🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
推論統計
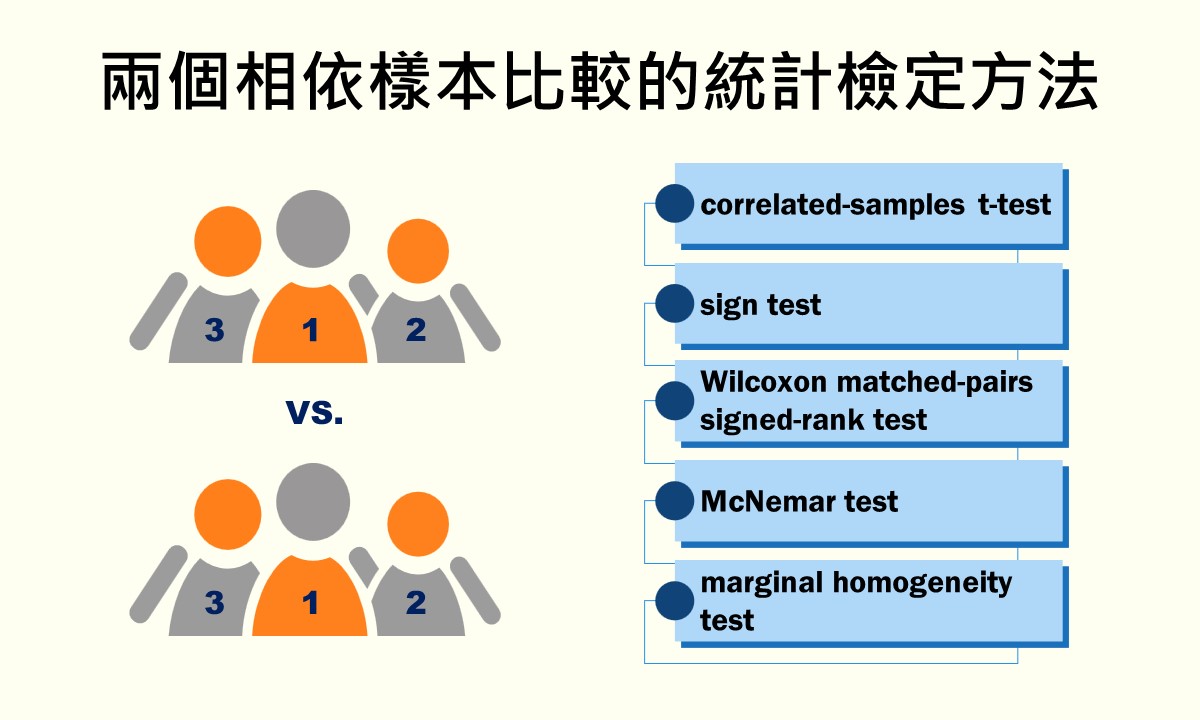
相依樣本是2個群組使用相同或配對參與者的一種研究設計,樣本間具有關聯性。當要比較2個相依樣本時,通常會依據依變項的測量尺度來選擇統計檢定方法,包括母數檢定的關聯樣本t檢定和無母數檢定的符號檢定、Wilcoxon配對符號等級檢定、McNemar檢定和邊際同質性檢定。
魚博士的專業漫談和課後隨筆
🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
相依樣本是2個群組使用相同或配對參與者的一種研究設計,樣本間具有關聯性。當要比較2個相依樣本時,通常會依據依變項的測量尺度來選擇統計檢定方法,包括母數檢定的關聯樣本t檢定和無母數檢定的符號檢定、Wilcoxon配對符號等級檢定、McNemar檢定和邊際同質性檢定。
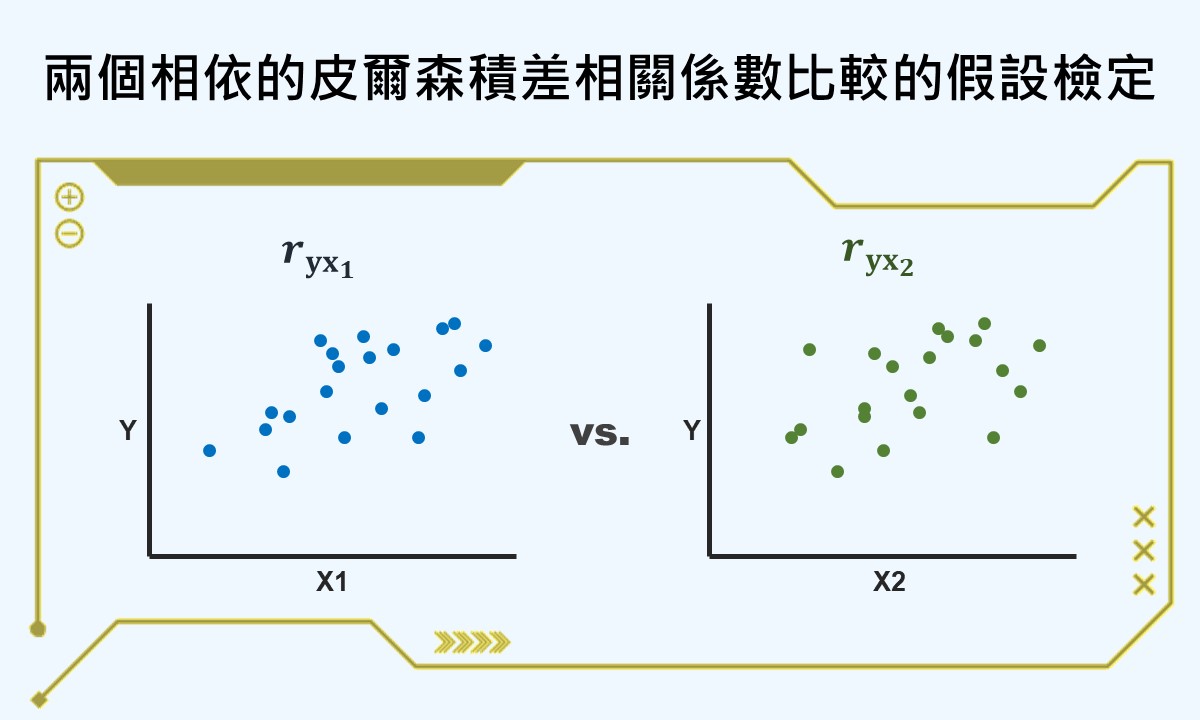
當同一個樣本裡有兩個皮爾森積差相關係數,且這兩個相關係數帶有共同的變項,則這兩個相關係數不是彼此獨立,而是相互關聯的情況。此時,若想比較這兩個皮爾森積差相關係數是否明顯不同,須進行兩個相依的皮爾森積差相關係數的假設檢定,使用t分配和t檢定統計量。
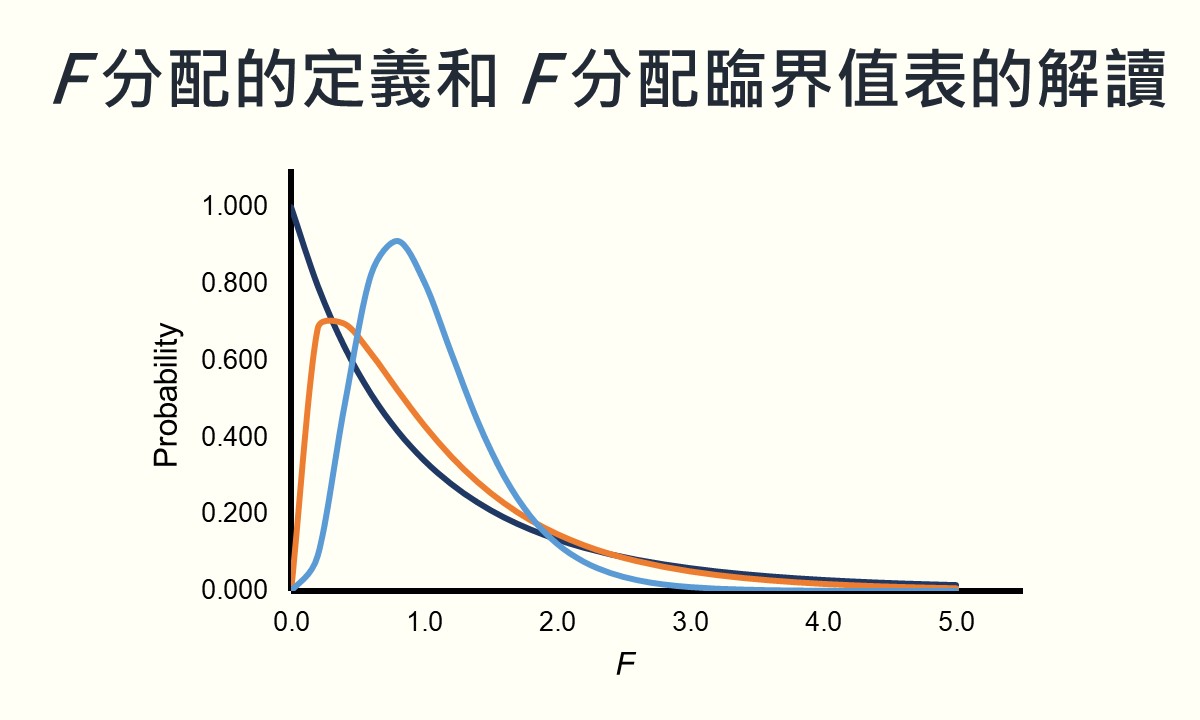
F分配是社會統計裡常見的抽樣分配之一,指從一母群體中隨機抽取出來的兩個獨立樣本的變異數比之抽樣分配。F分配會受到兩個自由度數值的影響,隨著自由度的不同組合而有不同的形狀。若要使用F分配執行假設檢定,須使用F分配臨界值表去找F臨界值,才能評估是否拒絕虛無假設。
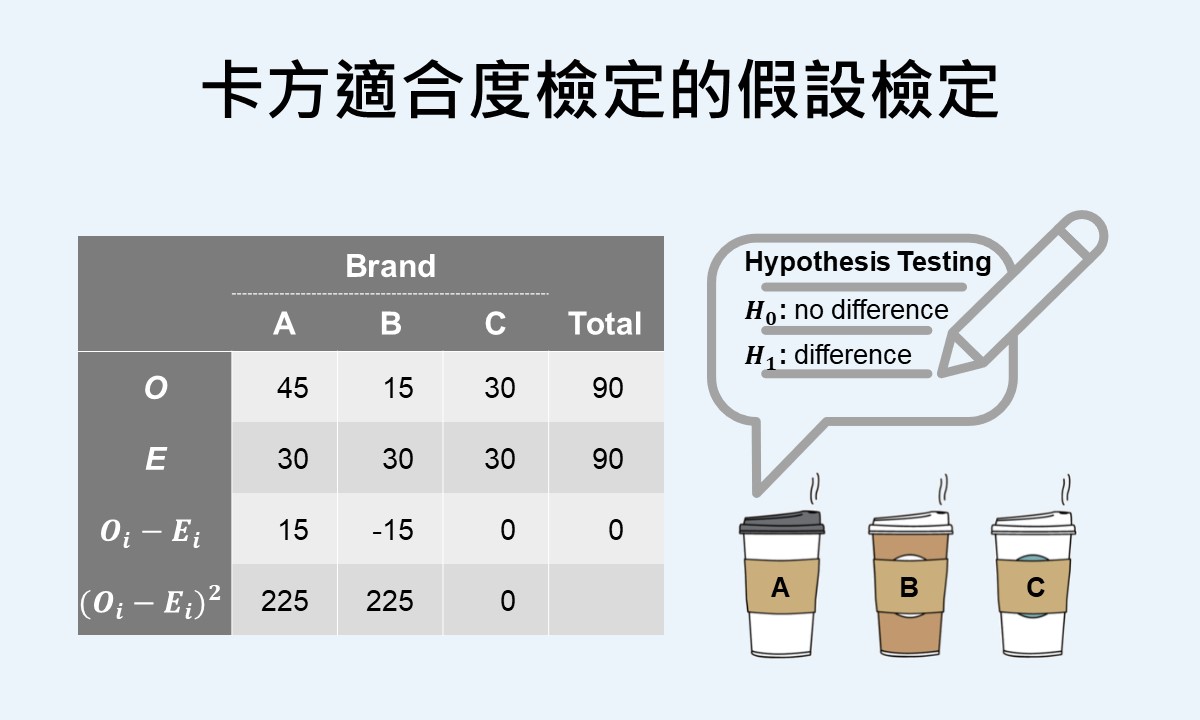
卡方適合度檢定為卡方檢定的一種,是一種沒有方向性、綜合的檢定方法,適用在類別變項或名義尺度的變項資料上,用來評估互斥類別間的觀察次數模式是否明顯不同於期望次數。卡方適合度檢定的假設檢定使用卡方分配和卡方檢定統計量,檢驗觀察和期望次數模式相同的虛無假設。
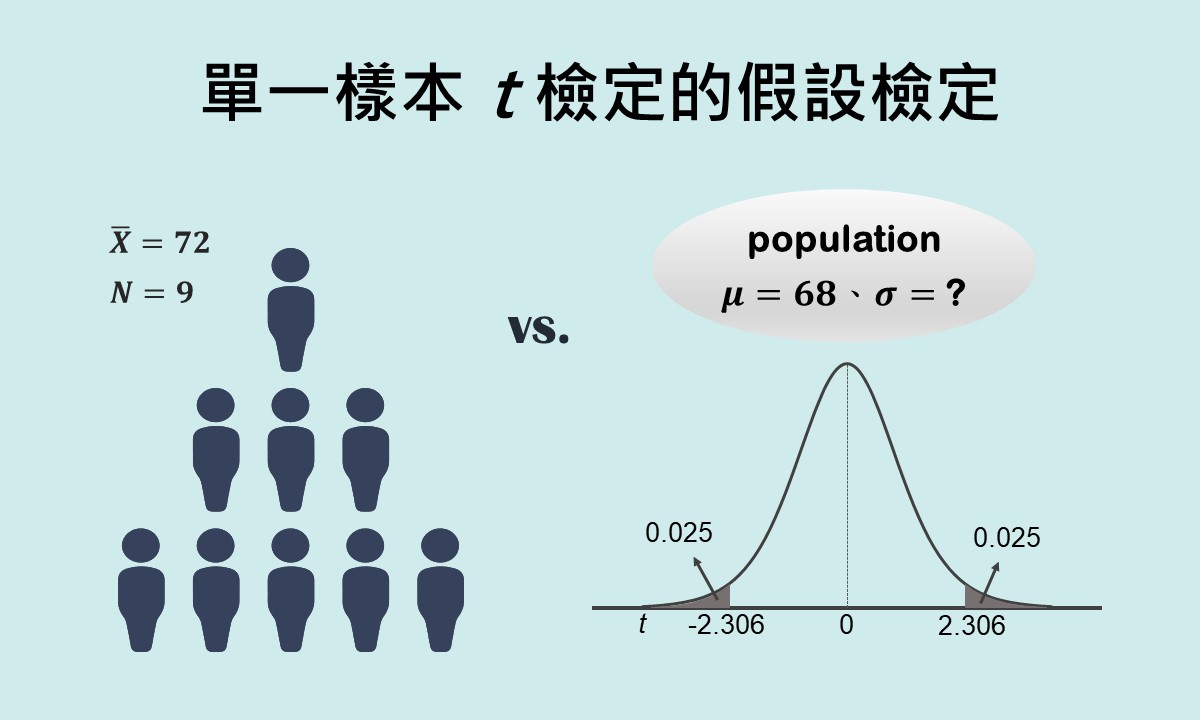
單一樣本t檢定的假設檢定和單一樣本z檢定相當類似,皆用來檢驗一個樣本平均數是否來自於特定母群體的虛無假設,兩者差別在於單一樣本t檢定用在母群體標準差未知或樣本數小於30的情況。單一樣本t檢定使用t抽樣分配和t檢定統計量,可簡單地利用SPSS來獲得分析結果。