🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
如何使用 Excel 排序和篩選資料
微軟的 Excel 是一功能強大的軟體,各種專業領域的使用者都很常利用它來進行資料整理。此外,相較於不容易取得和價格昂貴的專門統計軟體如 SPSS、SAS,相對普及的 Excel 也很常作為資料分析的工具。不論是資料整理或資料分析的過程,都很常遇到資料需要排序或篩選的情況,而這2種操作都可在 Excel 裡簡單地達成。
資料排序和篩選向來可以透過 Excel 圖形化的功能表來進行,但是 Microsoft 365、Excel 2021 和之後的版本建立了排序和篩選的函數,讓使用者能夠選擇圖形化的介面或函數語法來執行資料排序或篩選。本篇文章將介紹這些函數的使用,除了語法的說明,也會舉例示範各個函數的操作方法與函數合併使用的情況,讓您在使用 Excel 之際具有更多的彈性。
SORT 函數
排序功能裡最基本的一個函數為 SORT 函數,可用一個標準或條件來排序一欄、一列或數欄和數列組成的資料。因為這個函數會一次傳回一組數值,也就是一個陣列(array),所以稱為動態陣列公式。這個函數的語法為:
=SORT(array, [sort_index], [sort_order], [by_col])
括號裡為語法的引數(argument),一共有4個,中括號裡的引數為非必要的引數,可選擇性地使用。這4個引數的意義分別如下:
- array:資料的範圍,可以是一欄、一列或數欄和數列組成的資料。
- sort_index:作為排序標準或條件的欄或列所在的欄數或列數,預設值為第1欄或第1列。
- sort_order:排列的順序,數值1為從小至大的排序(預設值),數值-1為從大至小的排序。
- by_col:排序的方法,邏輯值 FALSE 為按列排序(預設值),邏輯值 TRUE 為按欄排序。
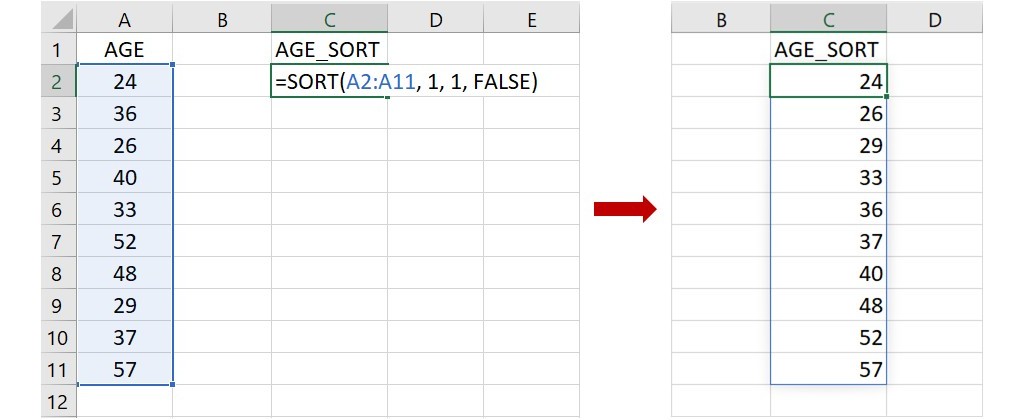
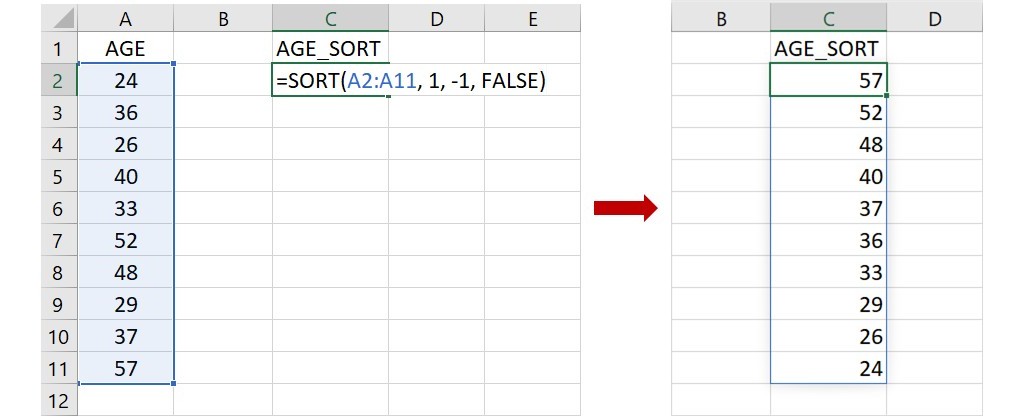
先舉個簡單的例子,假設只有一欄 AGE 的資料,我們想將年齡從小至大排序。找一空白欄,在第1列的儲存格輸入 AGE_SORT 或任何您習慣或喜歡的名稱,然後在這個名稱的下方儲存格(下圖為C2)輸入下面的任一個語法:
① =SORT(A2:A11, 1, 1, FALSE)
② =SORT(A2:A11)
這語法指出資料位在儲存格A2到A11,要求以第1欄為排序標準,把數值從小至大且按列排序。由於這裡只有一欄資料,所以只能以該欄(第1欄)作為排序標準,再加上第3和第4個引數皆為預設值,因此第1個語法可以簡化成第2個語法。不論使用哪一個語法,都可以得到相同的排序。
若想將年齡從大至小排序,而非從小至大排序,只要更改語法裡第3個引數的值至-1即可。不過此時就不能夠把語法簡化成上面的第2個語法,因為排列順序的預設值為從小至大而非從大至小,所以若要讓數值改成從大至小排序,必須在語法裡明確地指出。
在社會或行為科學的領域裡,當輸入資料至統計分析軟體或 Excel 時,通常都是一欄一個變項、一列為一位研究參與者所有變項資料的方式。不過在 Excel 裡,也容許一列一個變項的輸入方法,若想對此種輸入方法的資料進行排序,只須更改語法裡的第4個引數即可。
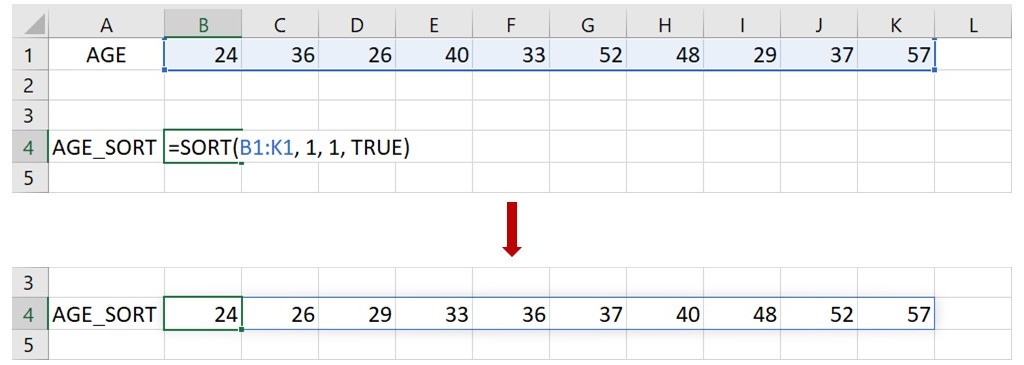
例如上面原本在第1欄的年齡資料變成在第1列,此時若想將年齡從小至大進行排序,可以在一空白的儲存格(下圖為B4)輸入下面的語法:
=SORT(B1:K1, 1, 1, TRUE)
這語法指出資料範圍位於儲存格B1到K1,要求以第1列為排序標準,將年齡從小至大且按欄進行排序。由於這裡的資料為一列,也就是一欄一個數值,而為了讓資料「按欄」排序,須將語法裡的第4個引數改成 TRUE,才可正確地排序。不過這種資料輸入的方法在社會和行為科學領域並不常見,所以這裡僅作為第4個引數使用時機的示範,下面內容將不再使用這種輸入方法。
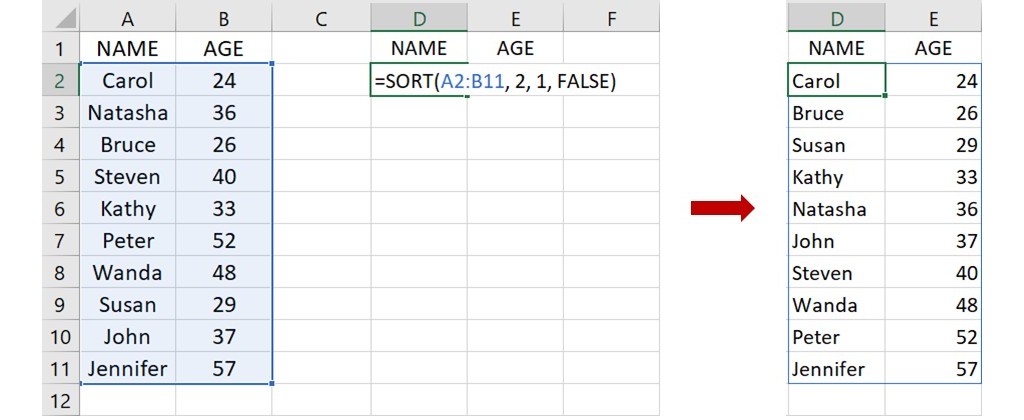
進一步來看,除了原本的年齡 AGE 之外,再增加一欄名字 NAME 的資料,讓資料變成2欄。若想讓名字依據年齡大小(從小至大)進行排序,可在下圖的儲存格D2裡輸入下面的語法:
=SORT(A2:B11, 2, 1, FALSE)
這語法指出資料範圍位於儲存格A2到B11,要求以第2欄的年齡 AGE 為排序標準,從年紀最小到最大的順序來排列名字。
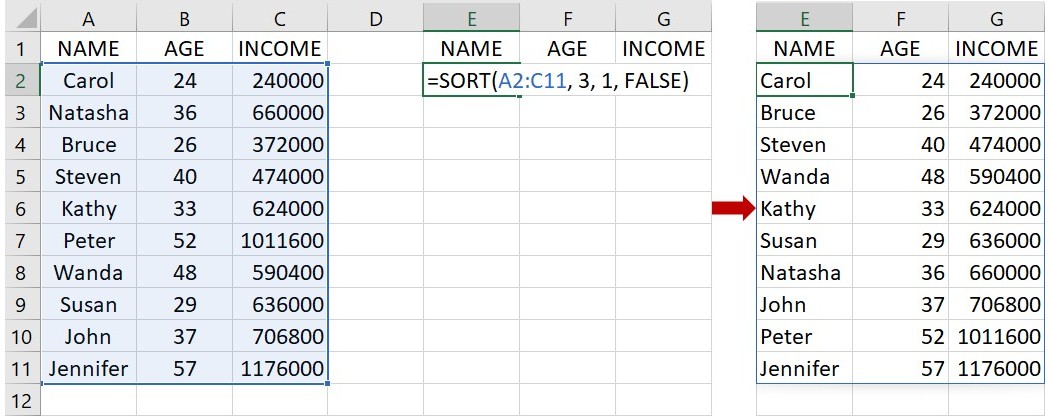
利用相同的方法,即使有更多欄的資料,都可以進行排序。例如下面的資料有3欄,也就是3個變項,若想依據年收入 INCOME 的少至多來排列其他欄的資料,可在一空白的儲存格(下圖為E2)輸入下面的語法:
=SORT(A2:C11, 3, 1, FALSE)
這語法指出資料範圍位於儲存格A2到C11,要求以年收入 INCOME 為排序標準,從年收入最少到最多的順序來排列名字和年齡。
當資料欄數較多,也就是變項較多時,要知道作為排序標準的變項所在的欄數可能變得困難,此時可用 MATCH 函數來獲得這個變項所在的位置。例如上面的例子裡,儲存格E2的語法可改成:
=SORT(A2:C11, MATCH(“INCOME”, A1:C1, 0), 1, FALSE)
這語法裡的 MATCH 函數會傳回數值3,代表作為排序標準的 INCOME 位於第3欄。利用這樣的語法不用去計算排序標準的變項所在的欄數,但須注意變項名稱必須使用雙引號且正確地寫出。關於 MATCH 函數的詳細說明,可以參考如何使用 Excel 的 INDEX 和 MATCH 函數向左尋找資料。
利用 SORT 函數對資料進行排序雖然很簡單,但只能使用1個排序標準。此外,當新增或減少一整欄的資料時,由於一開始作為排序標準的變項欄數已被變更,所以原本排序好的資料會變得無法正確顯示。例如上面3欄的資料,若刪除年齡那一整欄,原本排序好的資料會傳回 #VALUE! 的錯誤訊息且無法顯示。
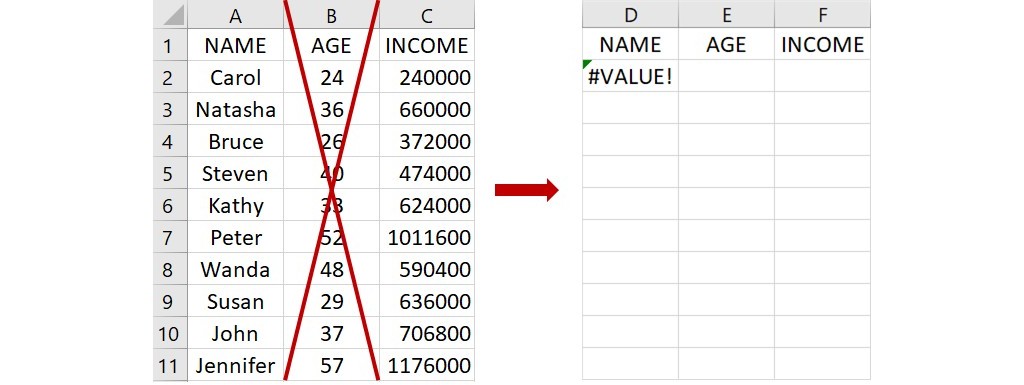
因此,若想要使用2個或2個以上的排序標準,或是想要新增或減少變項而不會影響已經排序好的資料時,可以改使用更具彈性的 SORTBY 函數,下面介紹這個函數的語法和使用方法。
SORTBY 函數
排序功能裡較進階的一個函數為 SORTBY 函數,這函數和 SORT 函數一樣可用來排序一欄、一列或數欄和數列組成的資料,且同樣會傳回一陣列的數值,也屬於動態陣列公式。不過不同於 SORT 函數,這個函數能夠一次使用2個或2個以上的排序標準,且新增或刪除一整欄的原始資料不會影響已經排序好的資料,因此較 SORT 函數更具彈性。SORTBY 函數的語法為:
=SORTBY(array, by_array1, [sort_order1], [by_array2, sort_order2],…)
語法裡中括號裡的引數並非必要,可選擇性使用。上面語法裡各個引數的意義分別如下:
- array:欲排序的資料範圍。
- by_array1:第1個排序標準所在的資料範圍。
- sort_order1:第1個排序標準的排列順序,數值1為從小至大,數值-1為從大至小。預設值為從小至大的數值1。
- by_array2:第2個排序標準所在的資料範圍。
- sort_order2:第2個排序標準的排列順序,數值1為從小至大,數值-1為從大至小。預設值為從小至大的數值1。
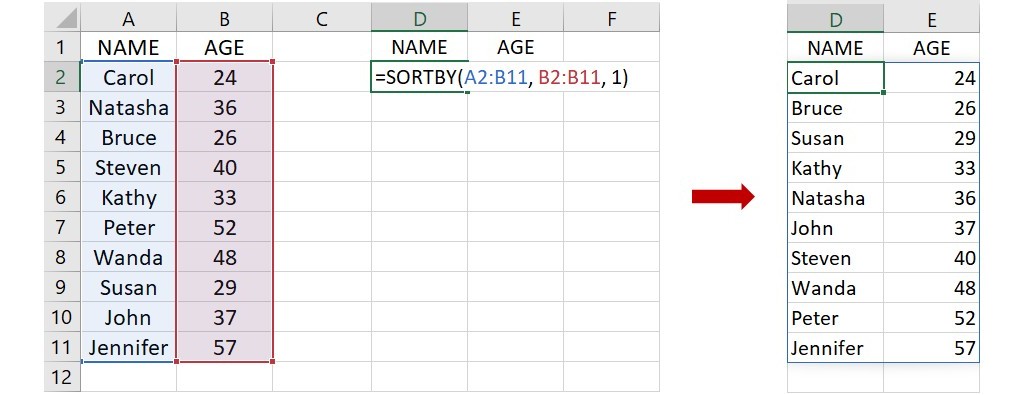
從 SORTBY 函數的語法可以發現,這函數的執行須指明至少1個排序標準。舉例來說,上面的名字 NAME 和年齡 AGE 兩欄資料,若以年齡為排序標準,從最小到最大年紀的順序來排列名字,可在下圖的儲存格D2裡輸入下面的語法:
=SORTBY(A2:B11, B2:B11, 1)
這語法指出欲排序的資料位於儲存格A2到B11,要求以位於儲存格B2到B11的年齡為排序標準,從最小到最大年齡的順序來排列名字。下圖右為 SORTBY 函數的傳回結果,和上面利用 SORT 函數所得到的結果是一樣的。
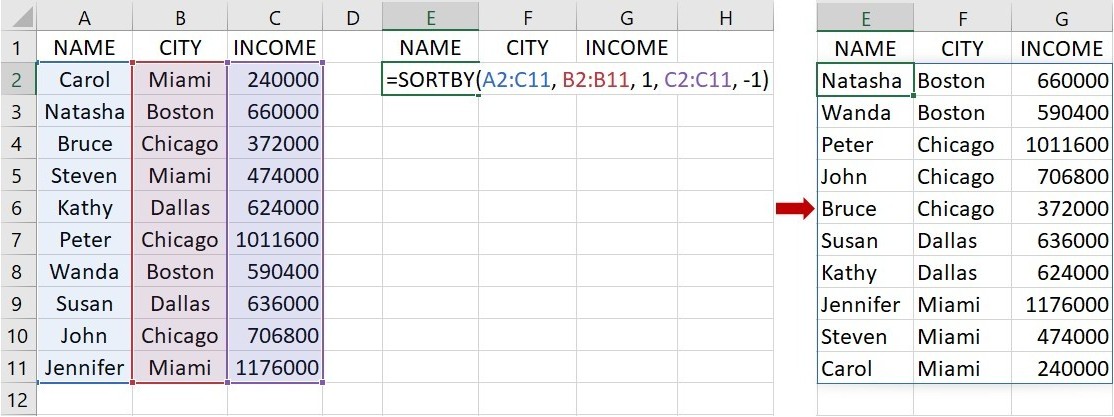
更進一步來看,若有3欄的資料(也就是3個變項),其中有2個排序標準,第1個為城市 CITY 而第2個為年收入 INCOME,想要先依據A到Z的順序排列城市再從高至低排列年收入,可在下圖的儲存格E2裡輸入下面的語法:
=SORTBY(A2:C11, B2:B11, 1, C2:C11, -1)
這語法指出欲排序的資料範圍位在儲存格A2到C11,第1個排序標準位於儲存格B2到B11,第2個排序標準位於儲存格C2到C11,要求第1個排序標準從小至大排列而第2個排序標準從大至小排列。語法輸入完成後,按下 Enter 會傳回如下圖右邊的資料。
從上面的示範過程可以看到,SORTBY 函數可以使用2個或2個以上的排序標準。此外,當新增或刪除一整欄資料的時候,原本已經排序好的資料會自動新增或刪除被更動的那欄資料,其餘資料維持不變。舉例來說,上面使用 SORT 函數來排序年收入 INCOME 的3欄資料,如果改使用 SORTBY 函數也可以得到相同的結果。
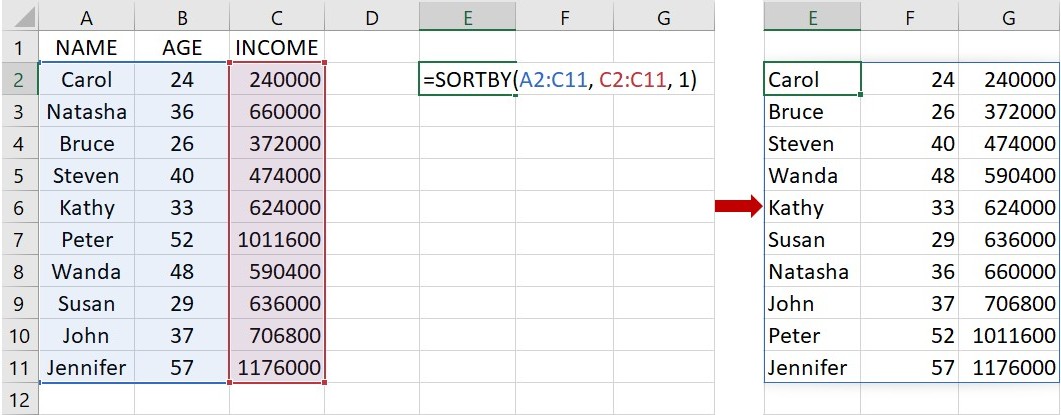
在使用 SORTBY 函數進行排序的情況下,若刪除原始資料的年齡 AGE 那一整欄,原本已經排序好的資料也會自動刪除年齡那一整欄,變成下圖右邊的樣子。這一點和 SORT 函數有很大的不同,凸顯了 SORTBY 函數的彈性較大。
雖然 SORTBY 是個很實用的函數,但使用時須注意作為排序標準的資料引數(by_array)必須是一整欄。此外,函數裡的所有引數必須是相同大小,也就是說,每一欄從上到下的儲存格數目都要相同,否則會出現 VALUE! 的錯誤訊息。
FILTER 函數
當進行資料整理的過程中,除了資料排序之外,也很常需要篩選資料,甚或篩選後再排序。若想要依據自訂的標準來執行資料篩選,可以使用 FILTER 函數。這個函數的語法如下:
=FILTER(array, include, [if_empty])
語法裡中括號裡的引數並非必要,可以選擇性地使用。語法裡各個引數的意義如下:
- array:想要篩選的資料陣列或範圍,能夠是一欄、一列或數欄和數列組成的資料。
- include:篩選的條件,須以陣列的方式呈現,且陣列的高度或寬度需和想要篩選資料的陣列相同。
- if_empty:當篩選條件陣列裡不存在篩選值時,系統傳回的訊息。
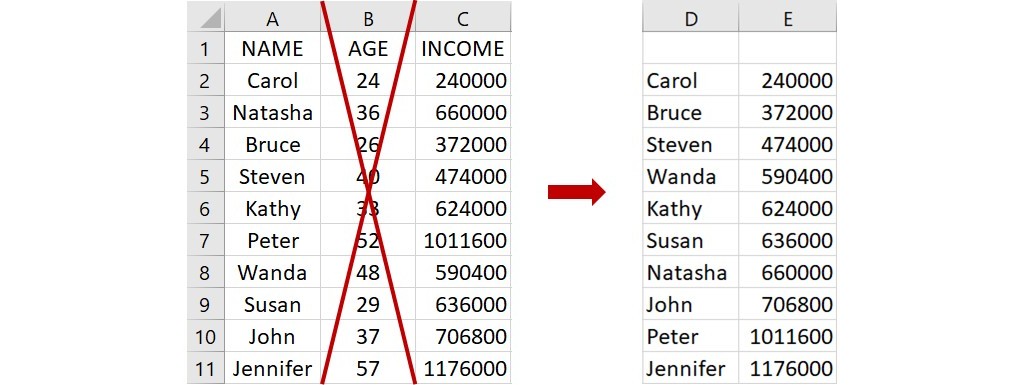
先舉個簡單的例子來說,假設有名字 NAME、城市 CITY 和年收入 INCOME 三欄的資料,要篩選城市為 Chicago 的所有資料,可在一空白儲存格(下圖為E2)輸入下面的語法:
=FILTER(A2:C11, B2:B11=“Chicago”)
這語法指出被篩選的所有資料位在儲存格A2到C11,篩選條件為儲存格B2到B11裡名稱為 Chicago 的城市,因為是字串,所以須使用雙引號。由於篩選條件的值確實存在,所以沒有使用第3個引數。語法輸入完成後,按下 Enter 會傳回城市為 Chicago 的人名和年收入資料,如下圖右。
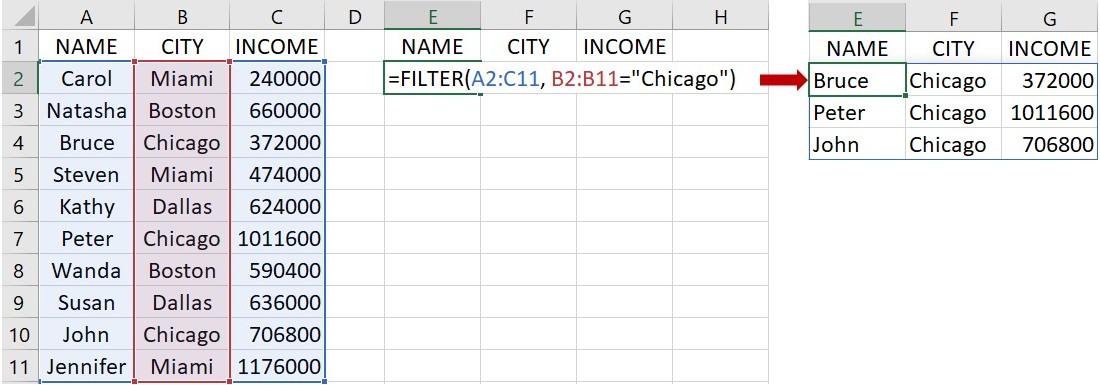
更進一步來看,若篩選條件有2個,且須同時成立,此時可使用乘法運算符號(*)來連結2個條件。舉例來說,上面的例子裡,除了原本城市為 Chicago 的條件外,若要再增加一個年收入大於400,000的條件,可在下圖的儲存格E2裡輸入下面的語法:
=FILTER(A2:C11, (B2:B11=“Chicago”)*(C2:C11>400000), “”)
這語法指出資料範圍位在儲存格A2到C11,第1個篩選條件為儲存格B2到B11裡名稱為 Chicago 的城市,第2個篩選條件為儲存格C2到C11裡大於400,000的年收入,而且這2個條件須同時成立。此外,當篩選條件的資料不存在時,傳回空白的值。語法輸入完成後,按下 Enter 會傳回如下圖右下的資料。
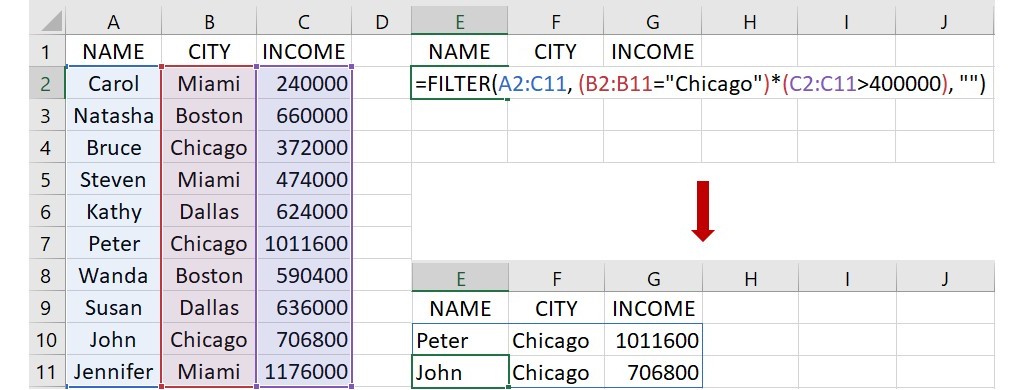
如果2個條件不需要同時成立,而是滿足第1個條件或第2個條件的情況,此時可使用加法符號(+)來連結2個條件。同樣以上面的例子來看,若不只篩選 Chicago 這個城市,也想篩選 Boston 這個城市,可在下圖的儲存格E2輸入下面的語法:
=FILTER(A2:C11, (B2:B11=“Chicago”)+(B2:B11=“Boston”), “”)
這語法指出資料範圍位在儲存格A2到C11,2個篩選條件為儲存格B2到B11裡名稱為 Chicago 或 Boston 的城市,若篩選條件的資料不存在時,傳回空白的值。語法輸入完成後,按下 Enter 會傳回這2個城市的所有相關資料。
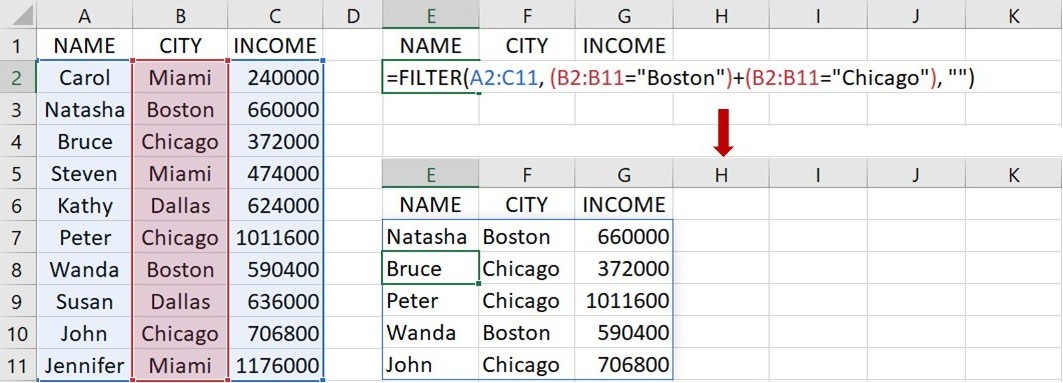
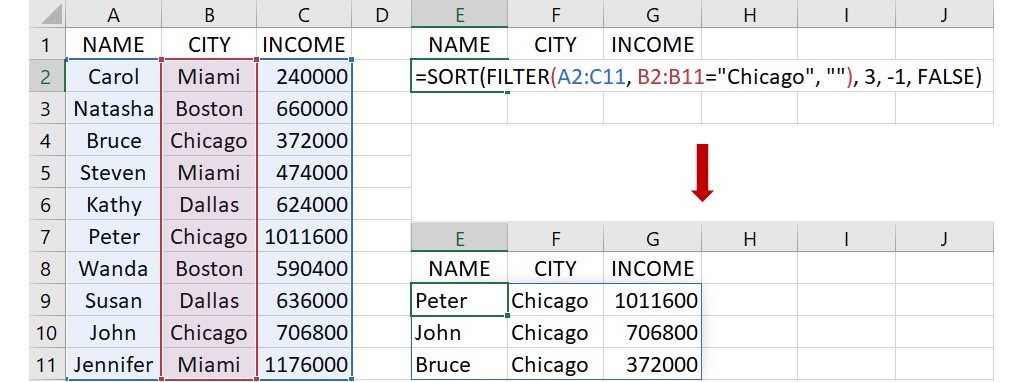
除了單獨使用之外,FILTER 函數也可以和上面介紹的 SORT 函數一起使用。同樣以名字、城市和年收入的資料為例子,如果想先篩選出城市為 Chicago 的資料,再依據年收入的高低進行排序,可在下圖的儲存格E2裡輸入下面的語法:
=SORT(FILTER(A2:C11, B2:B11=“Chicago”, “”), 3, -1, FALSE)
這語法指出從儲存格A2到C11的原始資料先篩選出儲存格B2到B11裡名稱為 Chicago 的城市資料,再以第3欄的年收入為排序標準,依據高年收入到低年收入的順序,按列來排列資料。語法輸入完成後,按下 Enter 後會傳回依據年收入高低排序的 Chicago 城市資料。
從上面的說明可以發現 FILTER 函數是個很實用的函數,而且和 SORT 函數一同使用會讓資料整理變得更有彈性。使用時須注意篩選條件引數(include)裡若有 #N/A、#VALUE 等錯誤值,FILTER 函數便無法正確地執行。此外,若篩選條件陣列裡有篩選值不存在的可能性時,最好自行設定傳回名稱的引數(if_empty),否則系統會傳回 #CALC! 的錯誤訊息。
UNIQUE 函數
如果想要知道一欄的資料(一個變項)裡存在哪些獨特的值,或想篩選出只出現過一次的值,可以使用 UNIQUE 函數。由於 UNIQUE 函數會傳回一個陣列,所以屬於動態陣列公式。這個函數的語法如下:
=UNIQUE(array, [by_col], [exactly_once])
語法裡除了第1個引數外,其餘皆為選擇性的引數,這3個引數的意義分別如下:
- array:欲傳回獨特值的資料範圍,可以是一欄、一列或數欄和數列組成的資料。
- by_col:如何比較的邏輯值,TRUE 為欄和欄的比較,FALSE 為列和列的比較(預設值)。
- exactly_once:傳回只出現一次的值,為一個邏輯值,TRUE 要求傳回僅出現一次的值,FALSE 要求傳回所有出現過的值(預設值)。
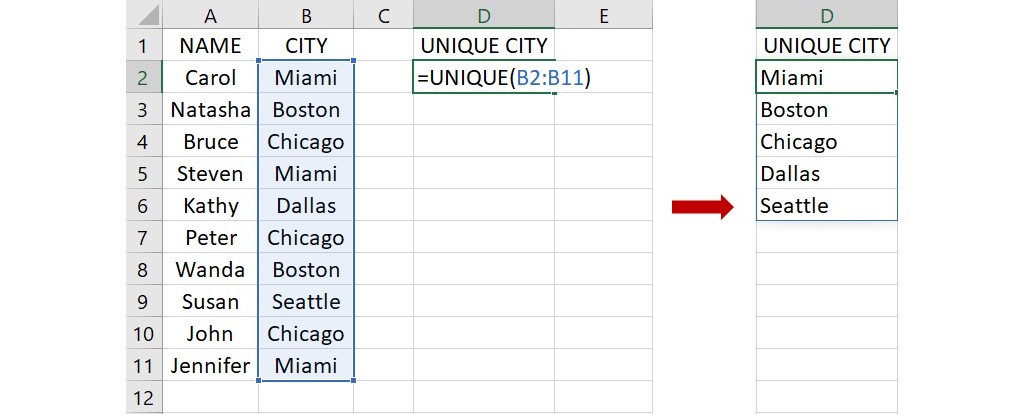
從函數的語法可以看出,若要取得一欄資料的所有出現過的值,只要指明資料的範圍即可。舉例來說,若想知道下圖資料裡所有出現過的城市 CITY 名稱,可在一空白的儲存格(下圖為D2)輸入下面的語法:
=UNIQUE(B2:B11)
這語法指出資料範圍位於儲存格B2到B11,不論出現的次數,要求傳回所有出現過的城市名稱。語法輸入完成後,按下 Enter 會傳回下圖右邊的清單。
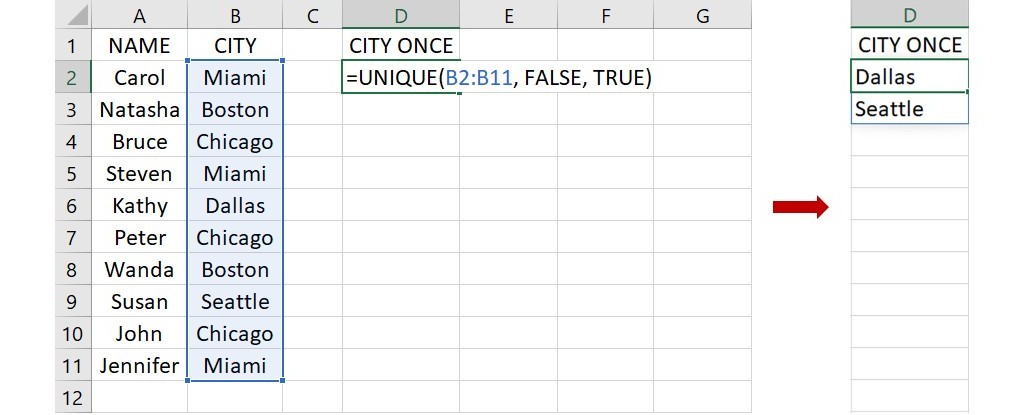
上面的例子僅指出資料的範圍,所以會傳回不論出現次數的所有值,但若只想取得出現一次的值,則可利用第3個引數。同樣使用上面的例子,但想取得只出現一次的城市名稱,可在下圖的儲存格D2裡輸入下面的語法:
=UNIQUE(B2:B11, FALSE, TRUE)
這語法指出資料範圍位在儲存格B2到B11,要求以列和列比較的方式,傳回僅出現一次的城市名稱。語法輸入完成後,按下 Enter 會傳回下圖右邊的清單,可以看到都是只出現過一次的城市。
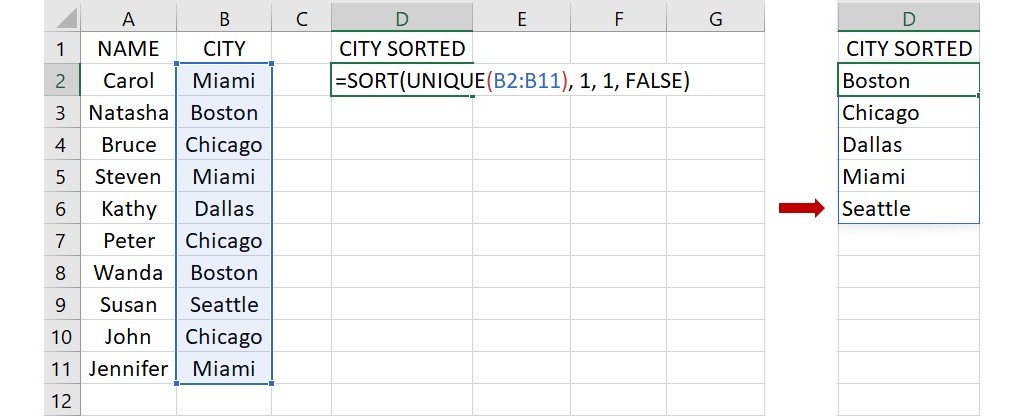
UNIQUE 函數也可以和 SORT 函數一起使用,同樣以上面的城市資料為例,如果想先列出所有出現過的城市名稱再從A至Z排序,可以在下圖的儲存格D2裡輸入下面的任一語法:
① =SORT(UNIQUE(B2:B11), 1, 1, FALSE)
② =SORT(UNIQUE(B2:B11))
第1個語法指出先從儲存格B2到B11列出所有出現過的城市,再依據從小至大(從A至Z)的排序方法來排列這個城市清單。語法輸入完成後,按下 Enter 會傳回下圖右邊的已排序城市清單。
在這個例子裡,除了利用 UNIQUE 函數指明的資料範圍外,SORT 函數語法的第2到第4個引數皆為預設值,所以也可直接使用第2個語法,會和第1個語法得到相同的結果。
總結來說,當利用 Excel 進行資料整理的時候,可以使用 SORT、SORTBY、FILTER 或 UNIQUE 函數來排序或篩選資料,讓資料整理的過程更具彈性。不過這幾個函數是內建在 Microsoft 365、Excel 2021 和之後的版本,若是之前的版本,則可透過功能表的圖形化操作介面來完成。
以上為本篇文章對如何使用 Excel 排序和篩選資料的介紹,希望透過本篇文章,您學會了 SORT、SORTBY、FILTER 和 UNIQUE 函數的使用時機和使用方法。若您喜歡本篇文章,請將本網站加入書籤,並隨時回訪本網站喔!另外,也歡迎您追蹤本網站的 Facebook 和/或 X(Twitter)專頁喲!
如果您覺得本篇文章對您有幫助,歡迎買杯珍奶給 Dr. Fish!小小珍奶,大大鼓勵,您的支持將給 Dr. Fish 更多撰寫優質文章的動力喔!