣本平均數和母群體平均數之間的距離、α水準的區域(臨界區域)、臨界值的位置和檢定力的大小皆一目了然。
兩個分配的圖形,樣本平均數和母群體平均數之間的距離、α水準的區域(臨界區域)、臨界值的位置和檢定力的大小皆一目了然。
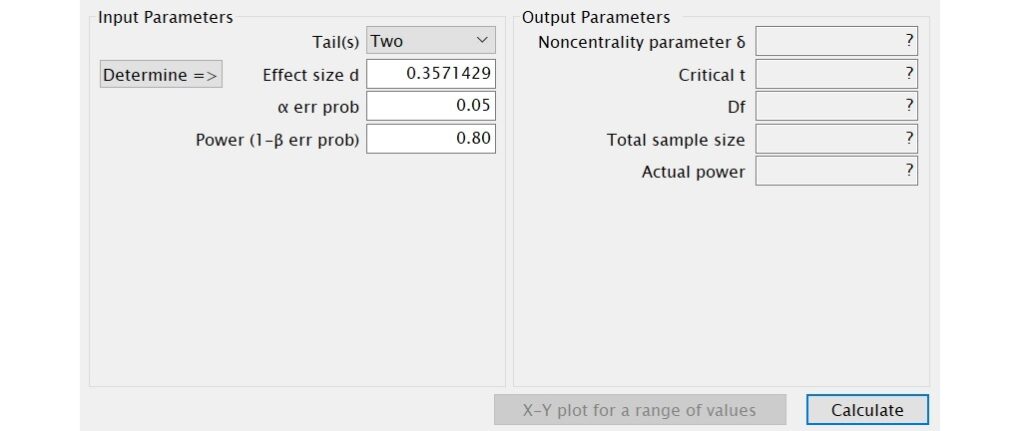
除了檢定力的計算外,也可使用G*Power來計算達到預期的檢定力所需要的樣本數,以下示範操作過程。
樣本數的計算
上面檢定力分析的結果顯示該研究的檢定力為0.55,若想在所有條件皆維持不變的情況下達到0.80的檢定力,可透過下面的步驟來求得研究所需的樣本數。
因為同樣是單一樣本t檢定,所以Test family和Statistical test的選擇和上面檢定力的計算是一樣的。但在Type of power analysis的下拉選單中改選擇A priori: Compute required sample size – given α, power, and effect size。

在Input Parameters方框裡,Tail(s)、Effect size d、α err prob欄位的數值和上面檢定力計算的數值相同,在Power (1-β err prob)的欄位裡輸入欲達到的檢定力,這裡為0.80。輸入完成後,按下右下方的Calculate。
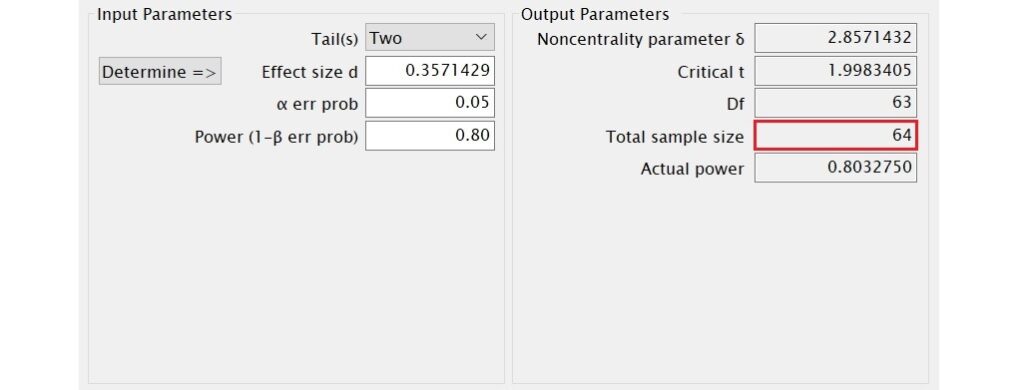
計算結果會顯示在Output Parameters方框裡的Total sample size欄位,從下圖可看出,在效果量為0.36、α水準為0.05、雙尾檢定的情況下,達到0.80檢定力所需的樣本數為64。
以上僅為單一樣本t檢定的例子,G*Power還有許多不同統計檢定方法的檢定力和樣本數計算的選擇,您可視自己的需求來進行相關的操作。
以上為本篇文章對統計檢定力的意義和影響因素的介紹,希望透過本篇文章,您瞭解了統計檢定力的意義、影響因素和用途,也學會了利用G*Power來計算檢定力和樣本數的操作方法。
若您喜歡本篇文章,請將本網站加入書籤,作為您的學習資源,並持續回訪本網站喔!另外,您也可以在Facebook和Twitter上找到我們喲!
參考資料
Cohen, J. (1992). A power primer. Psychological Bulletin, 112(1), 155-159. https://doi.org/10.1037/0033-2909.112.1.155