🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
推論統計
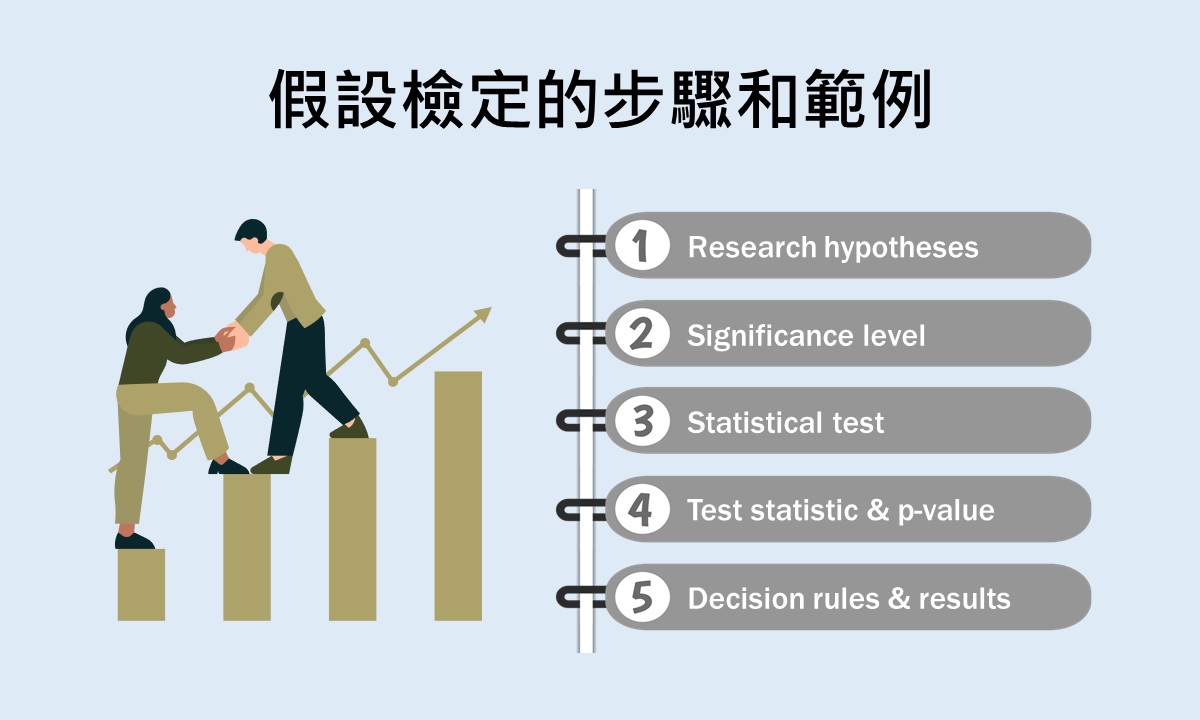
假設檢定是運用統計模型來檢驗研究問題的方式,也是用來測試研究人員操縱的變項是否具有效果的統計推論方法,是推論統計中最核心的部分。假設檢定的過程包含研究假設的提出、顯著水準的設定、統計檢定方法的選擇、檢定統計量和相關機率的計算與決策規則的運用等5個步驟。
魚博士的專業漫談和課後隨筆
🐟 請您尊重本網站的智慧財產權,如有任何引用,請註明出處:Dr. Fish 漫游社會統計。(文章發表日期)。文章名稱。文章網址
假設檢定是運用統計模型來檢驗研究問題的方式,也是用來測試研究人員操縱的變項是否具有效果的統計推論方法,是推論統計中最核心的部分。假設檢定的過程包含研究假設的提出、顯著水準的設定、統計檢定方法的選擇、檢定統計量和相關機率的計算與決策規則的運用等5個步驟。
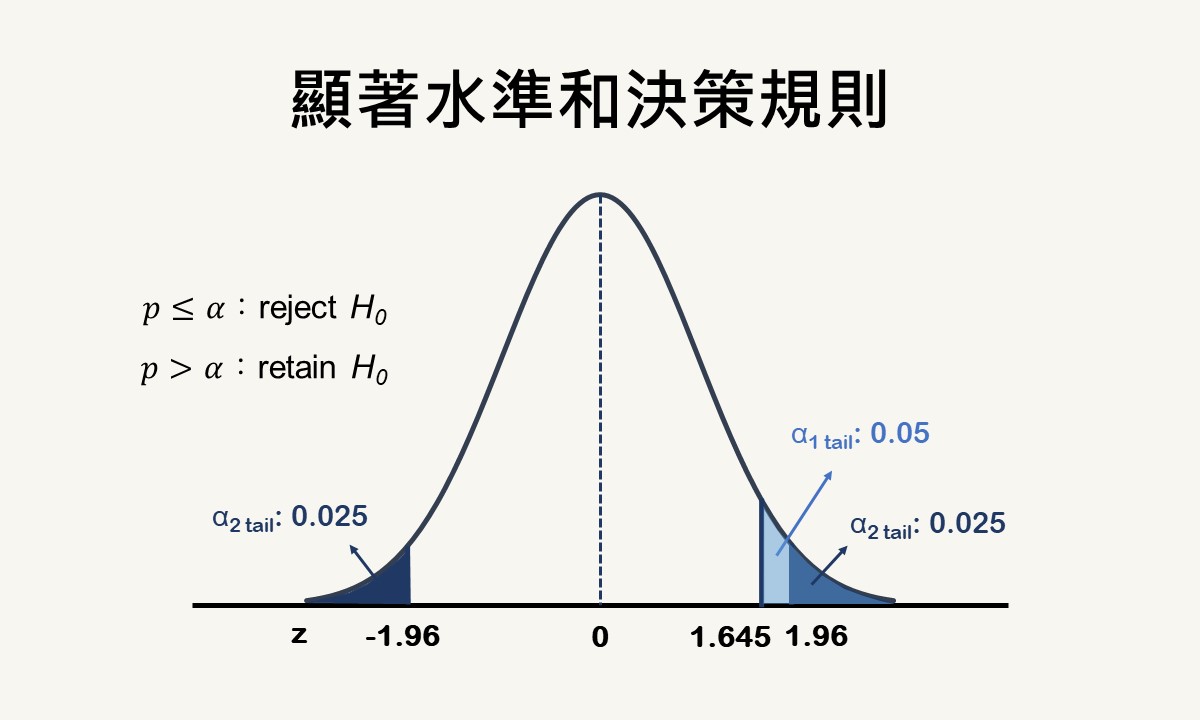
第一類型錯誤指研究人員相信自變項帶有效果,但實際上沒有效果,該錯誤的機率一般為0.05,通常用符號α來表示。第二類型錯誤指研究人員相信自變項沒有效果,但實際上帶有效果,可被接受的最大機率為0.2,通常用符號β來表示。這兩種錯誤間並非彼此獨立,而是相互消長的關係。
檢定統計量是從樣本資料計算出來,用來評估拒絕或保留虛無假設的一個數值。概念上,檢定統計量為統計模型可解釋的變異對無法解釋的變異之比率。若數值愈大,代表結果愈不可能因為機遇而產生,所以發生的機率愈小,若小於顯著水準,即為顯著的檢定統計量,可拒絕虛無假設。
來自北海道的「拉麵次郎長」拉麵,位於台中麗寶Outlet Mall的三樓美食街。湯底由三種味噌製成,帶有中華料理快炒的油滷口感,湯頭濃郁卻鹹度剛好,麵條軟硬適中。雖然叉燒肉的油脂較豐富,但炙燒過的香氣讓整碗拉麵的口感十足。雖然位於賣場的美食街,卻值得品嘗看看。
顯著水準是研究人員在資料蒐集前已決定好,用來和數據分析結果的機率值相比較的一個機率值,也是研究人員願意接受第一類型錯誤的機率值,最常使用的數值為0.05、0.01或0.001。當分析結果的機率值等於或小於顯著水準,可拒絕虛無假設;若大於顯著水準,則保留虛無假設。