🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址

資料管理
在工作表裡將一個儲存格的文字分割到數個儲存格的方法有兩種,一種是利用函數,另一種是透過內建的資料剖析精靈。若利用函數,依據欲截取文字所在的位置而牽涉到不同函數的運用,且語法複雜;若利用資料剖析精靈,透過圖形化操作介面即可進行分割,操作上相對地簡單。
魚博士的專業漫談和課後隨筆
🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
在工作表裡將一個儲存格的文字分割到數個儲存格的方法有兩種,一種是利用函數,另一種是透過內建的資料剖析精靈。若利用函數,依據欲截取文字所在的位置而牽涉到不同函數的運用,且語法複雜;若利用資料剖析精靈,透過圖形化操作介面即可進行分割,操作上相對地簡單。
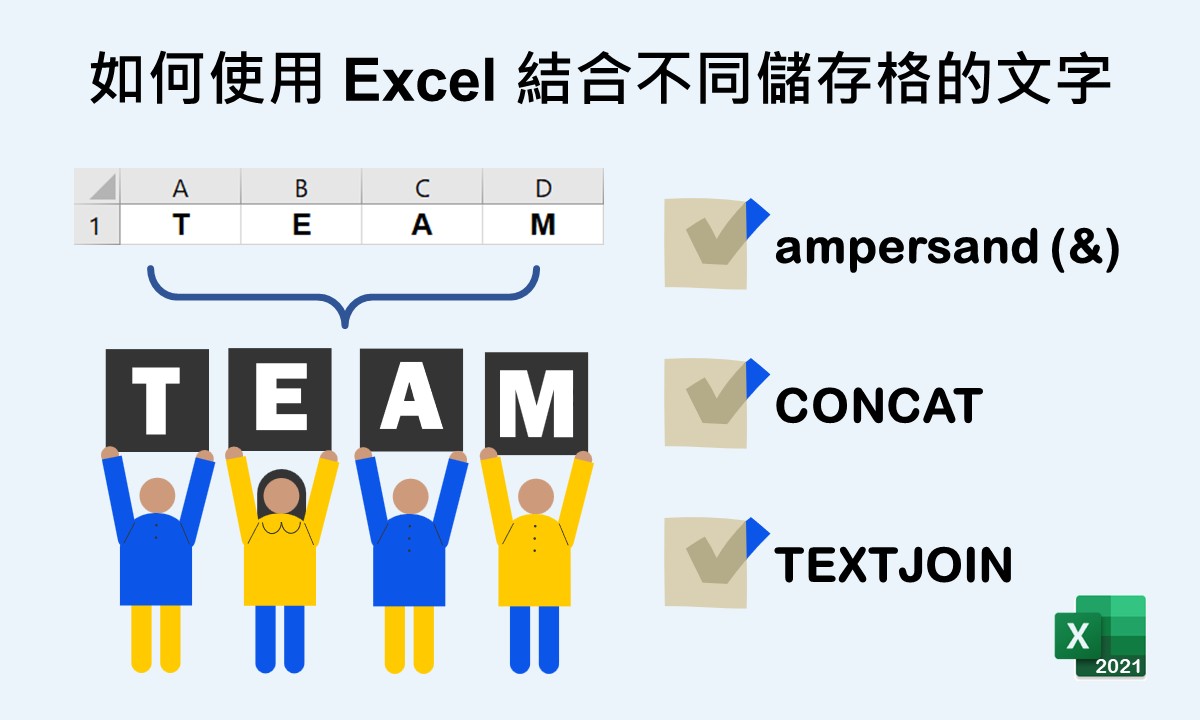
利用微軟的 Excel 整理資料的過程中,若想結合不同儲存格的內容至一個儲存格裡,可透過三種方法來達成。最快速的方法是 & 符號,另兩種則是 CONCAT 和 TEXTJOIN 函數。若結合的資料間要帶有相同的分隔符號或想選擇空白儲存格的顯示方法,TEXTJOIN 函數會是較合適的選擇。
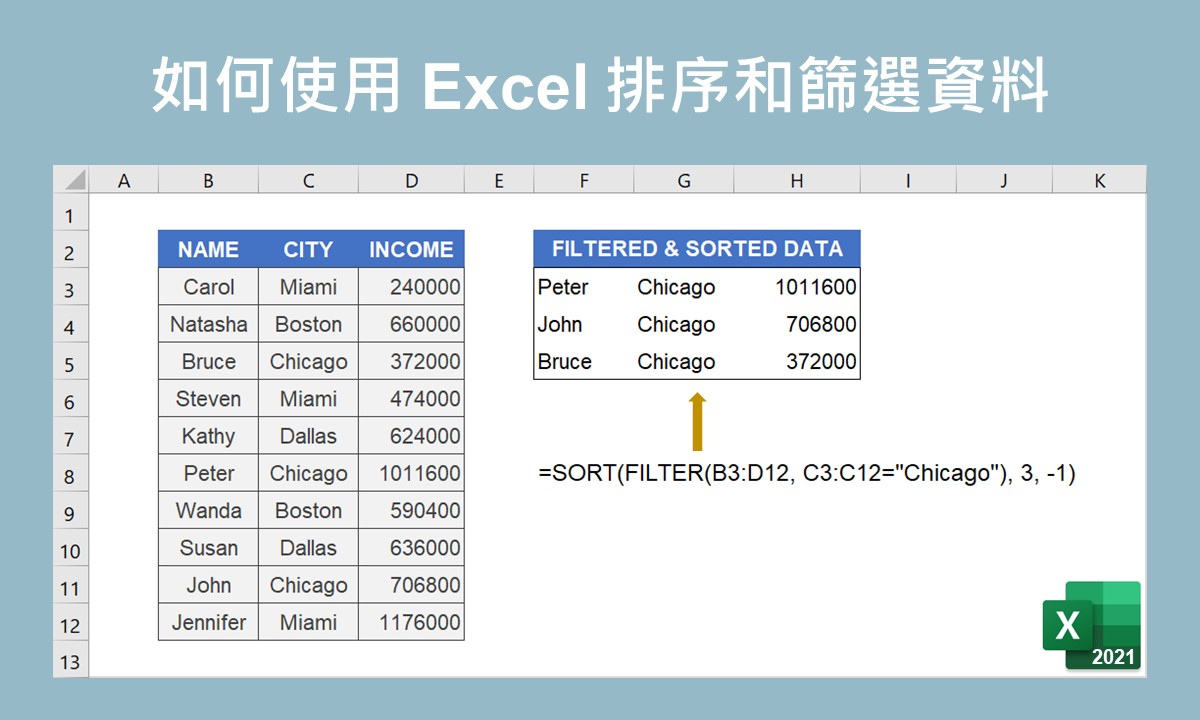
當利用 Excel 進行資料整理的時候,若使用 Microsoft 365、Excel 2021 或之後的版本,可以運用 SORT、SORBY 函數來排序資料,也可以運用 FILTER、UNIQUE 函數來篩選資料。雖然這些函數的使用須撰寫語法,但語法裡各個引數的使用可以讓資料整理的過程更具彈性。
獨立樣本t檢定可用來比較兩個獨立樣本的平均數是否有顯著的不同,當假設檢定結果指出自變項具有效果時,可進一步計算效果量來瞭解自變項效果的大小。此外,信賴區間也相當實用,不但可看出樣本來自的母群體平均數差值可能存在的範圍,也可判斷自變項是否真地存在效果。
關聯樣本t檢定適用在兩個關聯樣本平均數的比較上,當檢定結果達到統計上顯著時,可進一步計算信賴區間和效果量。信賴區間可用來瞭解母群體裡可能包含平均數差值的數值範圍,而效果量則可用來瞭解自變項效果的大小。不論是信賴區間或效果量,皆可運用 SPSS 簡單地取得。